The Google Nexus 9 Review
by Joshua Ho & Ryan Smith on February 4, 2015 8:00 AM EST- Posted in
- Tablets
- HTC
- Project Denver
- Android
- Mobile
- NVIDIA
- Nexus 9
- Lollipop
- Android 5.0
The Secret of Denver: Binary Translation & Code Optimization
As we alluded to earlier, NVIDIA’s decision to forgo a traditional out-of-order design for Denver means that much of Denver’s potential is contained in its software rather than its hardware. The underlying chip itself, though by no means simple, is at its core a very large in-order processor. So it falls to the software stack to make Denver sing.
Accomplishing this task is NVIDIA’s dynamic code optimizer (DCO). The purpose of the DCO is to accomplish two tasks: to translate ARM code to Denver’s native format, and to optimize this code to make it run better on Denver. With no out-of-order hardware on Denver, it is the DCO’s task to find instruction level parallelism within a thread to fill Denver’s many execution units, and to reorder instructions around potential stalls, something that is no simple task.
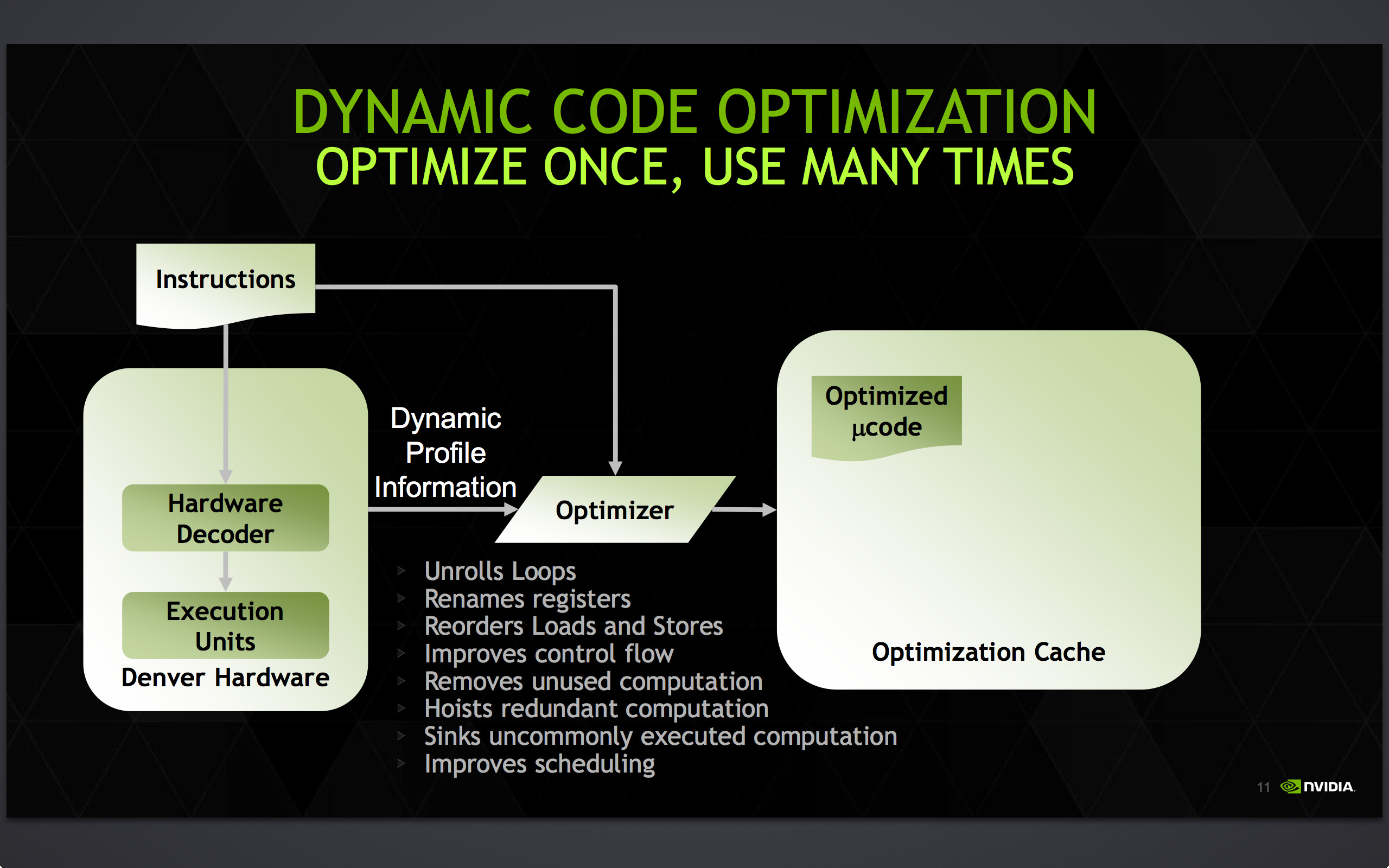
Starting first with the binary translation aspects of DCO, the binary translator is not used for all code. All code goes through the ARM decoder units at least once before, and only after Denver realizes it has run the same code segments enough times does that code get kicked to the translator. Running code translation and optimization is itself a software task, and as a result this task requires a certain amount of real time, CPU time, and power. This means that it only makes sense to send code out for translation and optimization if it’s recurring, even if taking the ARM decoder path fails to exploit much in the way of Denver’s capabilities.
This sets up some very clear best and worst case scenarios for Denver. In the best case scenario Denver is entirely running code that has already been through the DCO, meaning it’s being fed the best code possible and isn’t having to run suboptimal code from the ARM decoder or spending resources invoking the optimizer. On the other hand then, the worst case scenario for Denver is whenever code doesn’t recur. Non-recurring code means that the optimizer is never getting used because that code is never seen again, and invoking the DCO would be pointless as the benefits of optimizing the code are outweighed by the costs of that optimization.
Assuming that a code segment recurs enough to justify translation, it is then kicked over to the DCO to receive translation and optimization. Because this itself is a software process, the DCO is a critical component due to both the code it generates and the code it itself is built from. The DCO needs to be highly tuned so that Denver isn’t spending more resources than it needs to in order to run the DCO, and it needs to produce highly optimal code for Denver to ensure the chip achieves maximum performance. This becomes a very interesting balancing act for NVIDIA, as a longer examination of code segments could potentially produce even better code, but it would increase the costs of running the DCO.
In the optimization step NVIDIA undertakes a number of actions to improve code performance. This includes out-of-order optimizations such as instruction and load/store reordering, along register renaming. However the DCO also behaves as a traditional compiler would, undertaking actions such as unrolling loops and eliminating redundant/dead code that never gets executed. For NVIDIA this optimization step is the most critical aspect of Denver, as its performance will live and die by the DCO.
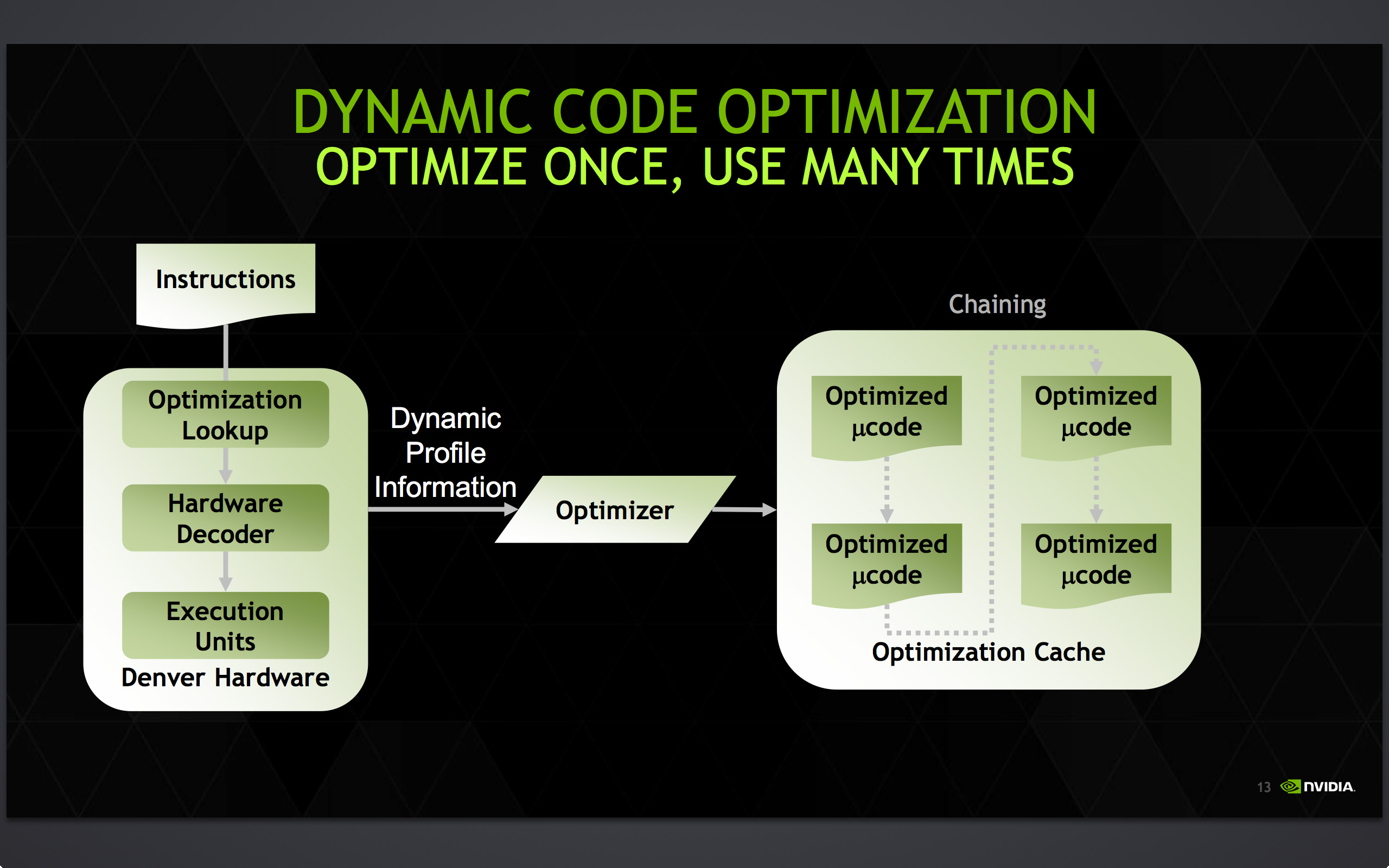
Denver's optimization cache: optimized code can call other optimized code for even better performance
Once code leaves the DCO, it is then stored for future use in an area NVIDIA calls the optimization cache. The cache is a 128MB segment of main memory reserved to hold these translated and optimized code segments for future reuse, with Denver banking on its ability to reuse code to achieve its peak performance. The presence of the optimization cache does mean that Denver suffers a slight memory capacity penalty compared to other SoCs, which in the case of the N9 means that 1/16th (6%) of the N9’s memory is reserved for the cache. Meanwhile, also resident here is the DCO code itself, which is shipped and stored as already-optimized code so that it can achieve its full performance right off the bat.
Overall the DCO ends up being interesting for a number of reasons, not the least of which are the tradeoffs are made by its inclusion. The DCO instruction window is larger than any comparable OoOE engine, meaning NVIDIA can look at larger code blocks than hardware OoOE reorder engines and potentially extract even better ILP and other optimizations from the code. On the other hand the DCO can only work on code in advance, denying it the ability to see and work on code in real-time as it’s executing like a hardware out-of-order implementation. In such cases, even with a smaller window to work with a hardware OoOE implementation could produce better results, particularly in avoiding memory stalls.
As Denver lives and dies by its optimizer, it puts NVIDIA in an interesting position once again owing to their GPU heritage. Much of the above is true for GPUs as well as it is Denver, and while it’s by no means a perfect overlap it does mean that NVIDIA comes into this with a great deal of experience in optimizing code for an in-order processor. NVIDIA faces a major uphill battle here – hardware OoOE has proven itself reliable time and time again, especially compared to projects banking on superior compilers – so having that compiler background is incredibly important for NVIDIA.
In the meantime because NVIDIA relies on a software optimizer, Denver’s code optimization routine itself has one last advantage over hardware: upgradability. NVIDIA retains the ability to upgrade the DCO itself, potentially deploying new versions of the DCO farther down the line if improvements are made. In principle a DCO upgrade not a feature you want to find yourself needing to use – ideally Denver’s optimizer would be perfect from the start – but it’s none the less a good feature to have for the imperfect real world.
Case in point, we have encountered a floating point bug in Denver that has been traced back to the DCO, which under exceptional workloads causes Denver to overflow an internal register and trigger an SoC reset. Though this bug doesn’t lead to reliability problems in real world usage, it’s exactly the kind of issue that makes DCO updates valuable for NVIDIA as it gives them an opportunity to fix the bug. However at the same time NVIDIA has yet to take advantage of this opportunity, and as of the latest version of Android for the Nexus 9 it seems that this issue still occurs. So it remains to be seen if BSP updates will include DCO updates to improve performance and remove such bugs.








169 Comments
View All Comments
dtgoodwin - Wednesday, February 4, 2015 - link
I really appreciate the depth that this article has, however, I wonder if it would have been better to separate the in depth CPU analysis for a separate article. I will probably never remember to come back to the Nexus 9 review if I want to remember a specific detail about that CPU.nevertell - Wednesday, February 4, 2015 - link
Has nVidia exposed that they would provide a static version of the DCO so that app developers would be able to optimize their binaries at compile time ? Or do these optimizations rely on the program state when they are being executed ? From a pure academic point of view, it would be interesting to see the overhead introduced by the DCO when comparing previously optimized code without the DCO running and running the SoC as was intended.Impulses - Wednesday, February 4, 2015 - link
Nice in depth review as always, came a little late for me (I purchased one to gift it, which I ironically haven't done since the birthday is this month) but didn't really change much as far as my decision so it's all good...I think the last remark nails it, had the price point being just a little lower most of the minor QC issues wouldn't have been blown up...
I don't know if $300 for 16GB was feasible (pretty much the price point of the smaller Shield), but $350 certainly was and Amazon was selling it for that much all thru Nov-Dec which is bizarre since Google never discounted it themselves.
I think they should've just done a single $350-400 32GB SKU, saved themselves a lot of trouble and people would've applauded the move (and probably whined for a 64GB but you can't please everyone). Or a combo deal with the keyboard, which HTC was selling at 50% at one point anyway.
Impulses - Wednesday, February 4, 2015 - link
No keyboard review btw?JoshHo - Thursday, February 5, 2015 - link
We did not receive the keyboard folio for review.treecats - Wednesday, February 4, 2015 - link
Where is the comparison to NEXUS 10????Maybe because Nexus 10's battery life is crap after 1 year of use!!!
Please come back review it again when you used it for a year.
treecats - Wednesday, February 4, 2015 - link
My previously holds true for all the Nexus device line I own.I had Nexus 4,
currently have Nexus 5, and Nexus 10. All the Nexus devices I own have bad battery life after 1 year of use.
Google, fix the battery problem.
blzd - Friday, February 6, 2015 - link
That tells me you are mistreating your batteries. You think it's coincidence that it's happening to all your devices? Do you know how easy it is for batteries to degrade when over heating? Do you know every battery is rated for a certain number of charges only?Mostly you want to avoid heat, especially while charging. Gaming while charging? That's killing the battery. GPS navigation while charging? Again, degrading the battery.
Each time you discharge and charge the battery you are using one of it's charge cycles. So if you use the device a lot and charge it multiple times a day you will notice degradation after a year. This is not unique to Google devices.
grave00 - Sunday, February 8, 2015 - link
I don't think you have the latest info on how battery charging vs battery life works.hstewartanand - Wednesday, February 4, 2015 - link
Even though I personal have 6 tablets ( 2 iPads, 2 Windows 8.1 and 2 android ) and as developer I find them technically inferior to Actual PC - except for Windows 8.1 Surface Pro.I recently purchase an Lenovo y50 with i7 4700 - because I desired AVX 2 video processing. To me ARM based platforms will never replace PC devices for certain applications - like Video processing and 3d graphics work.
I am big fan of Nvidia GPU's but don't care much for ARM cpus - I do like the completion that it given to Intel to produce low power CPU's for this market
What I really like to see is a true technical bench mark that compare the true power of cpus from ARM and Intel and rank them. This includes using extended instructions like AVX 2 on Intel cpus.
Compared this with equivalent configured Nvidia GPU on Intel CPU - and I would say ARM has a very long way to go.
But a lot depends on what you doing with the device. I am currently typing this on a 4+ year old Macbook Air - because it easy to do it and convenient. My other Windows 8.1 ( Lenovo 2 Mix 8 - Intel Adam Baytrail ) has roughly the same speed - but Macbook AIR is more convenient. My primary tablet is the Apple Mini with Retina screen, it is also convent for email and amazon and small stuff.
The problem with some of bench marks - is that they maybe optimized for one platform more than another and dependent on OS components which may very between OS environments. So ideal the tests need to native compile for cpu / gpu combination and take advantage of hardware. I don't believe such a benchmark exists. Probably the best way to do this get developers interested in platforms to come up with contest for best score and have code open source - so no cheating. It would be interesting to see ranking of machines from tablets, phones, laptop and even high performance xeon machines. I also have an 8+ Year old dual Xeon 5160 Nvidia GTX 640 (best I can get on this old machine ) and I would bet it will blow away any of this ARM based tablets. Performance wise it a little less but close to my Lenovo y50 - if not doing VIDEO processing because of AVX 2 is such significant improvement.
In summary it really hard to compare performance of ARM vs Intel machines. But this review had some technical information that brought me back to my older days when writing assembly code on OS - PC-MOS/386