The iPhone 6 Review
by Joshua Ho, Brandon Chester, Chris Heinonen & Ryan Smith on September 30, 2014 8:01 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 6
A8: Apple’s First 20nm SoC
As has been customary for every iPhone launch since the company began publicly naming their SoCs, Apple has once again rolled out a new SoC for their latest line of phones. With the launch of the iPhone 6 series Apple is now up to their eight generation SoC, the appropriately named A8.
After a period of rapid change with the A6 and A7 SoCs – which introduced Apple’s first custom CPU design (Swift) and the first ARMv8 AArch64 design (Cyclone) respectively – A8 is a more structured and straightforward evolution of Apple’s SoC designs. Which is not to say that Apple hasn’t been busy tweaking their designs to extract ever-improved performance and power efficiency, as we’ll see, but our examination of A8 has not uncovered the same kind of radical changes that defined A6 and A7.

The heart and soul of A8 is as always the CPU and GPU. We’ll be taking a look at each of these individually in a moment, but from a high level both of these are evolutions of their predecessors found in A7. Apple’s GPU of choice remains Imagination’s PowerVR, having upgraded from the Series6 based G6430 to Imagination’s newer GX6450 design. Meanwhile Apple continues to develop their own CPUs and A8 packs their latest design, which is an enhanced version of the Cyclone core first introduced in A7.
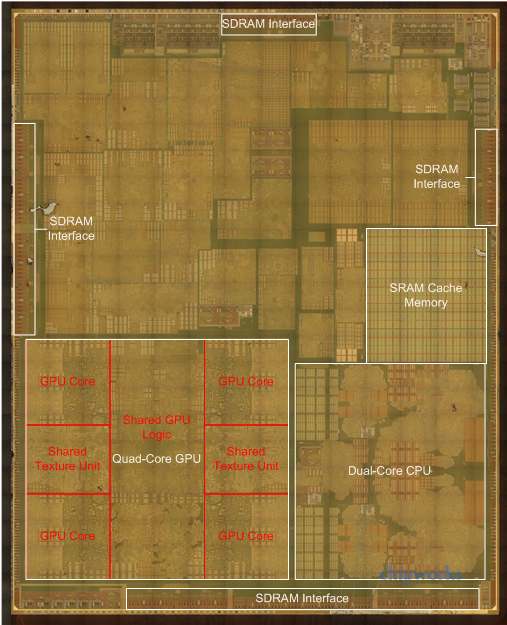
Stepping away from the GPU and CPU for the moment, the biggest change about A8 is that it’s smaller. As discovered by Chipworks, A8 is being fabricated on TSMC’s new 20nm process, making the iPhone 6 among the first smartphones to be shipped with a 20nm SoC.
This move to 20nm is not unexpected, but nonetheless it is considerable for a couple of reasons. The first is that this means Apple has moved production over to TSMC’s 20nm HKMG Planar process, making this the first time an Apple SoC has been manufactured anywhere but a Samsung fab. There are numerous possible reasons for this – and not every reason needs to be technical – but from a process development standpoint it’s important to note that over the last few generations TSMC has been the leader among contract foundries, being the first to get new processes up and running for volume production.
| Apple A8 vs A7 SoCs | ||||
| Apple A8 (2014) | Apple A7 (2013) | |||
| Manufacturing Process | TSMC 20nm HKMG | Samsung 28nm HKMG | ||
| Die Size | 89mm2 | 102mm2 | ||
| Transistor Count | ~2B | "Over 1B" | ||
| CPU | 2 x Apple Enhanced Cyclone ARMv8 64-bit cores |
2 x Apple Cyclone ARMv8 64-bit cores |
||
| GPU | IMG PowerVR GX6450 | IMG PowerVR G6430 | ||
This move is also quite considerable because it means for the first time Apple is manufacturing their SoCs on a bleeding edge manufacturing process. Prior to this Apple has been slow to utilize new manufacturing processes, only finally utilizing a 28nm process in late 2013 for A7 over a year after 28nm first became available. The fact that we are seeing a 20nm SoC from Apple at a time when almost everyone else is still on 28nm indicates just how much the market has shifted over the last few years, and how Apple’s SoC development is now synchronized with the very edge of semiconductor fabrication technology.
Finally, the switch to 20nm is interesting because after the last couple of generations being so-called “half node” jumps – 45nm to 40nm to 32nm to 28nm – the jump from 28nm to 20nm is a full node jump (note that Apple didn't ever use 40nm, however). This means we are seeing a larger increase in transistor density than in the previous generations, and ideally a larger decrease in power consumption as well.
In practice TSMC’s 20nm process is going to be a mixed bag; it can offer 30% higher speeds, 1.9x the density, or 25% less power consumption than their 28nm process, but not all three at once. In particular power consumption and speeds will be directly opposed, so any use of higher clock speeds will eat into power consumption improvements. This of course gets murkier once we’re comparing TSMC to Samsung, but the principle of clock speed/power tradeoffs remains the same regardless.
Not accounting for minor differences between TSMC and Samsung, in an ideal case Apple is looking at 51% area scaling (the same design on 20nm can be no smaller than 51% of the die area at 28nm). In reality, nothing ever scales perfectly so the density gains will depend on the kind of I/C being laid down (logic, SRAM, etc.). For the complete chip a 60-70% scaling factor is going to be a better approximation, which for Apple means they’ve picked up a lot room to spend on new functionality and reducing their overall die size.
| Apple SoC Evolution | |||||
| CPU Perf | GPU Perf | Die Size | Transistors | Process | |
| A5 | ~13x | ~20x | 122m2 | <1B | 45nm |
| A6 | ~26x | ~34x | 97mm2 | <1B | 32nm |
| A7 | 40x | 56x | 102mm2 | >1B | 28nm |
| A8 | 50x | 84x | 89mm2 | ~2B | 20nm |
Meanwhile once again this year Apple opened up on die size and transistor counts. A8 weighs in at around 2 billion transistors, as opposed to the “over 1 billion” transistors found on A7. We also have the die size for A8 – 89mm2 – which is some 13% smaller than A7’s 102mm2 die. This makes it clear that Apple has chosen to split their transistor density improvements between adding features/performance and reducing their size, rather than going all-in on either direction.
In the case of using a bleeding edge node this is generally a good call, as Apple and TSMC will need to deal with the fact that chip yields at 20nm will not be as good as they are on the highly mature 28nm process. With lower chip yields, a smaller die will offset some of those yield losses by reducing the number of manufacturing flaws any given die touches, improving the overall yield.

A8 With POP RAM Removed
Moving on, looking at A8 we can see that Apple’s memory subsystem design has not significantly changed from A7. Once again Apple has placed an SRAM cache on the chip to service both the CPU and the GPU. Based on an examination of the die and of latency numbers, this L3 SRAM cache remains unchanged from A7 at 4MB. Meanwhile we also find a series of SDRAM interfaces which drive the A8’s package-on-package (POP) based main memory. Based on teardowns from iFixit, Apple is using 1GB of LPDDR3-1600, the same speed grade of LPDDR3 and capacity that they used for the iPhone 5s. iFixit has found both Hynix and Elpida memory in their phones, so Apple is once again using multiple sources for their RAM.
When we start poking at memory bandwidth we find that memory bandwidths are consistently higher than on A7, but only ever so slightly. This points to Apple having worked out further optimizations to make better use of the memory bandwidth they have available, since as we’ve previously determined they’re still using LPDDR3-1600 speeds.
| Geekbench 3 Memory Bandwidth Comparison (1 thread) | ||||||
| Stream Copy | Stream Scale | Stream Add | Stream Triad | |||
| Apple A8 1.4GHz | 9.08 GB/s | 5.37 GB/s | 5.76 GB/s | 5.78 GB/s | ||
| Apple A7 1.3GHz | 8.34 GB/s | 5.21 GB/s | 5.67 GB/s | 5.69 GB/s | ||
| A8 Advantage | 9% | 3% | 2% | 2% | ||
The Stream Copy score ends up being the biggest gain at 9%. Otherwise the rest of the benchmarks only show 2-3% memory bandwidth increases.
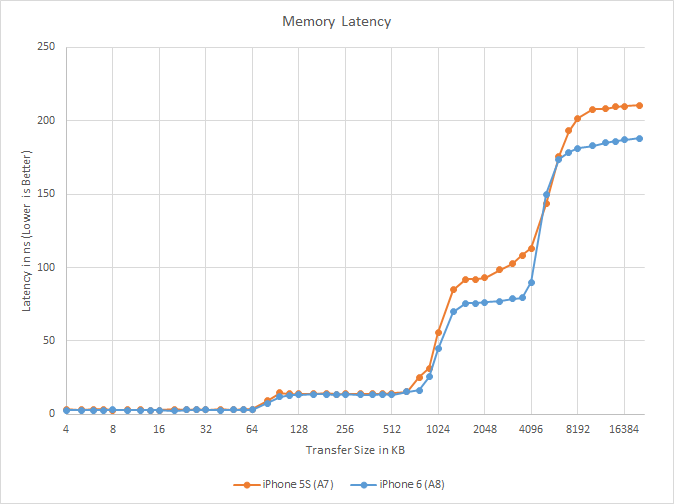
More interesting is memory latency, which shows some unexpected improvements once we get out of the L1 and L2 caches. At both the 1MB – 4MB region of the SRAM and 6MB+ region of main memory, memory latency is consistently lower on A8 versus A7. In both cases we’re looking at latencies about 20ns faster than A7. This identical 20ns gain tells us that that Apple is still doing main memory lookups after the L3 lookup fails, and this in turn means the 20ns gain we’re seeing is due to L3 cache optimizations. We have a couple of ideas for how Apple could have improved L3 latency by nearly 20% like this, but at this time with Apple staying quiet on their architecture like usual, it’s not apparent which of these ideas are the correct ones.
Turning our eyes back to A8 one final time, we find that while a lot of die space is occupied by the CPU, GPU, and SRAM (as we’d expect), there is also quite a bit of space occupied by other blocks Apple has integrated into their design. Without already knowing what you’re looking for these blocks are difficult to identify, but even without being able to do this we have a reasonable idea of what blocks Apple has integrated. Among these we’ll find audio controllers, USB controllers, video encoders/decoders, flash memory controllers, the camera ISP, and of course all kinds of interconnect.
All of these blocks are fixed function hardware (or at best, limited flexibility DSPs), which are equally important to not only the A8’s functionality but power efficiency. By assigning tasks to dedicated hardware Apple does spend some die space on that hardware, but in return these blocks are more efficient than doing those tasks entirely in software. Hence Apple (and SoC designers in general) have a strong incentive to offload as much work as possible to keep power consumption in check. This move towards more fixed function hardware is part of a general “wheel of reincarnation” cycle that has been a constant in processor design over the years, which sees a continuous shift between fixed function and programmable hardware. SoCs, for the most part, are still going towards fixed function hardware, and this should continue for a while yet.

In any case, while we can’t identify individual blocks on A8 we do know that Apple has added a few features to A8 that are present in some form or another among these blocks. New to A8 is some mix of H.265 (HEVC) hardware, which would be necessary to enable the FaceTime over H.265 functionality that is being introduced on the iPhone 6. Apple’s “desktop class scaler” that is used for handling non-native resolution applications and for down-sampling the internal rendering resolution of the iPhone 6 Plus would also be present here.








531 Comments
View All Comments
Caliko - Tuesday, October 6, 2015 - link
A good phone runs its own OS.You and that moron don't understand HD so your obsession is invalid.
echtogammut - Tuesday, September 30, 2014 - link
He isn't wrong about anything he said, but I just can't imagine getting worked up enough to say it. As a current Apple user/developer, I have every Apple product. I like their stuff, but I can't say I am obsessed about it. I also have a lot of the competing products, so I am constantly toying with all of them. When my current iPhone breaks, I will probably replace it with a Sony Xperia Z3 compact, because it looks like a perfect phone for me. I am not interested in a bigger phone and I would like something that is waterproof, because I run or ride a rain, sleet or shine. I personally think Apple is falling behind in the world of business and multi-use devices. I am seeing a lot of customers whom I developed business apps for iOS coming back and wanting to move to Microsoft or Android platforms because the devices are more powerful and offer more robust features.GerryS - Wednesday, October 1, 2014 - link
I agree. He makes some good points, though most of them are seriously overstated. For most users (yes, nearly everyone in my experience) a "pretty dang good" display is about as good as we can be bothered to look for. I actually like the display on my iPhone 4s. I've never had a complaint, except that it is small, so I got an iPad.See, I don't actually like it that Apple went for big phones. I carry my phone in my pants pocket. The 6 might be about the limit of the size phone I want. If I could get an updated 4s with the processor and other basic features of the 6, that's what I'd buy.
So, for most consumers, we want something that works. I had 4 Android phones before Verizon got the iPhone. I liked them pretty well, but they kept breaking. I went to Apple for dependability, and have not been disappointed. I've only had a couple of problems (even with my jailbreaks), and they've always been easy to fix.
I do like it when Apple leads the way, but it would be silly to expect them to have all of the advances. So many people compare the iPhones to Android phones, listing all of the things that came out first or "better" on Android phones. They seem to forget that there are dozens of companies making Android phones. The best of them have only one or tow innovations at a time - about the same as Apple manages. Apple continues to be one of the leaders, as long as you compare them to one company at a time.
If you want the universe of advances coming from Android manufacturers, then go buy an Android. We really won't hold it against you. For me, I like my iPhone and iPad. My wife has Android (at my recommendation) because we could get some features that were important to her.
Actius - Wednesday, October 1, 2014 - link
Lol, he is wrong about his engine analogy! Seriously, none of that makes any sense. Haha, and what's a "V8 compressor"? My goodness...people shouldn't talk about things they really don't know. Just reading that was cringe worthy.sigmatau - Thursday, October 2, 2014 - link
I'm going to guess you are not so dense as to be picking at the spelling but instead don't know what is a v8 Kompressor. Not only one of the best engines that Mercedes made, but also award winning by 3rd parties.techconc - Thursday, October 2, 2014 - link
Actually, he is either wrong or extremely misguided in almost everything he's said. Feel free to pick your argument of choice. He starts off by saying how the iPhone 6 launch was disastrous. As compared to what? What other vendor will sell 10 million devices on a launch weekend? Even for Apple, it broke their own previous records. I'm genuinely grateful for people that prove they're an idiot right up front. It lets me know I can either skip the rest of the post or read on for purely amusement purposes.That's just the conceptual part of the post. His technical observations were equally misguided. Especially with regard to screen quality, etc. Clearly he didn't bother reading the Anandtech review he's commenting on.
shm224 - Thursday, October 2, 2014 - link
@techconc: Sure, what other products you know starts to bend, or totally crap out after the first buggy update, or even have features withdrawn due to more bugs all within the first week of release?akdj - Friday, October 3, 2014 - link
Really? You're still convinced the iPhone (6 OR 6+) actually and easily 'bends' in the first week? Buggy update? The one available for about two hours that few downloaded and within ten hours of pulling it a fixed update was released? Features withdrawn? I'm intrigued ..as an owner and realist like techconc, the person you responded to... I've GOT to know!I'm patiently awaiting my pair of 6+s for my wife and I. We just returned from the mall and the Apple Store specifically playing for almost two hours with them. I built a two minute movie and. Rendered in 1080p in about 35/40 seconds, air dropped to myself. Un. Believable phone. It's. Amazing
We ordered launch day through our business representative. Lol. Silly me. Ship date estimate is pretty specific, actually a bit ambiguous with the latest update. 11/2-11/28/14:-)
Oh well. Plenty of time to allow developers to continue updating their apps.
Between my Air, rMBP 15" and the iPhone 5s /6+, my business of 27 years has been revolutionized. Literally, over the past half decade, as a pilot and sound/video producer...weight savings alone are enough to double our profits. And ½ our setup snd break down times. Even my 'flight bag' of nearly fifty pounds isn't necessary. With three retina minis in the cockpit for redundancy, the 'paper' is still there, but unnecessary any more for updates to plates and Jep charts, winds aloft and weather/traffic ...even diversion airports, filing my flight plan and telling me how thirsty she is! Fuel calculated, with a GPS dongle a tenth the price and 100 fold quicker to lock n track than avionics just a half decade ago provide incredible accuracy. ADSB and TCAS (3D terrain, weather and other traffic/with their specific info; altitude, speed, heading, and Xspnder --- TCAS, a warning system that 'tells you what to do' in conjunction with other planes fitted with the system including all commercial traffic and many GA pilots with ILS certifications ...Alaska can get nasty quick and having to 'duck down' these two systems alone are incredible and 'reasonably priced' advancements!).
I'm not sure there's a place in my life iOS has t changed. As a father, business owner and operator, little league and wrestling coach, and pilot...each iteration has improved signficantly enough in 'most situations' to justify yearly updates for me. iPhones hold their value. Until the 4s, AT&T was generous and 'allowed' a 12 month subsidized update. With the business I also provide 17 full time employee iPhones so we've been lucky enough to 'recoup' some of the money spent each update
I just sold an employee's iPhone 5, 32GB AT&T with a cracked screen, scratched to hell and working perfectly. With excellent battery health and perfect camera lens (only scratch-less area of the phone!) for $235 to a local repair guy. He saw me in the mall with the Gazelle box (more than a hundred bucks less) on my way to the USPS. Asked what I was sending. Told him. Showed him a 'picture' or seven before I unboxed it, but he was adamant ...he was able to shine it up with his pieces n parts for $45 or less! Told me it would cost a customer about $210 to do the work but parts were 20% the cost ...labor and time is the price. From there he was confident he could sell it for $325-350 at his kiosk within 24 hours.
My son has had his fifth generation iPod touch for two years. He's nine. No scratches. No scuffs. Clean a booger or twelve off once a week but other than that, it's completely 'perfect'. These iPhones are built damn near the same. Sleek, thin and well balanced ...no bugs, incredibly quick and unless you're a dumbass and put your $800 pocket computer in your rear pocket of your jeans and SIT on it, you're an idiot ...and you've got to be SIGNIFICANTLY overweight AND hit the precise angle in order to 'mash' 100 pounds of pressure to a 'single point'/torque.
Can you bend em? Yep. It's been proven and EVERY piece of proof we've seen visually demonstrates the incredible amount of force necessary and in such a way not indicative of daily use or situations a consumer would find themselves in 99.9% of the time.
Don't. Be. Silly. I respond not only to you but to all those talking like you. Until you've used one. Felt one. Actually spent time with it, it's difficult to understand.
These are absolute and unequivably the BEST two phones on the maket at this time. With the best and most abundant apps/software optimized to its specs. Support to back it up. And resale value when Ya get bored and ready for a new one. You'll recover your 'down payment' plus fifty percent in many cases ...if you take care of it. Seemingly, they're even more valuable than a same year flagship Samsung Note 2, as I wasn't able to get more than $125 for that joke. Note 3 got it right. But it took twice the cores, clocked at twice the speed with three times the memory ( ⅔ to ¾ of which is in use even without an app running! I've got one though and don't take me wrong, I love it) to get 'close' to the GUI fluency of the iPhone & iOS
That's. SAD. That's. Buggy. I'd much rather have a phone that bends with a hundred pounds of torque in a certain and specific area than I would gambling I'll get an update, deal with carriers and OEM bloat and shitty aesthetics and design. Lack of support or resale, lack of apps and software ...& the apps and software in parity are incredibly more enjoyable and stable on iOS. I like my Note for browsing and the SPen. I think an active digitizer would put the six plus over the top but as it is, it's perfect.
Indeed, I'll continue using (& owning) my N3. But I'm not the least bit compelled with the '4' and its 2540 display. While I'm sure there's noticeable and 'obvious' benefits to having 550/600+ PPI ...I'll warn ya when you're 38-42, speaking from experience...you'll need 'cheaters';) ...like our ears, our eyes deteriorate as well ...the elasticity of our lens and ability to change and 'maintain' up close focus just ...goes away! Hence the incredible benefits I've found witg the HiDPI display technology. 3D? Good riddance! It was a joy to see 4k/Ultra HD and even examples of 5/6 & 8K motion display AND capture gear instead of dumbass glasses and crappy off center viewing with limited content.
Apple lead the way and destroyed multi billion dollar monsters in the industry with the iPhone. They then changed consumer display technology's availability. HiDPI and increased resolution is awesome. But to a certain point. Your 1080p 65" LED LCD IPS or AMOLED TV in the living room at 10-12 feet or typical viewing distances is around 100ppi. Quadrupling the resolution (4k) while not exactly linear, will amount to approximately an increase of 100%. To 200ppi. Not four foukd as you may think.
The 'new' ipad(3)/4 -- iPhone 4 -- the rMBPs --- ALL Game Changing home runs. Putting a certain 'joy' back into 'work' again. With SUCH an accurate palate and the ability of OS X'es scaling of the UI (& third party apps the same ...utilizing pixel for pixel when necessary or quadrupling for the GUI simultaneously and without 'glitches' or latency is a marvel in engineering. Coupled with the IrisPro 5200/750m and PCIe SSD at a TB with read and write speeds exceeding a Gb/s, Thunderbolt 2 and its 'one' cable capabilities and abilities to run multiple 4K displays ...shoot man. Seems like yesterday I was hunting the wax pencils and cutting my fingers slicing tape ...now it's immediate and fast as hell in a four pound package at a dozen times the resolution.
Times are good if you're an Apple user. And thats JUST the hardware!
OS X and iOS's march to marriage is incredible. Continuity and Handoff. Air drop between iOS and OS X, as well ...the aggregation and integration between the devices you're using is revolutionary. Period. Only Windows has the power and support vertically and horizontally to compete with what Apple's doing. Vertical & Horizontal backbones.
No one that needs to 'work' is buying a Chromebook
J
elajt_1 - Friday, October 3, 2014 - link
This must've been the longest and weirdest Iphone ad I've ever read. ;-)techconc - Monday, October 6, 2014 - link
@shm224 - I now know several people with iPhone 6 and 6+ devices that keep them in their pockets. They all seem to agree that there is no merit to this "bend gate" nonsense. While nobody doubts that these phones can bend under a certain amount of pressure (90 lbs. according to Consumer Reports), from a practical matter, it's a non-issue. Further, I find it rather interesting that phones such as the HTC One which bend under significantly less pressure (70 lbs.) don't receive the same sort of media attention.As for the 8.0.1 update, yup, Apple screwed that up. Fortunately, for Apple, the update was pulled after about an hour. It's also fortunate that in only affected some phones and only for the over the air update as opposed to the iTunes update. To your point, no, this typically isn't an issue for other phones... then again, neither are regular updates.