The Google Nexus 9 Review
by Joshua Ho & Ryan Smith on February 4, 2015 8:00 AM EST- Posted in
- Tablets
- HTC
- Project Denver
- Android
- Mobile
- NVIDIA
- Nexus 9
- Lollipop
- Android 5.0
The Secret of Denver: Binary Translation & Code Optimization
As we alluded to earlier, NVIDIA’s decision to forgo a traditional out-of-order design for Denver means that much of Denver’s potential is contained in its software rather than its hardware. The underlying chip itself, though by no means simple, is at its core a very large in-order processor. So it falls to the software stack to make Denver sing.
Accomplishing this task is NVIDIA’s dynamic code optimizer (DCO). The purpose of the DCO is to accomplish two tasks: to translate ARM code to Denver’s native format, and to optimize this code to make it run better on Denver. With no out-of-order hardware on Denver, it is the DCO’s task to find instruction level parallelism within a thread to fill Denver’s many execution units, and to reorder instructions around potential stalls, something that is no simple task.
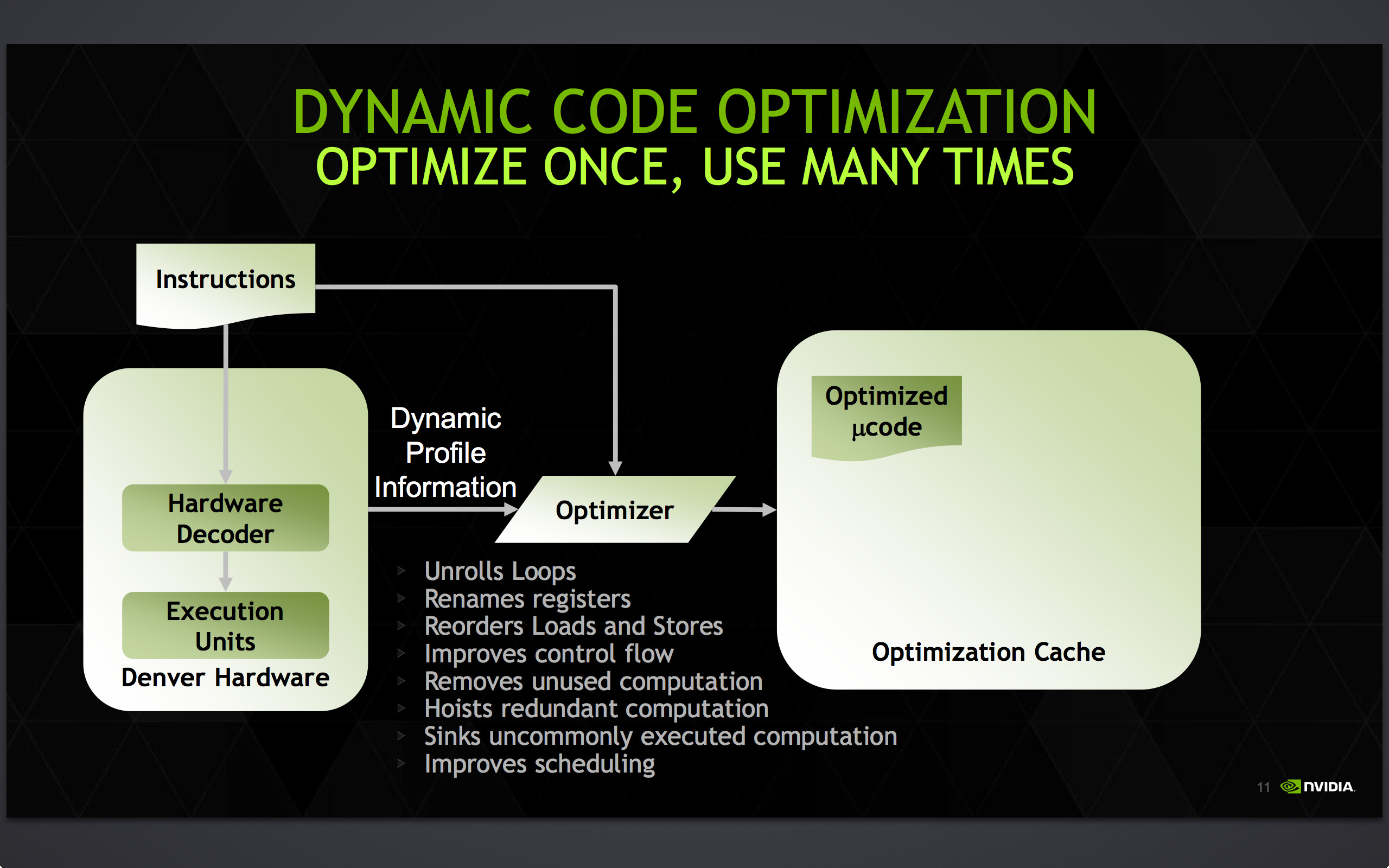
Starting first with the binary translation aspects of DCO, the binary translator is not used for all code. All code goes through the ARM decoder units at least once before, and only after Denver realizes it has run the same code segments enough times does that code get kicked to the translator. Running code translation and optimization is itself a software task, and as a result this task requires a certain amount of real time, CPU time, and power. This means that it only makes sense to send code out for translation and optimization if it’s recurring, even if taking the ARM decoder path fails to exploit much in the way of Denver’s capabilities.
This sets up some very clear best and worst case scenarios for Denver. In the best case scenario Denver is entirely running code that has already been through the DCO, meaning it’s being fed the best code possible and isn’t having to run suboptimal code from the ARM decoder or spending resources invoking the optimizer. On the other hand then, the worst case scenario for Denver is whenever code doesn’t recur. Non-recurring code means that the optimizer is never getting used because that code is never seen again, and invoking the DCO would be pointless as the benefits of optimizing the code are outweighed by the costs of that optimization.
Assuming that a code segment recurs enough to justify translation, it is then kicked over to the DCO to receive translation and optimization. Because this itself is a software process, the DCO is a critical component due to both the code it generates and the code it itself is built from. The DCO needs to be highly tuned so that Denver isn’t spending more resources than it needs to in order to run the DCO, and it needs to produce highly optimal code for Denver to ensure the chip achieves maximum performance. This becomes a very interesting balancing act for NVIDIA, as a longer examination of code segments could potentially produce even better code, but it would increase the costs of running the DCO.
In the optimization step NVIDIA undertakes a number of actions to improve code performance. This includes out-of-order optimizations such as instruction and load/store reordering, along register renaming. However the DCO also behaves as a traditional compiler would, undertaking actions such as unrolling loops and eliminating redundant/dead code that never gets executed. For NVIDIA this optimization step is the most critical aspect of Denver, as its performance will live and die by the DCO.
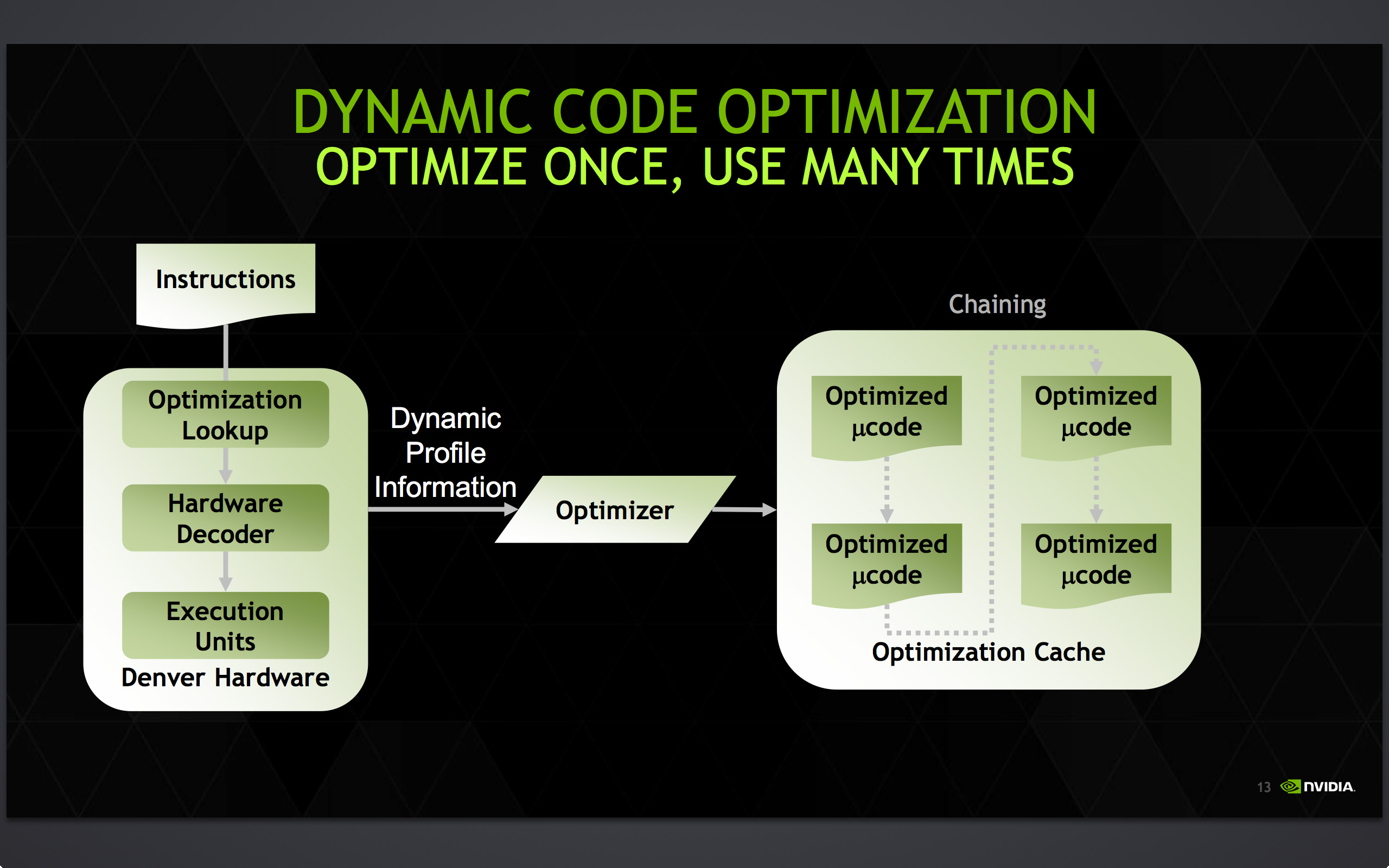
Denver's optimization cache: optimized code can call other optimized code for even better performance
Once code leaves the DCO, it is then stored for future use in an area NVIDIA calls the optimization cache. The cache is a 128MB segment of main memory reserved to hold these translated and optimized code segments for future reuse, with Denver banking on its ability to reuse code to achieve its peak performance. The presence of the optimization cache does mean that Denver suffers a slight memory capacity penalty compared to other SoCs, which in the case of the N9 means that 1/16th (6%) of the N9’s memory is reserved for the cache. Meanwhile, also resident here is the DCO code itself, which is shipped and stored as already-optimized code so that it can achieve its full performance right off the bat.
Overall the DCO ends up being interesting for a number of reasons, not the least of which are the tradeoffs are made by its inclusion. The DCO instruction window is larger than any comparable OoOE engine, meaning NVIDIA can look at larger code blocks than hardware OoOE reorder engines and potentially extract even better ILP and other optimizations from the code. On the other hand the DCO can only work on code in advance, denying it the ability to see and work on code in real-time as it’s executing like a hardware out-of-order implementation. In such cases, even with a smaller window to work with a hardware OoOE implementation could produce better results, particularly in avoiding memory stalls.
As Denver lives and dies by its optimizer, it puts NVIDIA in an interesting position once again owing to their GPU heritage. Much of the above is true for GPUs as well as it is Denver, and while it’s by no means a perfect overlap it does mean that NVIDIA comes into this with a great deal of experience in optimizing code for an in-order processor. NVIDIA faces a major uphill battle here – hardware OoOE has proven itself reliable time and time again, especially compared to projects banking on superior compilers – so having that compiler background is incredibly important for NVIDIA.
In the meantime because NVIDIA relies on a software optimizer, Denver’s code optimization routine itself has one last advantage over hardware: upgradability. NVIDIA retains the ability to upgrade the DCO itself, potentially deploying new versions of the DCO farther down the line if improvements are made. In principle a DCO upgrade not a feature you want to find yourself needing to use – ideally Denver’s optimizer would be perfect from the start – but it’s none the less a good feature to have for the imperfect real world.
Case in point, we have encountered a floating point bug in Denver that has been traced back to the DCO, which under exceptional workloads causes Denver to overflow an internal register and trigger an SoC reset. Though this bug doesn’t lead to reliability problems in real world usage, it’s exactly the kind of issue that makes DCO updates valuable for NVIDIA as it gives them an opportunity to fix the bug. However at the same time NVIDIA has yet to take advantage of this opportunity, and as of the latest version of Android for the Nexus 9 it seems that this issue still occurs. So it remains to be seen if BSP updates will include DCO updates to improve performance and remove such bugs.








169 Comments
View All Comments
UtilityMax - Sunday, February 15, 2015 - link
I don't fully understand you comment about the SoC? You think web browser is using the hardware somewhat differently from the dedicated apps?My comment is about the fact that there is not point to have most of the dedicated apps when you have a tablet with a screen the size of a small laptop or netbook. Just fire up the web browser and use whatever web site you need. Most dedicated mobile apps exist because the screen size of a cell phone is pretty small, which can make for an awkward experience even when you pull a mobile web site though a web browser.
UtilityMax - Sunday, February 8, 2015 - link
It's not entirely true that there isn't much in the tablet space, besides Nexus 9 and Galaxy Tab S. If your pockets are deep enough, you could always get the Apple iPad Air 2. Apple gives you a well balanced tablet with great build quality, fine screen, CPU/GPU performance, and battery life. The only thing that's missing is an SD card slot, but at least there is an option a 64 or 128GB model. Personally, I ended buying a Tab S 10.5 because it was truly difficult to resist it at only $400 sale price, plus $35 for a 64GB SD card. Despite all the disappointing benchmarks, Tab S provides a pretty smooth and fluid android experience with a great screen. Battery life is the only thing that's getting on the way. Five hours of web browsing or standby is pretty disappointing.wintermute000 - Monday, February 9, 2015 - link
Sony Xperia Tablet Z2. SoC is one gen behind but if you can get it for a good price, you're laughing. Fantastic build, clean stock software, lag free.sunil5228 - Sunday, February 8, 2015 - link
Brilliant ! Esp loved the segway into the Denver CPU and dual vs quad arcitechture comparisons,very eye opening. thankyou sirbdiddytampa - Wednesday, February 11, 2015 - link
Picked one of these up a couple weeks ago and love it. It performs phenomenally well, and looks great. It's a bit heavy for its size and the thin bezel on the sides makes it difficult to hold with one hand without touching the screen, but overall its a fantastic tablet. Highly recommend it.Ozo - Monday, February 16, 2015 - link
Thanks for the lucid explanation of Denver.Any insight into why Google/HTC dropped the ball on "wireless" Qi charging? Especially when it was finally added to the Nexus phone!?!
I was set to upgrade from my Nexus 7 (2013), but no Qi = no sale. :(
Fardreit - Monday, February 23, 2015 - link
I'll be honest: I don't understand 80% of what the reviewer wrote. But the 20% that I do understand is enough for me to appreciate the conclusions drawn. I value the informed reviews here much more than those at the 'fan' websites. At Anandtech, people really know what they're talking about, even if I don't.When I'm able to follow the high-tech insults you guys sling at each other, then I know I've made progress.
flashbacck - Wednesday, February 25, 2015 - link
Does the Shield Tablet use a similar DCO? I have noticed during it has performance issues during regular use. I wonder if it's this DCO that still needs work.ahcox - Thursday, February 25, 2016 - link
What is the accuracy of the image labelled "K1-64 Die Shot Mock-up"? Is it a colorized and enhanced version of a real die photograph or is it a pure invention? That 16 * 12 array dominating the picture seems a little off to me: surely there should be structures common to each 16*2 group forming an SMX? Kepler is not a simple tiled sea of cores.