Cortex-M7 Launches: Embedded, IoT and Wearables
by Stephen Barrett on September 23, 2014 7:01 PM ESTThe Cortex-M7 CPU
The primary focus of the Cortex-M7 is improved performance. ARM’s goal was to elevate the M series performance to a level previously unseen, while maintaining the M series' signature small die size and tiny power consumption. There are at least two reasons ARM focused on performance for the M7 processor. First, they want to further drive a wedge between traditional 8- and 16-bit microcontrollers and provide ARM a further differentiated market position; second, the M7 will help support the IoT (Internet of Things) and wearable device markets. Focusing on enhanced DSP capabilities, the M7 is more suited to audio and visual sensor hub processing than any previous M series design.
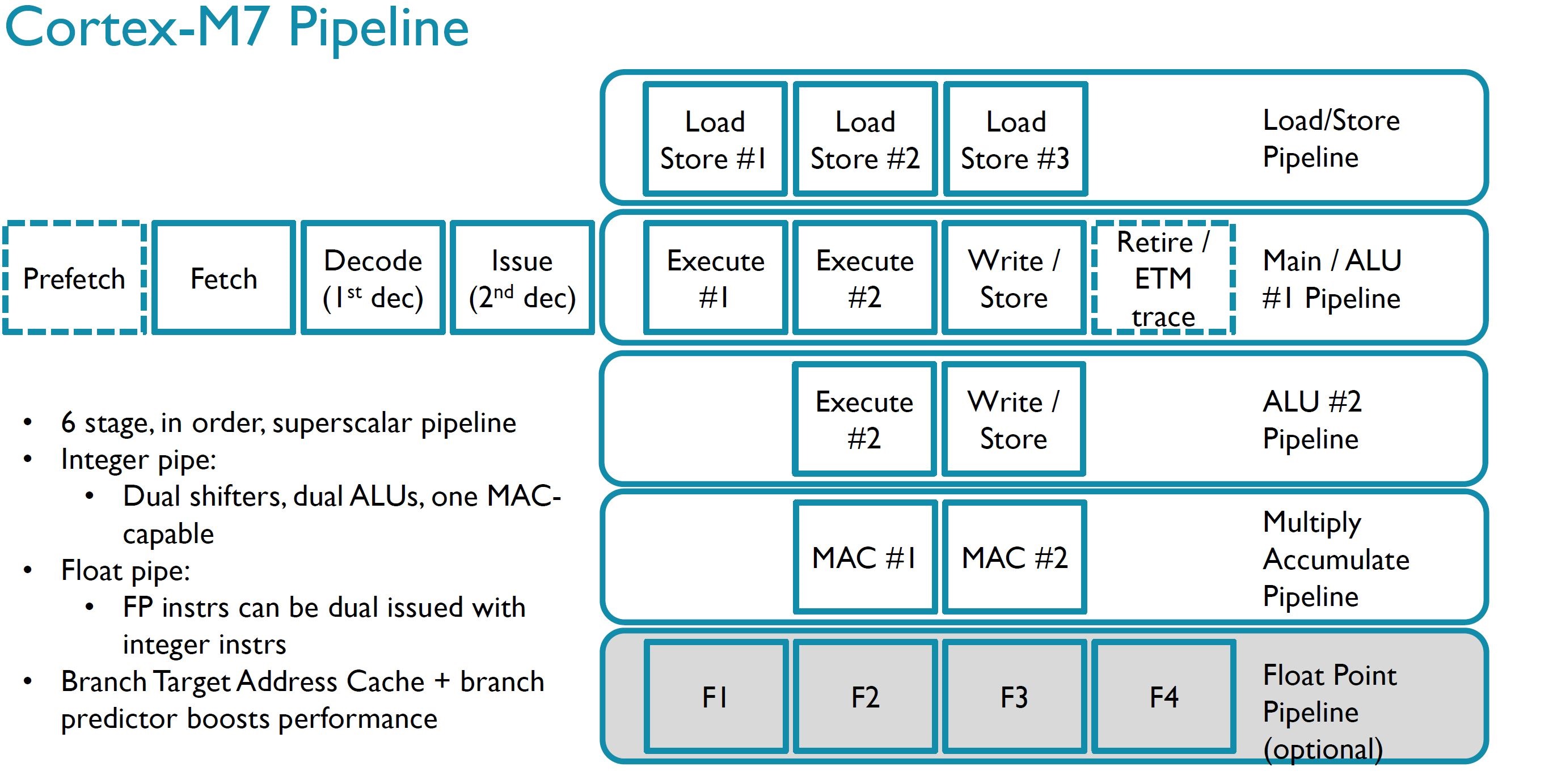
Digging into the details, the Cortex-M7 features a six-stage, in-order, dual-issue superscalar pipeline with single- and double-precision floating point units, instruction and data caches, branch prediction, SIMD support, and tightly coupled memory. Here's the high level view of the pipeline:
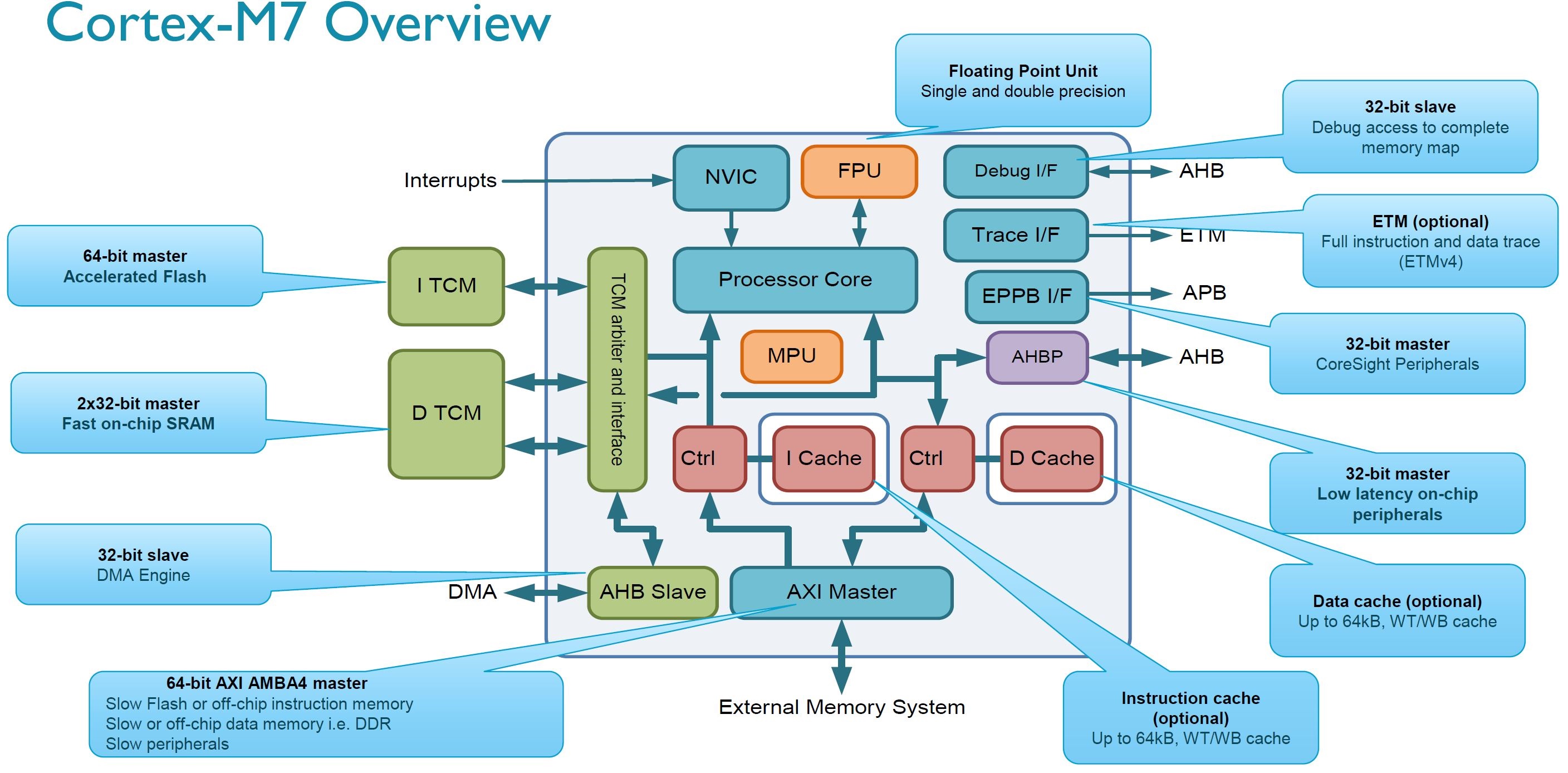
The presence of instruction and data caches, branch prediction, as well as tightly coupled memory are differentiating features of the M7 versus previous M series processors. Microcontrollers often forego caches and sometimes even operate with flash as the only memory interface. By providing high performance instruction and data caches, the M7 approaches more typical high performance processor design.
Tightly coupled memory (TCM) is a technology ARM’s partners can use to extend the effective caching of a single M7 processor and has only been seen in previous A and R series designs. In use, it can have the performance of a cache but, unlike cache, its contents are directly controlled by the developer. That is, TCM is part of the physical memory map of the microcontroller. Developers can place critical code and data inside TCM that can be deterministically accessed with high performance in routines such as interrupt service requests. The M7 supports up to 16 MB of tightly coupled memory.
Adding branch prediction allows arm to target dedicated DSP devices with its Cortex-M7 microcontroller. DSP code is often analog data stream filters for applications such as audio input keyword detection, audio output equalization, and frequency domain amplitude peak searching. When running on an always-on microcontroller these tasks are almost always looped. Without a branch predictor, the code must continually evaluate a loop condition that 99.9% of the time results in the same outcome. Branch predictors cost extra die space but when DSP is your target, they are an obvious design benefit.

Summarizing the M series cores can be done both from an instruction features standpoint and also a die size and performance standpoint. Unfortunately ARM, who provides HDL (Hardware Description Language) that can be synthesized to physical chips, was not yet willing to provide die size numbers until their partner Cortex-M7 announcements, since the processor does not become physical until a partner gets involved. Until a partner releases data, we can simply assume the M7 somewhat larger than its predecessors.
| ARM Cortex-M Instruction Sets | |||||||||||
| M0 | M0+ | M3 | M4 | M7 | |||||||
| Thumb | Most | Most | Entire | Entire | Entire | ||||||
| Thumb-2 | Subset | Subset | Entire | Entire | Entire | ||||||
| Hardware multiply | 1 or 32 cycles | 1 or 32 cycles | 1 cycle | 1 cycle | 1 cycle | ||||||
| Hardware divide | No | No | Yes | Yes | Yes | ||||||
| Saturated math | No | No | Yes | Yes | Yes | ||||||
| DSP Extensions | No | No | No | Yes | Yes, enhanced | ||||||
| Floating-point | No | No | No | Optional single precision | Yes | ||||||
| Tightly coupled memory | No | No | No | No | yes | ||||||
| Architecture | ARMv6-M | ARMv6-M | ARMv7-M | ARMv7-M | ARMv7-M | ||||||
| Cache Architecture | Von Neuman | Von Neuman | Harvard | Harvard | Harvard | ||||||
| ARM Cortex-M Area, Power, Performance | |||||||||||
| M0 | M0+ | M3 | M4 | M7 | |||||||
| 90nm LP dynamic power (µW/MHz) | 16 | 9.8 | 32 | 33 | n/a | ||||||
| 90nm LP area mm2 | 0.04 | 0.035 | 0.12 | 0.17 | n/a | ||||||
| 40nm G dynamic power (µW/MHz) | 4 | 3 | 7 | 8 | n/a | ||||||
| 40nm G area mm2 | 0.01 | 0.009 | 0.03 | 0.04 | n/a | ||||||
| Dhrystone (official) DMIPS/MHz | 0.84 | 0.94 | 1.25 | 1.25 | 2.14 | ||||||
| Dhrystone (max options) DMIPS/MHz | 1.21 | 1.31 | 1.89 | 1.95 | 3.23 | ||||||
| CoreMark/MHz | 2.33 | 2.42 | 3.32 | 3.40 | 5.04 | ||||||
ARM did state that power consumption of M7 is roughly in line with previous performance/mW, so we could estimate a corresponding increase of 50% to 75% more power consumption. Area is anyone's guess at the moment.








43 Comments
View All Comments
Wilco1 - Thursday, September 25, 2014 - link
It does 2 16-bit MACs per cycle and the graph shows 2x32 interfaces to DTCM, so that should mean it can sustain 2 MACs plus 64-bit load/store per cycle.fteoath64 - Saturday, September 27, 2014 - link
Even on a mid-wearable config, a 500Mhz Soc seems really overkill considering the original iPhone had a 400Mhz Soc and could do all the phone functions except taking speech (this could be done using a small custom DSP on the Soc). For a wearable, it cannot be expected to play video but maybe capture 3 minute video segments at a time. It seems the industry is pushing hardware as an overkill rate just to spur up a new segment of the market. This has led to compromises in battery life due to too much transistor counts and too high frequency chips being used. There was a day when a Pentium 266Mhz was a fast computer. Just our perception of numbers makes us think, it is slow as molluscs today. It ain't that slow. Running Linux, it does nicely.jinish - Tuesday, November 17, 2015 - link
Hi!The post is more than a year old now.. Were you guys able to fetch the area of cortex M7, till date?