The iPhone 6 Review
by Joshua Ho, Brandon Chester, Chris Heinonen & Ryan Smith on September 30, 2014 8:01 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 6
A8’s CPU: What Comes After Cyclone?
Despite the importance of the CPU in Apple’s SoC designs, it continues to be surprising just how relatively little we know about their architectures even years after the fact. Even though the CPU was so important that Apple saw the need to create their own custom design, and then did two architectures in just the span of two years, they are not fond of talking about just what it is they have done with their architectures. This, unfortunately, is especially the case at the beginning of an SoC’s lifecycle, and for A8 it isn’t going to be any different.
Overall, from what we can tell the CPU in the A8 is not a significant departure from the CPU in A7, but that is not a bad thing. With Cyclone Apple hit on a very solid design: use a wide, high-IPC design with great latency in order to reach high performance levels at low clock speeds. By keeping the CPU wide and the clock speed low, Apple was able to hit their performance goals without having to push the envelope on power consumption, as lower clock speeds help keep CPU power use in check. It’s all very Intel Core-like, all things considered. Furthermore given the fact that Cyclone was a forward-looking design with ARMv8 AArch64 capabilities and already strong performance, Apple does not face the same pressure to overhaul their CPU architecture like other current ARMv7 CPU designers do.

Close Up: "Enhanced Cyclone"
As a result, from the information we have been able to dig up and the tests we have performed, the A8 CPU is not radically different from Cyclone. To be sure there are some differences that make it clear that this is not just a Cyclone running at slightly higher clock speeds, but we have not seen the same kind of immense overhaul that defined Swift and Cyclone.
Unfortunately Apple has tightened up on information leaks and unintentional publications more than ever with A8, so the amount of information coming out of Apple about this new core is very limited. In fact this time around we don’t even know the name of the CPU. For the time being we are calling it "Enhanced Cyclone" – it’s descriptive of the architecture – but we’re fairly certain that it does have a formal name within Apple to set it apart from Cyclone, a name we hope to discover sooner than later.
In any case one of the things we do know about Enhanced Cyclone is that unlike Apple’s GPU of choice for A8, Apple has seen a significant reduction in the die size of the CPU coming from the 28nm A7 to the 20nm A8. Chipworks’ estimates put the die size of Cyclone at 17.1mm2 versus 12.2mm2 for Enhanced Cyclone. On a relative basis this means that Enhanced Cyclone is 71% the size of Cyclone, which even after accounting for less-than-perfect area scaling still means that Enhanced Cyclone is a relatively bigger CPU composed of more transistors than Cyclone was. It is not dramatically bigger, but it’s bigger to such a degree that it’s clear that Apple has made further improvements over Cyclone.
The question of the moment is what Apple has put their additional transistors and die space to work on. Some of that is no doubt the memory interface, which as we’ve seen earlier L3 cache access times are nearly 20ns faster in our benchmarks. But if we dig deeper things start becoming very interesting.
| Apple Custom CPU Core Comparison | ||||||
| Apple A7 | Apple A8 | |||||
| CPU Codename | Cyclone | "Enhanced Cyclone" | ||||
| ARM ISA | ARMv8-A (32/64-bit) | ARMv8-A (32/64-bit) | ||||
| Issue Width | 6 micro-ops | 6 micro-ops | ||||
| Reorder Buffer Size | 192 micro-ops | 192 micro-ops? | ||||
| Branch Mispredict Penalty | 16 cycles (14 - 19) | 16 (14 - 19)? | ||||
| Integer ALUs | 4 | 4 | ||||
| Load/Store Units | 2 | 2 | ||||
| Addition (FP) Latency | 5 cycles | 4 cycles | ||||
| Multiplication (INT) Latency | 4 cycles | 3 cycles | ||||
| Branch Units | 2 | 2 | ||||
| Indirect Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 3 | 3 | ||||
| L1 Cache | 64KB I$ + 64KB D$ | 64KB I$ + 64KB D$ | ||||
| L2 Cache | 1MB | 1MB | ||||
| L3 Cache | 4MB | 4MB | ||||
First and foremost, in much of our testing Enhanced Cyclone performs very similarly to Cyclone. Accounting for the fact that A8 is clocked at 1.4GHz versus 1.3GHz for A7, in many low-level benchmarks the two perform as if they are the same processor. Based on this data it looks like the fundamentals of Cyclone have not been changed for Enhanced Cyclone. Enhanced Cyclone is still a very wide six micro-op architecture, and branch misprediction penalties are similar so that it’s likely we’re looking at the same pipeline length.
However from our low-level tests two specific features stand out: integer multiplication and floating point addition. When it comes to integer multiplication Cyclone had a single multiplication unit and it took four cycles to execute. However against Enhanced Cyclone those operations are now measuring in at three cycles to execute. But more surprising is the total Integer multiplication throughput rate; integer multiplication performance has now more than doubled. While this doesn’t give us enough data to completely draw out Enhanced Cyclone’s integer pathways, all of the data points to Enhanced Cyclone doubling up on its integer multiplication units, meaning Apple’s latest architecture now has two such units.
Meanwhile floating point addition shows similar benefits, though not as great as integer multiplication. Throughput is such that there appears to still be three FP ALUs, but like integer multiplication the instruction latency has been reduced. Apple has managed to shave off a cycle on FP addition, so it now completes in four cycles instead of five. Both of these improvements indicate that Enhanced Cyclone is not identical to Cyclone – the additional INT MUL unit in particular – making them very similar but still subtly different CPU architectures.
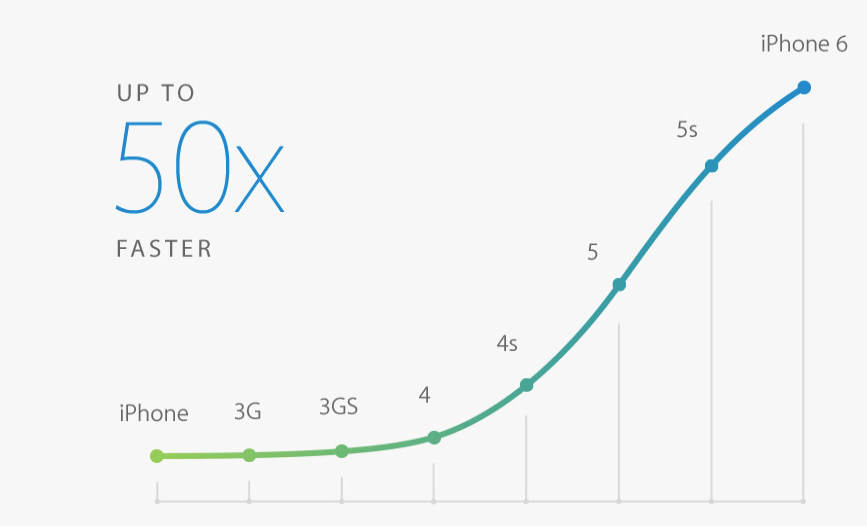
Apple iPhone Performance Estimates: Over The Years
Outside of these low-level operations, most other aspects of Enhanced Cyclone seem unchanged. L1 cache remains at 64KB I$ + 64KB D$ per CPU core, where it was most recently doubled for Cyclone. For L2 cache Chipworks believes that there may be separate L2 caches for each CPU core, and while L2 cache bandwidth is looking a little better on Enhanced Cyclone than on Cyclone, it’s not a “smoking gun” that would prove the presence of separate L2 caches. And of course, the L3 cache stands at 4MB, with the aforementioned improvements in latency that we’ve seen.
To borrow an Intel analogy once more, the layout and performance of Enhanced Cyclone relative to Cyclone is quite similar to Intel’s more recent ticks, where smaller feature improvements take place alongside a die shrink. In this case Apple has their die shrink to 20nm; meanwhile they have made some small tweaks to the architecture to improve performance across several scenarios. At the same time Apple has made a moderate bump in clock speed from 1.3GHz to 1.4GHz, but it’s nothing extreme. Ultimately while two CPU architectures does not constitute a pattern, if Apple were to implement tick-tock then this is roughly what it would look like.
Moving on, after completing our low-level tests we also wanted to spend some time comparing Enhanced Cyclone with its predecessor on some high level tests. The low-level tests can tell us if individual operations have been improved while high level tests can tell us something about what the performance impact will be in realistic workloads.
For our first high level benchmark we turn to SPECint2000. Developed by the Standard Performance Evaluation Corporation, SPECint2000 is the integer component of their larger SPEC CPU2000 benchmark. Designed around the turn of the century, officially SPEC CPU2000 has been retired for PC processors, but with mobile processors roughly a decade behind their PC counterparts in performance, SPEC CPU2000 is currently a very good fit for the capabilities of Cyclone and Enhanced Cyclone.
SPECint2000 is composed of 12 benchmarks which are then used to compute a final peak score. Though in our case we’re more interested in the individual results.
| SPECint2000 - Estimated Scores | ||||||
| A8 | A7 | % Advantage | ||||
| 164.gzip |
842
|
757
|
11%
|
|||
| 175.vpr |
1228
|
1046
|
17%
|
|||
| 176.gcc |
1810
|
1466
|
23%
|
|||
| 181.mcf |
1420
|
915
|
55%
|
|||
| 186.crafty |
2021
|
1687
|
19%
|
|||
| 197.parser |
1129
|
947
|
19%
|
|||
| 252.eon |
1933
|
1641
|
17%
|
|||
| 253.perlbmk |
1666
|
1349
|
23%
|
|||
| 254.gap |
1821
|
1459
|
24%
|
|||
| 255.vortex |
1716
|
1431
|
19%
|
|||
| 256.bzip2 |
1234
|
1034
|
19%
|
|||
| 300.twolf |
1633
|
1473
|
10%
|
|||
Keeping in mind that A8 is clocked 100MHz (~7.7%) higher than A7, all of the SPECint2000 benchmarks show performance gains above and beyond the clock speed increase, indicating that every benchmark has benefited in some way. Of these benchmarks MCF, GCC, PerlBmk and GAP in particular show the greatest gains, at anywhere between 20% and 55%. Roughly speaking anything that is potentially branch-heavy sees some of the smallest gains while anything that plays into the multiplication changes benefits more.
MCF, a combinatorial optimization benchmark, ends up being the outlier here by far. Given that these are all integer benchmarks, it may very well be that MCF benefits from the integer multiplication improvements the most, as its performance comes very close to tracking the 2X increase in multiplication throughput. This also bodes well for any other kind of work that is similarly bounded by integer multiplication performance, though such workloads are not particularly common in the real world of smartphone use.
Our other set of comparison benchmarks comes from Geekbench 3. Unlike SPECint2000, Geekbench 3 is a mix of integer and floating point workloads, so it will give us a second set of eyes on the integer results along with a take on floating point improvements.
| Geekbench 3 - Integer Performance | ||||||
| A8 | A7 | % Advantage | ||||
| AES ST |
992.2 MB/s
|
846.8 MB/s
|
17%
|
|||
| AES MT |
1.93 GB/s
|
1.64 GB/s
|
17%
|
|||
| Twofish ST |
58.8 MB/s
|
55.6 MB/s
|
5%
|
|||
| Twofish MT |
116.8 MB/s
|
110.0 MB/s
|
6%
|
|||
| SHA1 ST |
495.1 MB/s
|
474.8 MB/s
|
4%
|
|||
| SHA1 MT |
975.8 MB/s
|
937 MB/s
|
4%
|
|||
| SHA2 ST |
109.9 MB/s
|
102.2 MB/s
|
7%
|
|||
| SHA2 MT |
219.4 MB/
|
204.4 MB/s
|
7%
|
|||
| BZip2Comp ST |
5.24 MB/s
|
4.53 MB/s
|
15%
|
|||
| BZip2Comp MT |
10.3 MB/s
|
8.82 MB/s
|
16%
|
|||
| Bzip2Decomp ST |
8.4 MB/
|
7.6 MB/s
|
10%
|
|||
| Bzip2Decomp MT |
16.5 MB/s
|
15 MB/s
|
10%
|
|||
| JPG Comp ST |
19 MP/s
|
16.8 MPs
|
13%
|
|||
| JPG Comp MT |
37.6 MP/s
|
33.3 MP/s
|
12%
|
|||
| JPG Decomp ST |
45.9 MP/s
|
39 MP/s
|
17%
|
|||
| JPG Decomp MT |
89.3 MP/s
|
77.1 MP/s
|
15%
|
|||
| PNG Comp ST |
1.26 MP/s
|
1.14 MP/s
|
10%
|
|||
| PNG Comp MT |
2.51 MP/s
|
2.26 MP/s
|
11%
|
|||
| PNG Decomp ST |
17.4 MP/s
|
15.1 MP/s
|
15%
|
|||
| PNG Decomp MT |
34.3 MPs
|
29.6 MP/s
|
15%
|
|||
| Sobel ST |
71.7 MP/s
|
58.1 MP/s
|
23%
|
|||
| Sobel MT |
137.1 MP/s
|
112.4 MP/s
|
21%
|
|||
| Lua ST |
1.64 MB/s
|
1.34 MB/s
|
22%
|
|||
| Lua MT |
3.22 MB/s
|
2.64 MB/s
|
21%
|
|||
| Dijkstra ST |
5.57 Mpairs/s
|
4.04 Mpairs/s
|
37%
|
|||
| Dijkstra MT |
9.43 Mpairs/s
|
7.26 Mpairs/s
|
29%
|
|||
Geekbench’s integer results are overall a bit more muted than SPECint2000’s, but there are still some definite high points and low points among these benchmarks. Crypto performance is among the lesser gains, while Sobel and Dijkstra are among the largest at 21% and 37% respectively. Interestingly in the case of Dijkstra, this does make up for the earlier performance loss Cyclone saw on this benchmark in the move to 64-bit.
| Geekbench 3 - Floating Point Performance | ||||||
| A8 | A7 | % Advantage | ||||
| BlackScholes ST |
7.85 Mnodes/s
|
5.89 Mnodes/s
|
33%
|
|||
| BlackScholes MT |
15.5 Mnodes/s
|
11.8 Mnodes/s
|
31%
|
|||
| Mandelbrot ST |
1.18 GFLOPS
|
929.4 MFLOPS
|
26%
|
|||
| Mandelbrot MT |
2.34 GFLOPS
|
1.85 GFLOPS
|
26%
|
|||
| Sharpen Filter ST |
981.7 MFLOPS
|
854 MFLOPS
|
14%
|
|||
| Sharpen Filter MT |
1.94 MFLOPS
|
1.7 GFLOPS
|
14%
|
|||
| Blur Filter ST |
1.41 GFLOPS
|
1.26 GFLOPS
|
11%
|
|||
| Blur Filter MT |
2.78 GFLOPS
|
2.49 GFLOPS
|
11%
|
|||
| SGEMM ST |
3.83 GFLOPS
|
3.44 GFLOPS
|
11%
|
|||
| SGEMM MT |
7.48 GFLOPS
|
6.4 GFLOPS
|
16%
|
|||
| DGEMM ST |
1.87 GFLOPS
|
1.68 GFLOPS
|
11%
|
|||
| DGEMM MT |
3.61 GFLOPS
|
3.14 GFLOPS
|
14%
|
|||
| SFFT ST |
1.77 GFLOPS
|
1.59 GFLOPS
|
11%
|
|||
| SFFT MT |
3.47 GFLOPS
|
3.18 GFLOPS
|
9%
|
|||
| DFFT ST |
1.68 GFLOPS
|
1.47 GFLOPS
|
14%
|
|||
| DFFT MT |
3.29 GFLOPS
|
2.93 GFLOPS
|
12%
|
|||
| N-Body ST |
735.8 Kpairs/s
|
587.8 Kpairs/s
|
25%
|
|||
| N-Body MT |
1.46 Mpairs/s
|
1.17 Mpairs/s
|
24%
|
|||
| Ray Trace ST |
2.76 MP/s
|
2.23 MP/s
|
23%
|
|||
| Ray Trace MT |
5.45 MP/s
|
4.49 MP/s
|
21%
|
|||
While the low-level floating point tests we ran earlier didn’t show as significant a change in the floating point performance of the architecture as it did the integer, our high level benchmarks show that floating point tests are actually faring rather well. Which goes to show that not everything can be captured in low level testing, especially less tangible aspects such as instruction windows. More importantly though this shows that Enhanced Cyclone’s performance gains aren’t just limited to integer workloads but cover floating point as well.
Overall, even without a radical change in architecture, thanks to a combination of clock speed increases, architectural optimizations, and memory latency improvements, Enhanced Cyclone as present in the A8 SoC is looking like a solid step up in performance from Cyclone and the A7. Over the next year Apple is going to face the first real competition in the ARMv8 64-bit space from Cortex-A57 and other high performance designs, and while it’s far too early to guess how those will compare, at the very least we can say that Apple will be going in with a strong hand. More excitingly, most of these performance improvements build upon Apple’s already strong single-threaded IPC, which means that in those stubborn workloads that don’t benefit from multi-core scaling Apple is looking very good.








531 Comments
View All Comments
Samus - Tuesday, September 30, 2014 - link
Too many people define "good LCD" as having high resolution. In the real world, that just isn't true. There are so many terrible 1920x1080 panels on the market, and I'm not just talking mobile devices.Look at desktop LCD's. To get one properly calibrated you need to spend $500+ for a 24" HP Dreamcolor or NEC Multisync PA Spectraview. Some Dell's with Samsung LCD's are pretty good out of the box but almost nothing is 100% RGB until expensive calibration.
So back to Apple. They're all about balance. They don't push the envelope in any direction like Samsung (and others.) What bothers me lately about Apple is they are "too" safe with their design language and technology that their products are actually becoming boring. As the company that pioneered mainstream unibody mobile devices and multitouch\gesture driven interfaces, it's interesting the competition has essentially been perfecting it for them to just copy back.
At least Apple isn't suing everybody anymore...seems like Steve's thermonuclear crusade is finally dying along with him.
Omega215D - Tuesday, September 30, 2014 - link
I do have a problem with people constantly trying to push AMOLED as the ultimate display tech due it being featured on DisplayMate with the Galaxy S5. People forget that you lose the efficiency of OLED once you start using something that displays a lot of white like web browsing. Also, turning down the brightness still has the tendency to give it a "soggy" look to it, though it is much less on the Galaxy S5.The burn in effect can be easily avoided unless the clock/ dock locks up for whatever reason and leaves the display static.
darkich - Tuesday, September 30, 2014 - link
The burn in can be easily prevented also.Download an utterly simple burn in tool app, and leave it working for couple of hours, every few weeks or so.
nevertell - Wednesday, October 1, 2014 - link
This is exactly the kind of thing that people DO NOT WANT TO DO.It's a phone, it must just work, I shouldn't worry about any specific technical part of the phone, let alone do maintenance work on it to keep it functional.
elajt_1 - Friday, October 3, 2014 - link
Nah, thats for bad image retention. If you already got a burn-in you can't do anything about that as of now.Toss3 - Wednesday, October 8, 2014 - link
In my experience AMOLED displays look a lot better than their LCD counterparts with the brightness turned down. They also give you the option of having even lower screen brightness which is ideal if you want to use it in bed at night (night mode on android looks great on the S4, but not so much on my Nexus 5).hoelee - Thursday, December 4, 2014 - link
IPhone white balance not accurate, how you proven your point said iPhone had good display? At least I saw on mine eye compare between mine z3 with the so call iPhone... Besides, you calculate by yourself, iPhone 6 latest phone less 1x pixels to push compare to android FHD screen. Benchmark alway unfair in mine point of view...braveit - Friday, December 12, 2014 - link
Apple hasn't really done much on it's new iPhone 6 release. Source: http://berichinfo.com/reasons-iphone-6-sucks/Caliko - Tuesday, October 6, 2015 - link
Who else is innovating in design?All phones today are iKnockoffs.
Steve's thermonuclear attack has juat started buddy!! Droid is making manufacture lose billions. Can't wait to see who goes bankrupt first!!
akdj - Thursday, October 2, 2014 - link
The 'little SD expansion slot' that reads and writes at about 6-8Mb/second vs, the onboard NAND speed tested within the review should be enough to tell you why samsung and ....hmmm ....are offering the micro SD slot. Android is moving 'away' from accessibility to and from the 'off board' storage. I've got a Note 3 and with each update I've been able to do less and lessApparently you didn't bother to read the review ...at all. You also mention 'good LCD ...at least as good as the competitors.'
Then you quite DisplayMate. The S5. And the single point difference between it and it's LCD runner up. From Apple. If you'd have bothered to have read this review ...or the S5 review on Anand's site when it dropped you'd know A) how impressed the author was with the evolution of AMOLED, it's continued refinement and accuracy, brightness and viewing angles. B) you'd notice in EVERY possible measurement. Each one in the review are 'objective measurements'. It (6) tops the display's characteristics in each area someone that knows what a 'great display' entails. At 400+ PPI, you nor any of your freneds will distinguish the difference between it and the new Note 4 or any other 2540 display. It's silly, it's a waste of energy and its detrimental to fluency of the UI (with today's SoC GPU and that many pixels) and the ever important 'battery life'
To be fair, NO OTHER vendor offers 128GB, & 64 is extremely rare. I waited six weeks for a Note 3 w/64GB to show up at AT&T. Never happened and I settled for 32. At the same price as the 64GB iPhone 6.
And from what I've read the 2014 model will have the same. 32GB with a caveat. Buy a micro SD card. Hope Google allows support in the future and keep your fingers crossed. 1080p on my Note chews up space. 4K is quadruple. And it will NOT shoot to the fastest SD or microSD card on the market.
As an ambidextrous owner and user since their inception, I enjoy both Android and iOS. But silly comments like yours shows your ignorance. It was IN THE review! The actual (& damn near identical testing method used by DisplayMate's team will use) 'proof' it's 'LCD ....(IS) @ least as good as its competitors.