The NVIDIA GeForce GTX 980 Review: Maxwell Mark 2
by Ryan Smith on September 18, 2014 10:30 PM ESTMaxwell 2 Architecture: Introducing GM204
Now that we’ve had a chance to recap Maxwell 1 and what went into that architecture, let’s talk about the first of the second generation Maxwell GPUs, the GM204.
GM204 may be a second generation Maxwell part, but it is without question still a Maxwell part. Maxwell has learned some new tricks that we are going to cover here, but functionally speaking you can consider GM204 to be a bigger version of GM107, taking more SMMs and more ROP/memory partitions and using them to build a bigger, more powerful GPU.
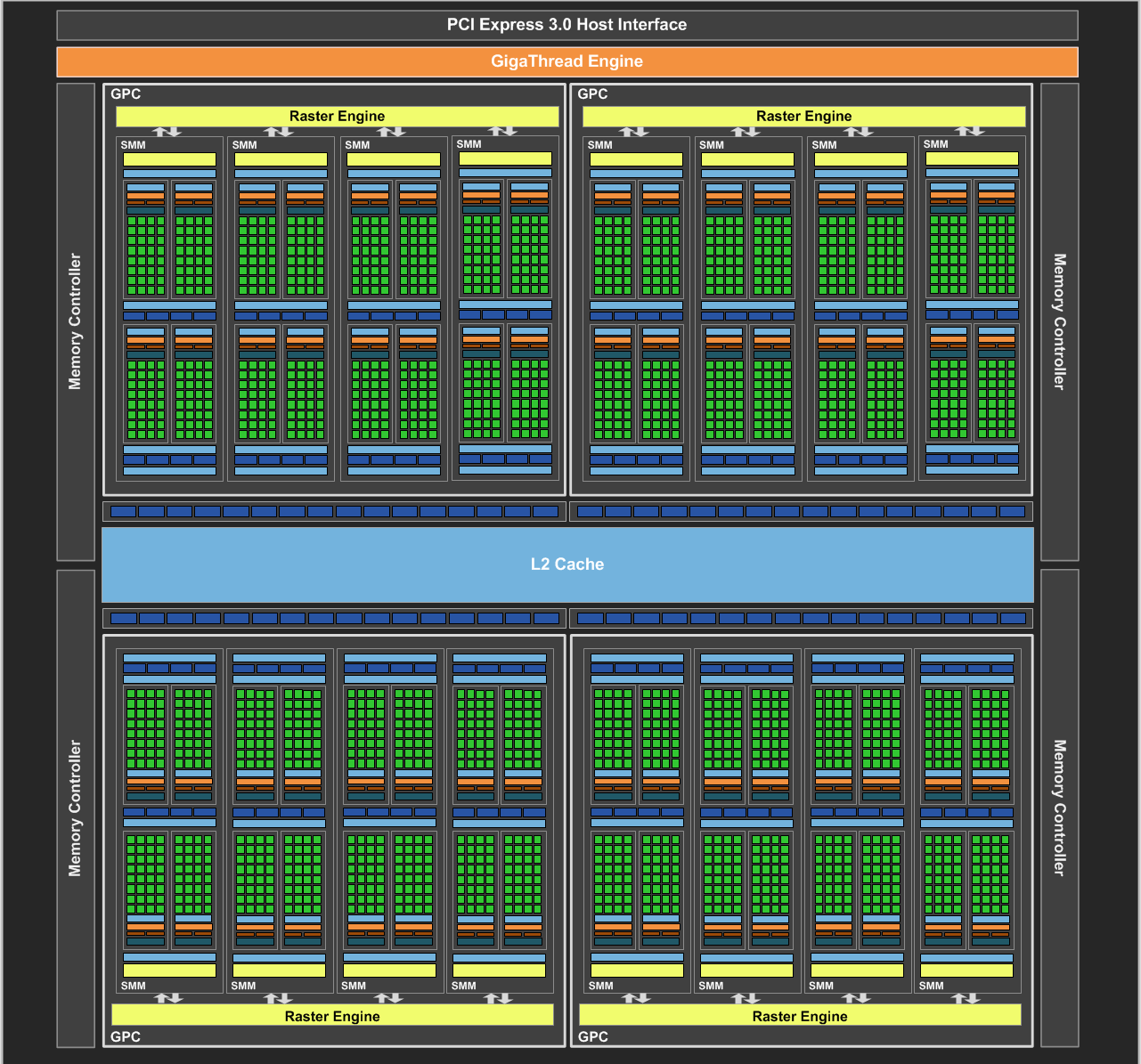
With GM107 being built from 5 SMMs, GM204 is a bit more than a triple GM107. Altogether NVIDIA is building GM204 out of 16 SMMs, this time divided up into 4 GPCs instead of GM107’s single GPC. This is bound to 64 ROPs and 4 64bit memory controllers, which is a 4x increase in the number of ROPs compared to GM107, and a 2x increase in the memory bus size.
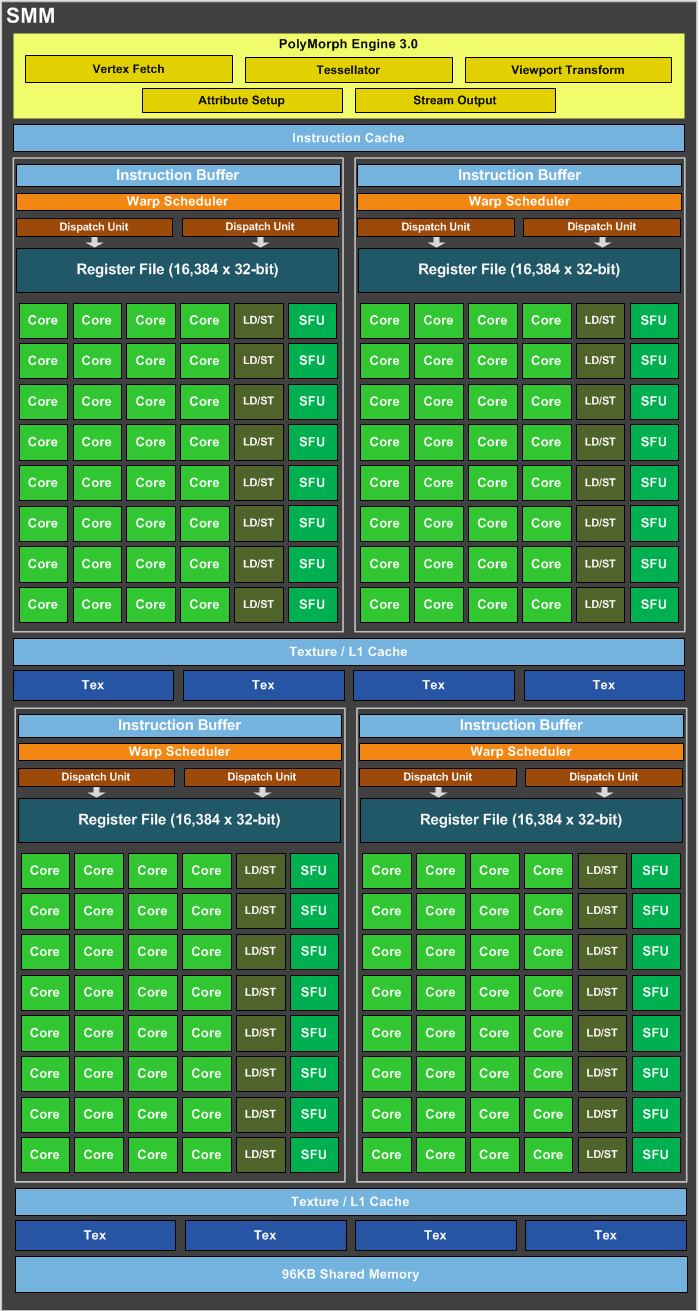
Drilling down to the SMMs for a second, there are a couple of small changes that need to be noted. Organizationally the GM204 SMM is identical to the GM107 SMM, however GM204 gets 96KB of shared memory versus 64KB on GM107. Separate from the combined L1/texture cache, this shared memory services a pair of SMMs and their associated texture units to further reduce the need to go to L2 cache or beyond.
The Polymorph Engines have also been updated. There are not any major performance differences with the 3.0 engines, but they are responsible for implementing some of the new functionality we’ll reference later.
Other than this, GM204’s SMM is identical to the GM107 SMM. This includes the use of 4 shared texture units per 2 SMMs, leading to a 16:1 compute-to-texture ratio, and a 512Kb register file for each SMM.
Compared to GK104 of course this is a more remarkable change. Compared to its immediate predecessor, GM204 sees significant differences in both the layout of the SMM and of the resulting chip, which means that even before accounting for feature differences we can’t just start counting functional units and directly comparing GM204 to GK104. GM204 is overall a more efficient chip, and although it possesses just 33% more CUDA cores than GK104 its performance advantage is much greater, on the order of 50% or more, highlighting the fact that NVIDIA is getting more work out of their CUDA cores than ever before. Altogether, NVIDIA tells us that on average they’re getting 40% more performance per core, which is one of the reasons why GTX 980 can beat even the full GK110 based GTX 780 Ti, with its 2880 CUDA cores.
Compute hardware aside, fleshing out GM204 is of course the ROP/memory partitions. Although the constituent hardware hasn’t changed much – we’re still looking at 7GHz GDDR5 memory controllers and the same pixel throughput per ROP – GM204 is very atypical for its configuration of these parts.
Until now, high-end NVIDIA designs have used an 8:1 ratio; 8 ROPs (or rather ROPs that process 8 pixels per clock) paired up with each 64bit memory controller. This gave GK104 32 ROPs, GK110 48 ROPs, and GM107 16 ROPs. However beginning with GM204 NVIDIA has increased the ROP-to-memory ratio and as a result has doubled their total ROP count compared to GK104. GM204 features a 16:1 ratio, giving us our first NVIDIA GPU with 64 ROPs.
Now the subject of ROPs is always a dicey one because of the nature of pixel operations. Unlike compute hardware, which can be scaled up rather effectively with more complex workloads and better caching methods, the same is not true for ROPs. ROPs are the ultimate memory bandwidth burner. They are paired with memory controllers specifically because the work they do – the Z testing, the pixel blending, the anti-aliasing – devours immense amounts of bandwidth. As a result, even if you are bottlenecked by ROP performance increasing the ROP count won’t necessarily be performance effective if those ROPs are going to be bandwidth starved.
| NVIDIA ROP To Memory Controller Ratios | |||||
| GPU | ROP:MC Ratio | Total ROPs | |||
| Maxwell (GM204) | 16:1 | 64 | |||
| Maxwell (GM107) | 8:1 | 16 | |||
| Kepler (GK110) | 8:1 | 48 | |||
| Fermi (GF110) | 8:1 | 48 | |||
| GT200 | 4:1 | 32 | |||
The last time NVIDIA increased their ROP ratio was for Fermi, when it went from 4:1 to 8:1. This was largely fueled by the introduction of GDDR5, whose higher data rates provided the bandwidth necessary to feed the greater number of ROPs. Since then GDDR5 clockspeeds have increased a bit for NVIDIA, from 4GHz to 7GHz, but so have ROP clockspeeds as well, meaning there hasn’t been a significant change in the ability for NVIDIA’s memory controllers to feed their ROPs since Fermi.
Consequently making the jump to a 16:1 means that change would need to happen somewhere else. This has led to NVIDIA approaching the problem from the other direction: instead of increasing the available memory bandwidth, what can they do to reduce it?
Color Compression
The solution, and really the key to making a 16:1 ROP ratio feasible, is the latest generation of NVIDIA’s delta color compression technology. Color compression in and of itself is not new technology, but over successive hardware generations NVIDIA has continued to iterate on it, and as such has continued to increase the amount of data they can compress.
NVIDIA first introduced color compression on the GeForce FX series, where it could compress data at up to a 4:1 ratio. The actual compressibility of any frame would in turn depend on the contents of the frame. At a most basic level NVIDIA would break down a frame into regions and then attempt to find smaller portions of redundant data to compress. Anti-aliasing was especially favorable here, as anti-aliasing samples would frequently all be of a fully covered triangle, resulting in all pixels being identical. In the case of regular color compression the key is finding whole regions of identical colors, at which point you could potentially compress them down by as much as 8:1.

More recently, in Fermi NVIDIA introduced delta color compression, which is designed to take color compression beyond simple regions containing identical pixels. Delta color compression is essentially focused on pattern compression instead of region compression, compressing based on the differences (delta) between pixels rather than how they’re identical; if you can describe how the pixels will differ from one-another, then you can save space describing the delta instead of the individual pixel. Delta color compression works off of the same blocks and essentially applies different delta patterns to them, attempting to find the best pattern for the block.
Delta compression is by its nature less efficient than whole color compression, topping out at just 2:1 compared to 8:1 for the latter. However a 2:1 ratio is still potentially a 50% reduction in data size, which is far better than letting the data go uncompressed. At 4x2 32bit pixels per region, this would mean reducing a region from 32 bytes to 16 bytes.
NVIDIA’s 3rd generation of color compression then is the latest iteration on this technology. The fundamentals between the various generations of delta color compression have not changed, but with each iteration NVIDIA has gained the ability to apply more and more patterns to the blocks to find better matches. 3rd generation delta color compression offers the most patterns yet, and the most opportunity to compress pixel blocks.
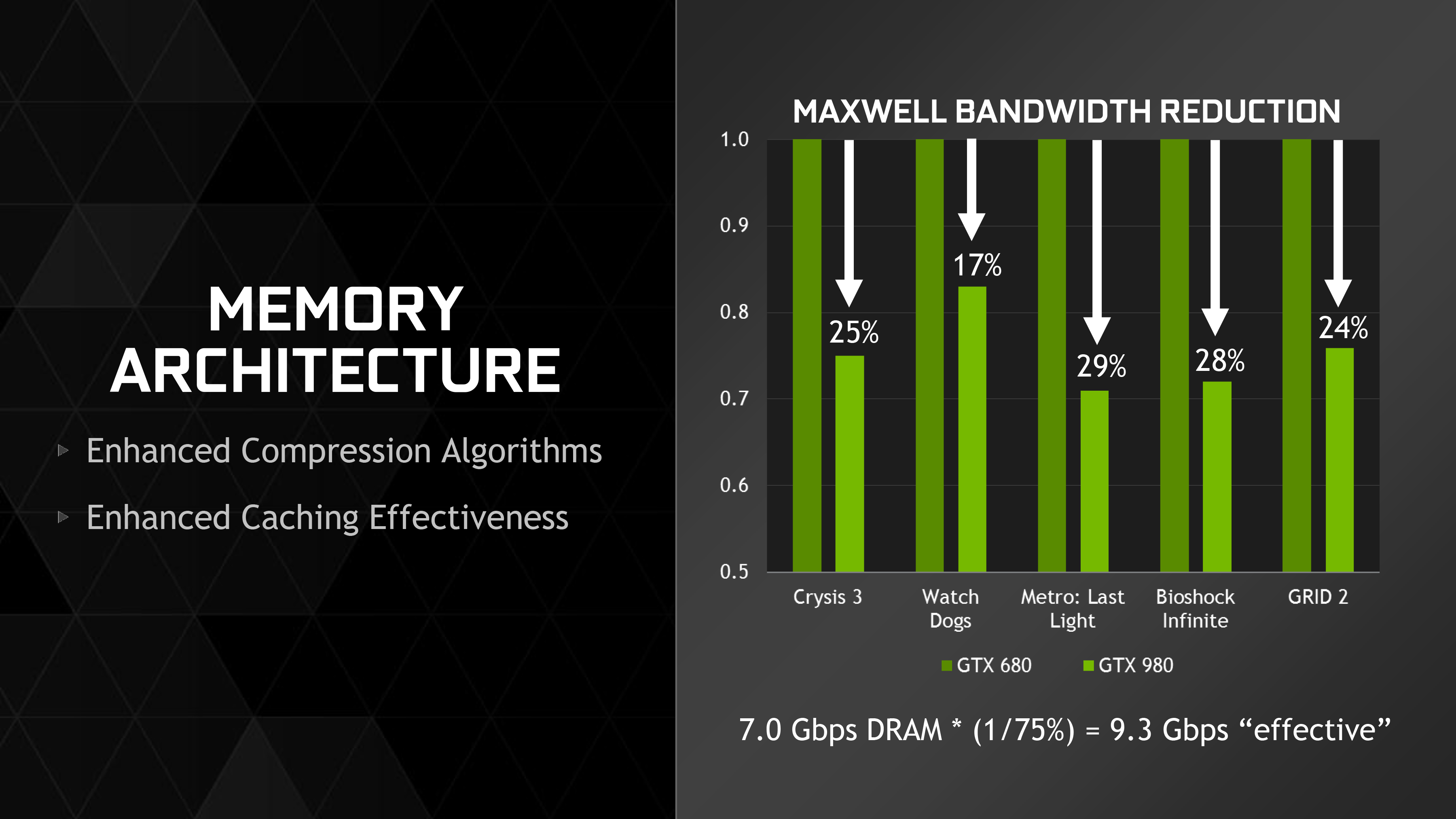
The importance of color compression cannot be understated. The impact of 3rd generation delta color compression is enough to reduce NVIDIA’s bandwidth requirements by 25% over Kepler, and again this comes just from having more delta patterns to choose from. In fact color compression is so important that NVIDIA will actually spend multiple cycles trying different compression ratios, simply because the memory bandwidth is more important than the computational time.
Getting back to our ROPs then, it’s the introduction of 3rd generation color compression, which alongside the larger 2MB L2 cache, makes a 16:1 ROP ratio on GM204 viable. Being able to feed 64 ROPs in turn helps NVIDIA’s overall performance, especially at higher resolutions. With 4K monitors taking off NVIDIA needs to be able to offer competitive performance at those resolutions, and while doubling the number of ROPs won’t double NVIDIA’s performance, it none the less is an essential part of being able to scale up performance for the needs of 4K. AMD for their part already went to 64 ROPs on their high-end GPU with Hawaii last year, and while the subject isn’t nearly as simple as just comparing ROP counts, it was one of the factors that resulted in the superior 4K performance scaling we saw from Hawaii cards.
Die Size & Power
Last but certainly not least, now that we’ve had a chance to discuss the architecture of GM204, let’s talk about its physical properties.
One of the problems posed by remaining on the 28nm process is that increasing CUDA core counts will result in larger GPUs. NVIDIA has actually done quite a bit of work on chip density, and as a result the increase in chip size is not going to be as great as the increase in the underlying hardware. Still, GM204 is a more powerful and more complex chip than GK104, and as a result die size and transistor count has gone up.

GM204 ends up weighing in at 5.2 billion transistors, with a die size of 398mm2. This compares to 3.54B transistors and a die size of 294mm2 for GK104, and 7.1B transistors and 551mm2 for GK110. Compared to either Kepler design the overall transistor density is improved, albeit not significantly so.
More important is the fact that GM204 ends up being NVIDIA’s largest xx4 class GPU. xx4 GPUs are typically NVIDIA’s midrange to high-end consumer workhorses, designed first and foremost for graphics and not packing the advanced compute features such as high speed FP64 and ECC memory support that we see in the big x00/x10 GPUs. For cost and overlap reasons NVIDIA’s sweet spot up until now has been around 300-350mm2, with GK104 coming in a hair ahead of the curve. But at just shy of 400mm2, GM204 is encroaching on newer, larger territory.
To some degree this is an inevitable result of remaining on the 28nm process. More performance requires more transistors, and as a result die size was destined to go up. None the less the fact that NVIDIA is fabricating such a large GPU as an xx4 GPU is remarkable. It provides a good example of just how much hardware (in terms of transistors) NVIDIA had to throw in to reach their performance goals. Alternatively, it’s telling that NVIDIA is now going to be able to use a 398mm2 chip as the basis of their high-end consumer video card, as opposed to having to use a 551mm2 chip in the form of GK110.
What’s particularly interesting though is that despite the big die, NVIDIA’s power consumption is exceptionally low. By historical standards GK104 was already a low power GPU for its size, this being the case particularly for GTX 680. GTX 680 was a 195W TDP part with a GPU Boost 1.0 power target of 170W. The GM204 based GTX 980 on the other hand, despite packing in nearly 1.5B more transistors for another 104mm2 of die size, actually consumes less power than said GK104 based card. At 165W TDP NVIDIA’s energy efficiency optimizations are in full effect, and it means NVIDIA consumes surprisingly little power for such a large GPU.
Impressively, all of this comes at the same time that NVIDIA is clocking the GPU at over 1.2GHz. This means we are not looking at a simple case of wide-and-slow, as is often the case for power optimized GPUs (see: SoCs). NVIDIA is clocking GM204 high and hitting it with over 1.2v, and yet it’s still able to maintain a 165W TDP in spite of its large die size. We’ll look at the competitive ramifications of this later, but to keep power consumption so low on such a large GPU really is a feather in NVIDIA’s cap.








274 Comments
View All Comments
TheJian - Saturday, September 20, 2014 - link
http://blogs.nvidia.com/blog/2014/09/19/maxwell-an...Did I miss it in the article or did you guys just purposely forget to mention NV claims it does DX12 too? see their own blog. Microsoft's DX12 demo runs on ...MAXWELL. Did I just miss the DX12 talk in the article? Every other review I've read mentions this (techpowerup, tomshardware, hardocp etc etc). Must be that AMD Center still having it's effect on your articles ;)
They were running a converted elemental demo (converted to dx12) and Fable Legends from MS. Yet curiously missing info from this site's review. No surprise I guess with only an AMD portal still :(
From the link above:
"Part of McMullen’s presentation was the announcement of a broadly accessible early access program for developers wishing to target DX12. Microsoft will supply the developer with DX12, UE4-DX12 and the source for Epic’s Elemental demo ported to run on the DX12-based engine. In his talk, McMullen demonstrated Maxwell running Elemental at speed and flawlessly. As a development platform for this effort, NVIDIA’s GeForce GPUs and Maxwell in particular is a natural vehicle for DX12 development."
So maxwell is a dev platform for dx12, but you guys leave that little detail out so newbs will think it doesn't do it? Major discussion of dx11 stuff missing before, now up to 11.3 but no "oh and it runs all of dx12 btw".
One more comment on 980: If it's a reference launch how come other sites already have OC versions (IE, tomshardware has a Windforce OC 980, though stupidly as usual they downclocked it and the two OC/superclocked 970's they had to ref clocks...ROFL - like you'd buy an OC card and downclock them)? IT seems to be a launch of OC all around. Newegg even has them in stock (check EVGA OC version):
http://www.newegg.com/Product/Product.aspx?Item=N8...
And with a $10 rebate so only $559 and a $5 gift card also.
"This model is factory overclocked to 1241 MHz Base Clock/1342 MHz Boost Clock (1126 MHz/1216 MHz for reference design)"
Who would buy ref for $10 diff? IN fact the ref cards are $569 at newegg, so you save buying the faster card...LOL.
cactusdog - Saturday, September 20, 2014 - link
TheJian, Wow, Did you read the article? Did you read the conclusion? AT says the 980 is "remarkable" , "well engineered", "impeccable design" and has "no competition" They covered almost all of Nvidia marketing talking points and you're going to accuse them of a conspiracy? Are you fking retarded??Daniel Egger - Saturday, September 20, 2014 - link
It would be nice to rather than just talk about about the 750 Ti to also include it in comparisons to see it clearer in perspective what it means to go from Maxwell I to Maxwell II in terms of performance, power consumption, noise and (while we are at it) performance per Watt and performance per $.Also where're the benchmarks for the GTX 970? I sure respect that this card is in a different ballpark but the somewhat reasonable power output might actually make the GTX 970 a viable candidate for an HTPC build. Is it also possible to use it with just one additional 6 Pin connector (since as you mentioned this would be within the specs without any overclocking) or does it absolutely need 2 of them?
SkyBill40 - Saturday, September 20, 2014 - link
As was noted in the review at least twice, they were having issues with the 970 and thus it won't be tested in full until next week (along with the 980 in SLI).MrSpadge - Saturday, September 20, 2014 - link
Wow! This makes me upgrade from a GTX660Ti - not because of gaming (my card is fast enough for my needs) but because of the power efficiency gains for GP-GPU (running GPU-Grid under BOINC). Thank you nVidia for this marvelous chip and fair prices!jarfin - Saturday, September 20, 2014 - link
i still CANT understand amd 'uber' option.its totally out of test,bcoz its just 'oc'd' button,nothing else.
its must be just r290x and not anantech 'amd canter' way uber way.
and,i cant help that feeling,what is strong,that anatech is going badly amd company way,bcoz they have 'amd center own sector.
so,its mean ppl cant read them review for nvidia vs radeon cards race without thinking something that anatech keep raden side way or another.
and,its so clear thats it.
btw
i hope anantech get clear that amd card R9200 series is just competition for nvidia 90 series,bcoz that every1 kow amd skippedd 8000 series and put R9 200 series for nvidia 700 series,but its should be 8000 series.
so now,generation of gpu both side is even.
meaning that next amd r9 300 series or what it is coming amd company battle nvidia NEXT level gpu card,NOT 900 series.
there is clear both gpu card history for net.
thank you all
p.s. where is nvidia center??
Gigaplex - Saturday, September 20, 2014 - link
Uber mode is not an overclock. It's a fan speed profile change to reduce thermal throttling (underclock) at the expense of noise.dexgen - Saturday, September 20, 2014 - link
Ryan, Is it possible to see the average clock speeds in different tests after increasing the power and temperature limit in afterburner?And also once the review units for non-reference cards come in it would be very nice to see what the average clock speeds for different cards with and without increased power limit would be. That would be a great comparison for people deciding which card to buy.
silverblue - Saturday, September 20, 2014 - link
Exceptional by NVIDIA; it's always good to see a more powerful yet more frugal card especially at the top end.AMD's power consumption could be tackled - at least partly - by some re-engineering. Do they need a super-wide memory bus when NVIDIA are getting by with half the width and moderately faster RAM? Tonga has lossless delta colour compression which largely negates the need for a wide bus, although they did shoot themselves in the foot by not clocking the memory a little higher to anticipate situations where this may not help the 285 overcome the 280.
Perhaps AMD could divert some of their scant resources towards shoring up their D3D performance to calm down some of the criticism because it does seem like they're leaving performance on the table and perhaps making Mantle look better than it might be as a result.
Luke212 - Saturday, September 20, 2014 - link
Where are the SGEMM compute benchmarks you used to put on high end reviews?