The NVIDIA GeForce GTX 980 Review: Maxwell Mark 2
by Ryan Smith on September 18, 2014 10:30 PM ESTMaxwell 2’s New Features: Direct3D 11.3 & VXGI
When NVIDIA introduced the Maxwell 1 architecture and the GM107 based GTX 750 series, one of the unexpected aspects of their decision was to release these parts as members of the existing 700 series rather than a newer series to communicate a difference in features. However as it turned out there really wasn’t a feature difference between it and Kepler; other than a newer NVENC block, Maxwell 1 was for all intents and purposes an optimized Kepler architecture. It was the same features built upon the efficiency improvements of the Maxwell architecture.
With that in mind, along with the hardware/architectural changes we’ve listed earlier, the other big factor that sets Maxwell 2 apart from Maxwell 1 is its feature set. In that respect Maxwell 2 is almost a half-generational update on its own, as it implements a number of new features that were not present in Maxwell 1. This means Maxwell 2 is bringing some new features that we need to cover, but it also means that the GM204 based GTX 900 series is feature differentiated from the GTX 600/700 series in a way that the earlier GTX 750 series was not.
Direct3D 11.3
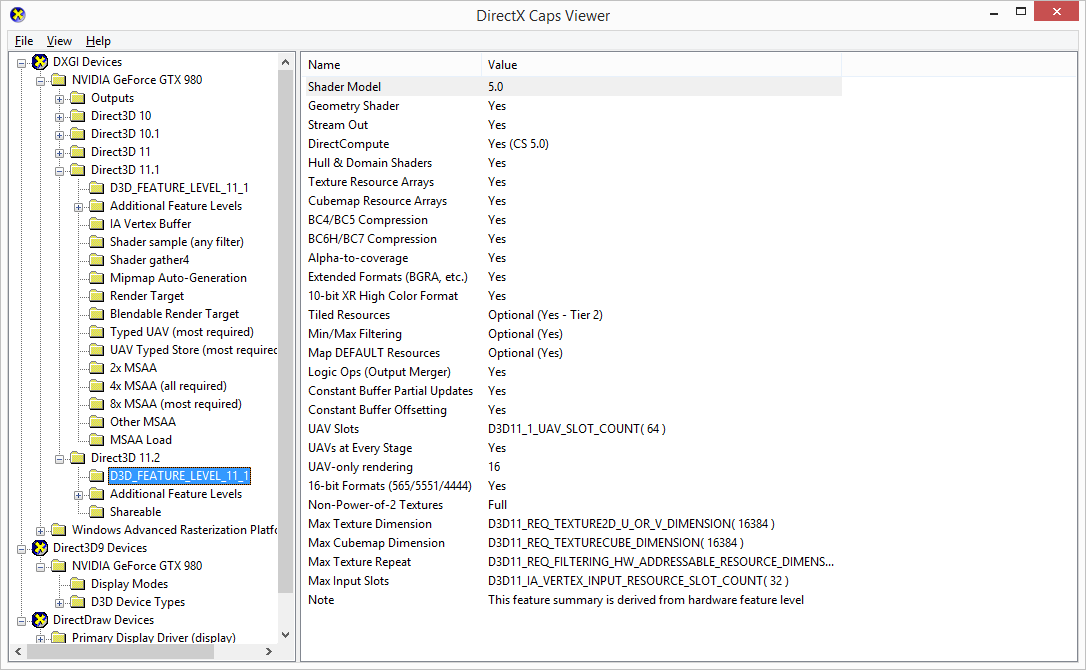
First and foremost among Maxwell 2’s new features is the inclusion of full Direct3D 11.2/11.3 compatibility. Kepler and Maxwell 1 before it were officially feature level 11_0, but they contained an almost complete set of FL 11_1 features, allowing most of these features to be accessed through cap bits. With Maxwell 2 however, NVIDIA has finally implemented the remaining features required for FL11_1 compatibility and beyond, updating their architecture to support the 16x raster coverage sampling required for Target Independent Rasterization and UAVOnlyRenderingForcedSampleCount.
This extended feature set also extends to Direct3D 11.2, which although it doesn’t have an official feature level of its own, does introduce some new (and otherwise optional) features that are accessed via cap bits. Key among these, Maxwell 2 will support the more advanced Tier 2 tiled resources, otherwise known as sparse textures or partially resident textures. Tier 2 was introduced into the specification to differentiate the more capable AMD implementation of this feature from NVIDIA’s hardware, and now as of Maxwell 2 NVIDIA can support the more advanced functionality required for Tier 2.
Finally, Maxwell will also support the features being introduced in Direct3D 11.3 (and made available to D3D 12), which was announced alongside Maxwell at NVIDIA’s editors’ day event. We have a separate article covering Direct3D 11.3, so we won’t completely retread that ground here, but we will cover the highlights.
The forthcoming Direct3D 11.3 features, which will form the basis (but not entirety) of what’s expected to be feature level 11_3, are Rasterizer Ordered Views, Typed UAV Load, Volume Tiled Resources, and Conservative Rasterization. Maxwell 2 will offer full support for these forthcoming features, and of these features the inclusion of volume tiled resources and conservative rasterization is seen as being especially important by NVIDIA, particularly since NVIDIA is building further technologies off of them.
Volume tiled resources is for all intents and purposes tiled resources extended into the 3rd dimension. Volume tiled resources are primarily meant to be used with 3D/volumetric pixels (voxels), with the idea being that with sparse allocation, volume tiles that do not contain any useful information can avoid being allocated, avoiding tying up memory in tiles that will never be used or accessed. This kind of sparse allocation is necessary to make certain kinds of voxel techniques viable.

Meanwhile conservative rasterization is also new to Maxwell 2. Conservative rasterization is essentially a more accurate but performance intensive solution to figuring out whether a polygon covers part of a pixel. Instead of doing a quick and simple test to see if the center of the pixel is bounded by the lines of the polygon, conservative rasterization checks whether the pixel covers the polygon by testing it against the corners of the pixel. This means that conservative rasterization will catch cases where a polygon was too small to cover the center of a pixel, which results in a more accurate outcome, be it better identifying pixels a polygon resides in, or finding polygons too small to cover the center of any pixel at all.
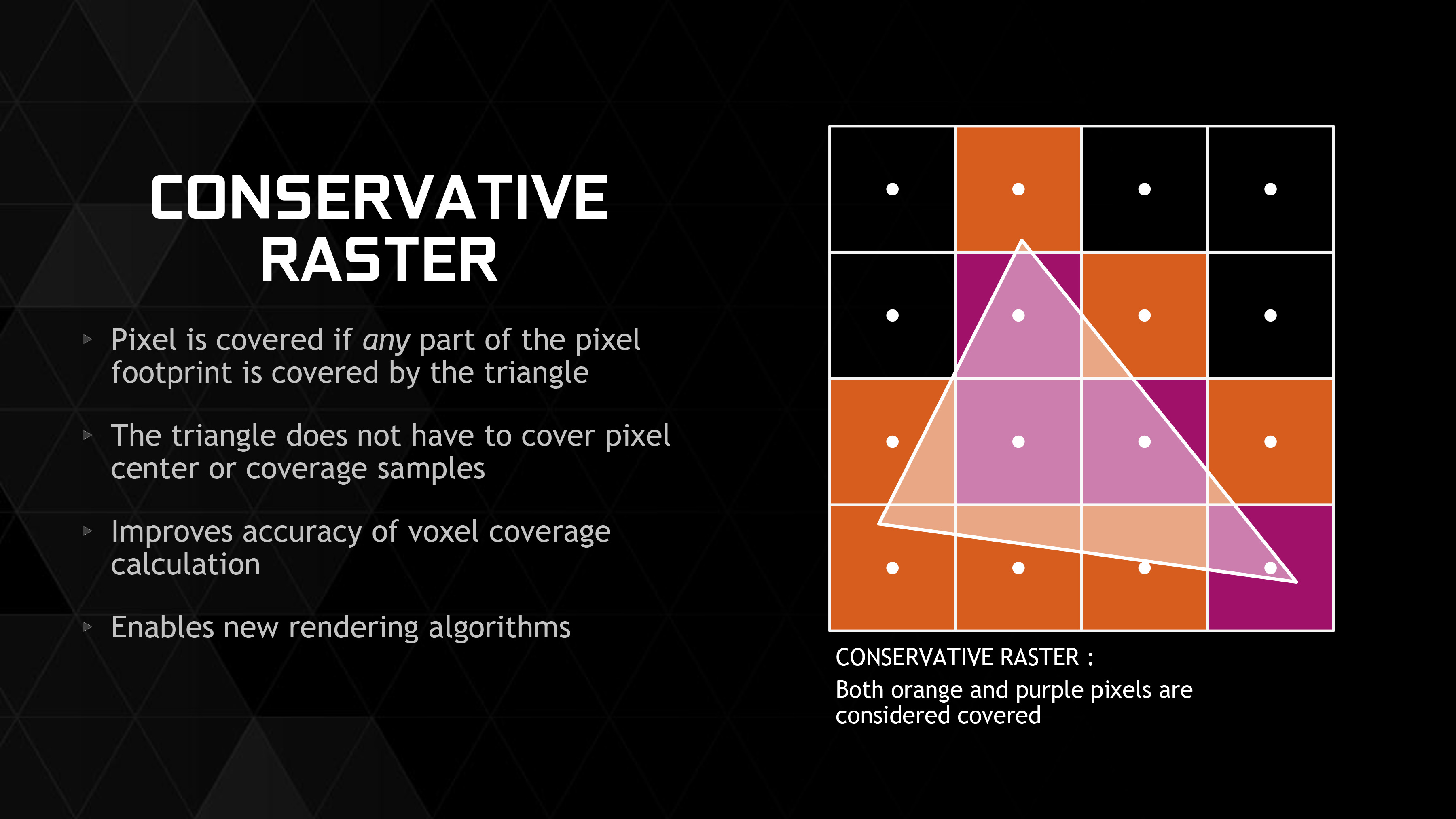
Conservative rasterization is being added to Direct3D in order to allow new algorithms to be used which would fail under the imprecise nature of point sampling. Like VTR, voxels play a big part here as conservative rasterization can be used to build a voxel. However it also has use cases in more accurate tiling and even collision detection. This feature is technically possible in existing hardware, but the performance of such an implementation would be very low as it’s essentially a workaround for the lack of necessary support in the rasterizers. By implementing conservative rasterization directly in hardware, Maxwell 2 will be able to perform the task far more quickly, which is necessary to make the resulting algorithms built on top of this functionality fast enough to be usable.
VXGI
Outside of the features covered by Direct3D 11.3, NVIDIA will also be adding features specifically to drive a new technology they are calling Voxel accelerated Global Illumination (VXGI).
At the highest level, VXGI is a manner of implementing global illumination by utilizing voxels in the calculations. Global illumination is something of a holy grail for computer graphics, as it can produce highly realistic and accurate lighting dynamically in real time. However global illumination is also very expensive, the path tracing involved taking up considerable time and resources. For this reason developers have played around with global illumination in the past – the original version of Epic’s Unreal 4 Engine Elemental demo implanted a voxel based global illumination method, for example – but it has always been too slow for practical use.

With VXGI NVIDIA is looking to solve the voxel global illumination problem through a combination of software and hardware. VXGI proper is the software component, and describes the algorithm being used. NVIDIA has been doing considerable research into voxel based global illumination over the years, and has finally reached a point where they have an algorithm ready to go in the form of VXGI.
VXGI will eventually be made available for Unreal Engine 4 and other major game engines starting in Q4 of this year. And while the VXGI greatly benefits from the hardware features built into Maxwell 2, it is not strictly reliant on the hardware and can be implemented through more traditional means on existing hardware. VXGI is if nothing else scalable, with the algorithm being designed to scale up and down with hardware by adjusting the density of the voxel grid, which in turn influences the number of calculations required and the resulting accuracy. Maxwell 2 for its part will be capable of using denser grids due to its hardware acceleration capabilities, allowing for better performance and more accurate lighting.

It’s at this point we’ll take a break and apologize to NVIDIA’s engineers for blowing through VXGI so quickly. This is actually a really interesting technology, as global illumination offers the possibility of finally attaining realistic real-time lighting in any kind of rendered environment. However VXGI is also a complex technology that is a subject in and of itself, and we could spend all day just covering it (we’d need to cover rasterization and path tracing to fully explain it). Instead we’d suggest reading NVIDIA’s own article on the technology once that is posted, as NVIDIA is ready and willing to go into great detail in how the technology works.
Getting back to today’s launch then, the other aspect of VXGI is the hardware features that NVIDIA has implemented to accelerate the technology. Though a big part of VXGI remains brute forcing through the path and cone tracing, the other major aspect of VXGI is building the voxel grids used in these calculations. It’s here where NVIDIA has pulled together the D3D 11.3 feature set, along with additional hardware features, to greatly accelerate the process of creating the voxel grid in order to speed up the overall algorithm.
From the D3D 11.3 feature set, conservative rasterization and volumetric tiled resources will play a big part. Conservative rasterization allows the creation of more accurate voxels, owing to the more accurate determination of whether a pixel/voxel covers a given polygon. Meanwhile volumetric tiled resources will allow for the space efficient storage of voxels, allowing software to store only the voxels it needs and not the many empty voxels that would otherwise be present in a scene.
Joining these features as the final VXGI-centric feature for Maxwell 2 is a feature NVIDIA is calling Multi-Projection Acceleration. The idea behind MPA is that there are certain scenarios where the same geometry needs to be projected multiple times – voxels being a big case of this due to being 6 sided – and that for performance reasons it is desirable to do all of these projections much more quickly than simply iterating though every necessary projection in shaders. In these scenarios being able to quickly project geometry to all the necessary surfaces is a significant performance advantage.
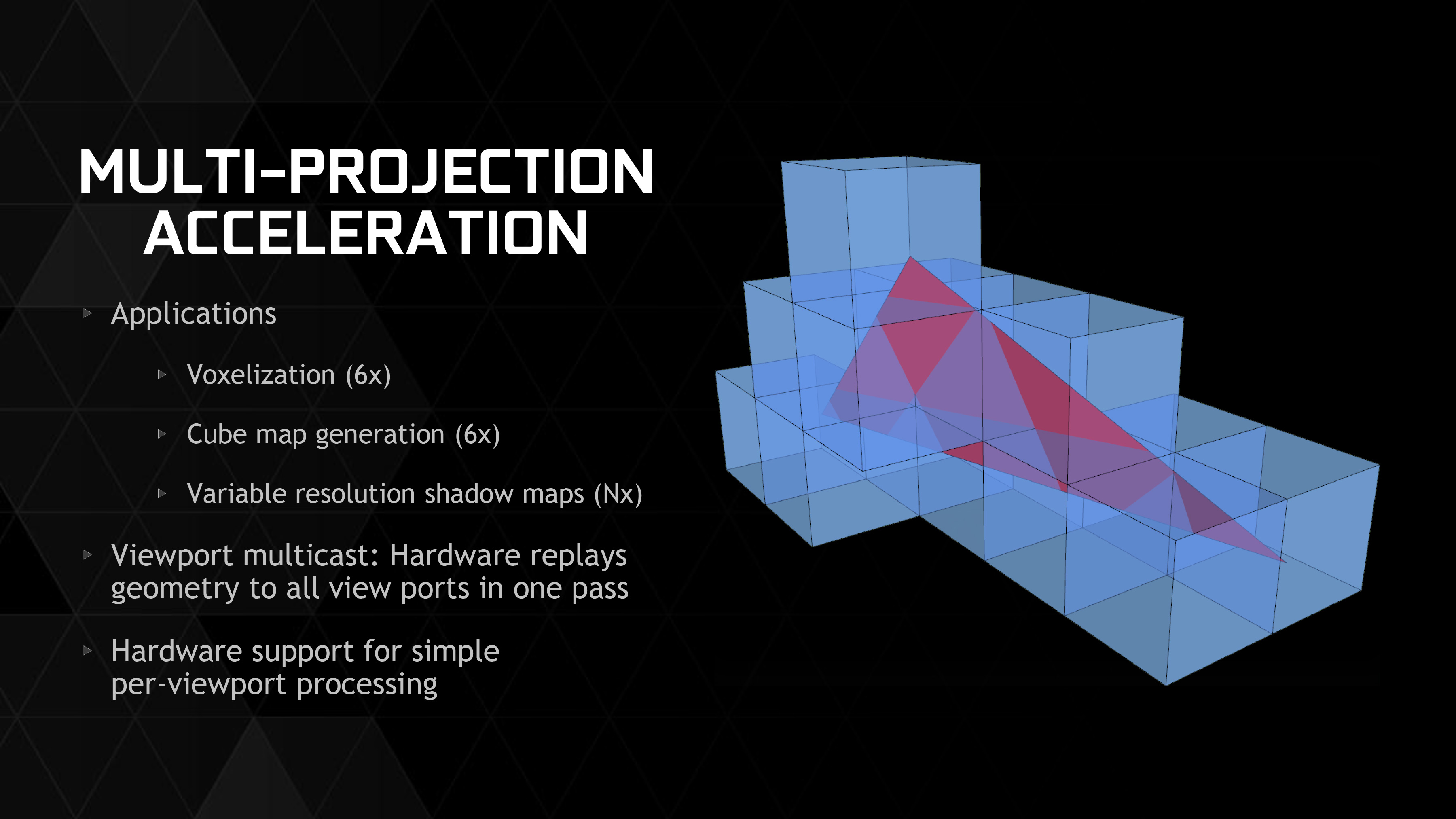
A big part of MPA is a sub-feature called viewport multicast. In viewport multicast Maxwell 2 can replay the necessary geometry to all of the viewports in a single pass. At the hardware level this involves giving the hardware the ability to automatically determine when it needs to engage in viewport multicast, based on its understanding of the workload it's receiving. This is once again a case where something is being done in a fixed-function like fashion for performance reasons, rather than being shuffled off to slower shader hardware.
Alongside voxelization, NVIDIA tells us that MPA should also be applicable to cube map generation and shadow map generation. Both of which make plenty of sense in this case: in both scenarios you are projecting the same geometry multiple times, whether it’s to faces of a cube or to shadow maps of increasing resolution. As a result MPA should have some benefits even in renderers that aren’t using VXGI, though clearly the greatest benefits are still going to be when VXGI is in play.
NVIDIA believes that the overall performance improvement to voxelization from these technologies will be very significant. In their own testing of the technology in rendering a scene set in San Miguel de Allende, Mexico (a common test scene for global illumination), NVIDIA has found that Maxwell 2’s hardware acceleration features tripled their voxelization performance.
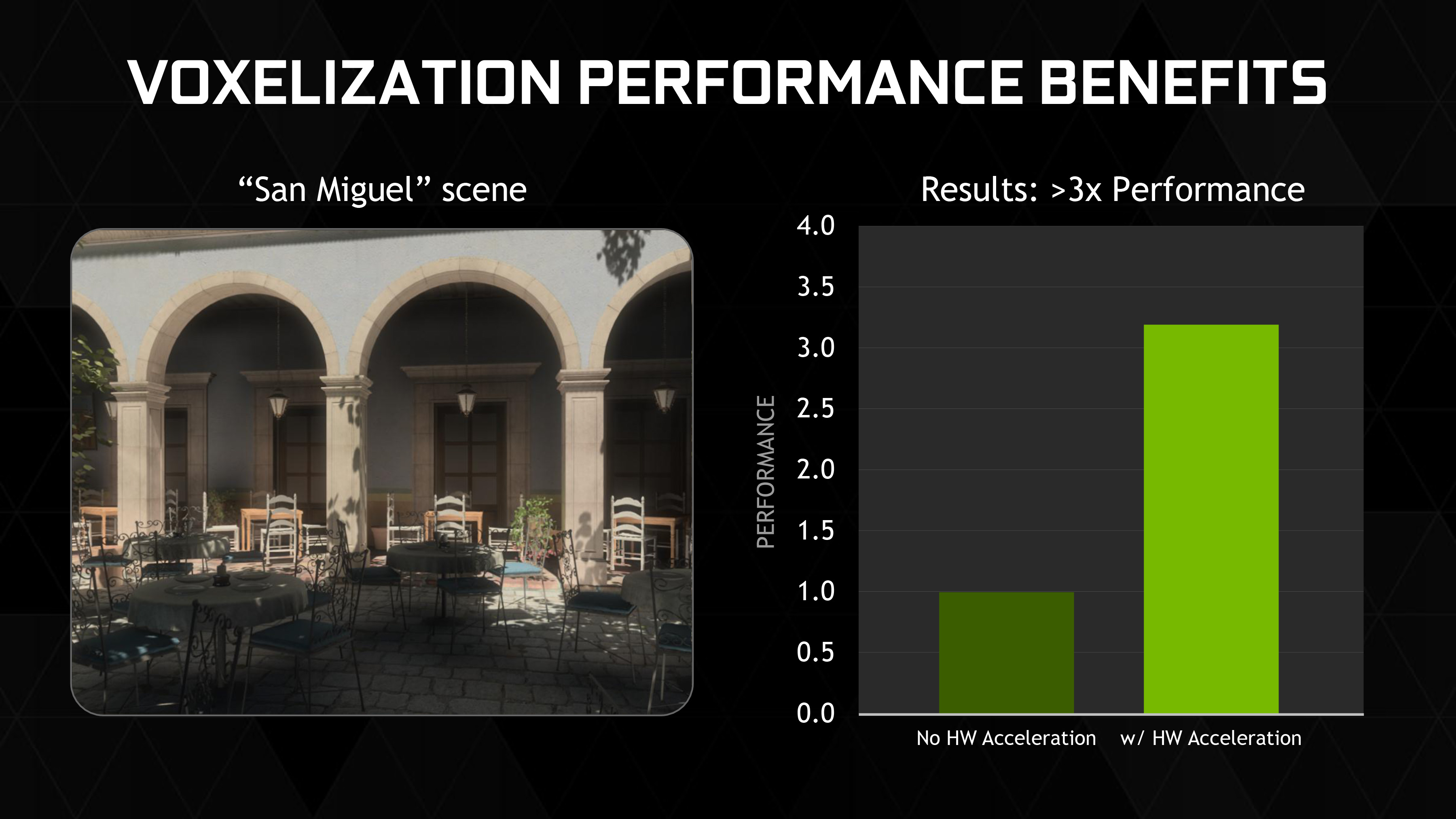
Overall NVIDIA is heavily betting on VXGI at this time both to further set apart Maxwell 2 based cards from the competition, and to further advance the state of PC graphics. In the gaming space in particular NVIDIA has a significant interest in making sure PC games aren’t just straight console ports that run at higher framerates and resolutions. This is the situation that has spurred on the development of GameWorks and technologies like VXGI, so that game developers can enhance the PC ports of their games with technologies that improve their overall rendering quality. Maxwell 2 in turn is the realization that while some of these features can be performed in software/shaders on today’s hardware, these features will be even more useful and impressive when backed with dedicated hardware to improve their performance.
Finally, we’ll close out our look at VXGI with a preview of NVIDIA’s GTX 900 series tech demo, which is a rendered recreation of a photo/scene involving Buzz Aldrin and the Apollo 11 moon landing. The Apollo 11 demo is designed to show off the full capabilities of VXGI, utilizing the lighting technique to correctly and dynamically emulate specular, diffuse, and other forms of lighting that occur in reality. At editors’ day NVIDIA originally attempted to pass off the rendering as the original photo, and while after a moment it’s clear that it’s a rendering – among other things it lacks the graininess of a 1969 film based camera – it comes very, very close. In showcasing the Apollo 11 tech demo, NVIDIA’s hope is that one day games will be able to achieve similarly accurate lighting effects through the use of VXGI.
















274 Comments
View All Comments
garadante - Sunday, September 21, 2014 - link
What might be interesting is doing a comparison of video cards for a specific framerate target to (ideally, perhaps it wouldn't actually work like this?) standardize the CPU usage and thus CPU power usage across greatly differing cards. And then measure the power consumed by each card. In this way, couldn't you get a better example ofgaradante - Sunday, September 21, 2014 - link
Whoops, hit tab twice and it somehow posted my comment. Continued:couldn't you get a better example of the power efficiency for a particular card and then meaningful comparisons between different cards? I see lots of people mentioning how the 980 seems to be drawing far more watts than it's rated TDP (and I'd really like someone credible to come in and state how heat dissipated and energy consumed are related. I swear they're the exact same number as any energy consumed by transistors would, after everything, be released as heat, but many people disagree here in the comments and I'd like a final say). Nvidia can slap whatever TDP they want on it and it can be justified by some marketing mumbo jumbo. Intel uses their SDPs, Nvidia using a 165 watt TDP seems highly suspect. And please, please use a nonreference 290X in your reviews, at least for a comparison standpoint. Hasn't it been proven that having cooling that isn't garbage and runs the GPU closer to high 60s/low 70s can lower power consumption (due to leakage?) something on the order of 20+ watts with the 290X? Yes there's justification in using reference products but lets face it, the only people who buy reference 290s/290Xs were either launch buyers or people who don't know better (there's the blower argument but really, better case exhaust fans and nonreference cooling destroys that argument).
So basically I want to see real, meaningful comparisons of efficiencies for different cards at some specific framerate target to standardize CPU usage. Perhaps even monitoring CPU usage over the course of the test and reporting average, minimum, peak usage? Even using monitoring software to measure CPU power consumption in watts (as I'm fairly sure there are reasonably accurate ways of doing this already, as I know CoreTemp reports it as its probably just voltage*amperage, but correct me if I'm wrong) and reported again average, minimum, peak usage would be handy. It would be nice to see if Maxwell is really twice as energy efficient as GCN1.1 or if it's actually much closer. If it's much closer all these naysayers prophesizing AMD's doom are in for a rude awakening. I wouldn't put it past Nvidia to use marketing language to portray artificially low TDPs.
silverblue - Sunday, September 21, 2014 - link
Apparently, compute tasks push the power usage way up; stick with gaming and it shouldn't.fm123 - Friday, September 26, 2014 - link
Don't confuse TDP with power consumption, they are not the same thing. TDP is for designing the thermal solution to maintain the chip temperature. If there is more headroom in the chip temperature, then the system can operate faster, consuming more power."Intel defines TDP as follows: The upper point of the thermal profile consists of the Thermal Design Power (TDP) and the associated Tcase value. Thermal Design Power (TDP) should be used for processor thermal solution design targets. TDP is not the maximum power that the processor can dissipate. TDP is measured at maximum TCASE"
https://www.google.com/url?sa=t&source=web&...
NeatOman - Sunday, September 21, 2014 - link
I just realized that the GTX 980 has a TDP of 165 watts, my Corsair CX430 watt PSU is almost overkill!, that's nuts. That's even enough room to give the whole system a very good stable overclock. Right now i have a pair of HD 7850's @ stock speed and a FX-8320 @ 4.5Ghz, good thing the Corsair puts out over 430 watts perfectly clean :)Nfarce - Sunday, September 21, 2014 - link
While a good power supply, you are leaving yourself little headroom with 430W. I'm surprised you are getting away with it with two 7850s and not experiencing system crashes.ET - Sunday, September 21, 2014 - link
The 980 is an impressive feat of engineering. Fewer transistors, fewer compute units, less power and better performance... NVIDIA has done a good job here. I hope that AMD has some good improvements of its own under its sleeve.garadante - Sunday, September 21, 2014 - link
One thing to remember is they probably save a -ton- of die area/transistors by giving it only what, 1/32 double precision rate? I wonder how competitive in terms of transistors/area an AMD GPU would be if they gutted double precision compute and went for a narrower, faster memory controller.Farwalker2u - Sunday, September 21, 2014 - link
I am looking forward to your review of the GTX 970 once you have a compatible sample in hand.I would like to see the results of the Folding @Home benchmarks. It seems that this site is the only one that consistently use that benchmark in its reviews.
As a "Folder" I'd like to see any indication that the GTX 970, at a cost of $330 and drawing less watts than a GTX 780; may out produce both the 780 ($420 - $470) and the 780Ti ($600). I will be studying the Folding @ Home: Explicit, Single Precision chart which contains the test results of the GTX 970.
Wolfpup - Monday, September 22, 2014 - link
Wow, this is impressive stuff. 10% more performance from 2/3 the power? That'll be great for desktops, but of course even better for notebooks. Very impressed they could pulll off that kind of leap on the same process!They've already managed to significantly bump up the top end mobile part from GTX 680 -> 880, but within a year or so I bet they can go quite a bit higher still.
Oh well, it was nice having a top of the line mobile GPU for a while LOL
If 28nm hit in 2012 though, doesn't that make 2015 its third year? At least 28nm seems to be a really good process, vs all the issues with 90/65nm, etc., since we're stuck on it so long.
Isn't this Moore's Law hitting the constraints of physical reality though? We're taking longer and longer to get to progressively smaller shrinks in die size, it seems like...
Oh well, 22nm's been great with Intel and 28's been great with everyone else!