Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTCapacity: the New Arms Race
Some of the hottest software trends of today are Big Data and In Memory Business Analytics. Both applications benefit from fast processors, but even more importantly they are virtually unsatiable when it comes to RAM capacity. Another important area that's much closer to the daily work of many IT professionals is virtualization. As heavier applications are being virtualized, the typical amount of memory allocated to virtual machines has increased rapidly. As announced on the latest VMworld, vSphere 6 will now support Virtual machines that allocate up to 4TB (!!) of memory. The days where virtual machines were limited to only a fraction of "native" operating systems are behind us.
With the above developments, support for and development of high capacity DIMMs is crucial. Intel has been steadily improving the support for LRDIMMs (here's some additional information on LRDIMMs). The first Xeon E5-2600 had support for LRDIMMs but it only delivered higher capacity at the expense of lower bandwidth and higher latency. The memory controller of the Xeon E5-2600 v2 had several improvements specifically for LRDIMMs and as a result the latency and throughput tax was greatly reduced.
The advent of DDR4 has given the engineers of IDT the opportunity to give LRDIMMs a performance advantage instead of a disadvantage. By introducing data buffers close to the DRAM chips, they managed to reduce the I/O trace lengths tremendously. See the figure below.
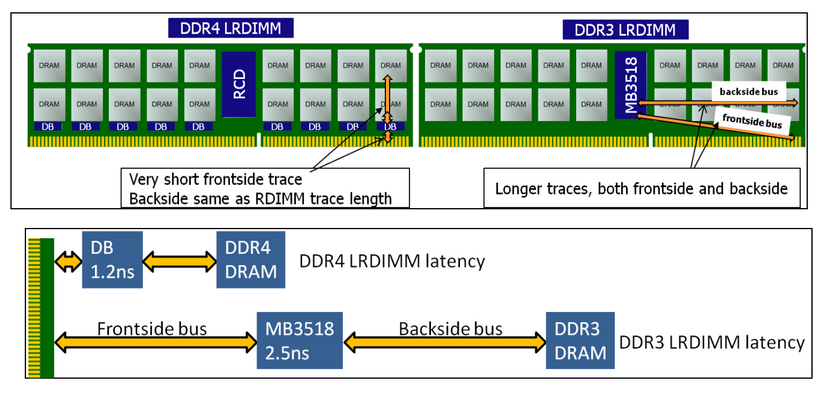
DDR4 and DDR3 LRDIMMs compared, image courtesy of IDT.
The latency overhead of the extra buffering is thus significantly lower on DDR4 LRDIMMs. In other words, compared to Registered DDR4 running at the same speed with 1 DPC (1 DIMM per channel), the latency overhead will be small. As soon as you start to use more DIMMs per channel, LRDIMMs actually offer lower latency as they can run at higher speeds.
Below you can see the evolution of LRDIMM support over the three generations of Xeon E5s. On the far right is the speed of DIMMs on Sandy Bridge EP, in the middle is Ivy Bridge EP, and on the left is the speed of DIMMs on the new Haswell EP Xeon.
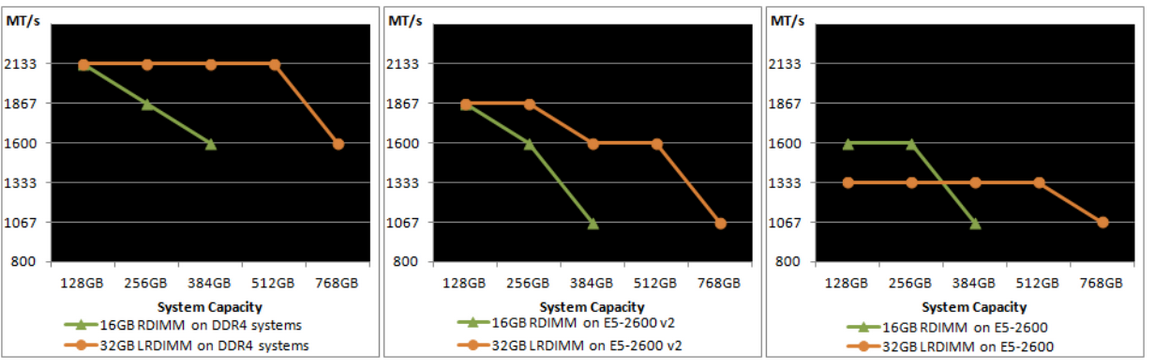
On Sandy Bridge EP (Xeon E5-2600), LRDIMMs were only clocked faster at three DPC. On Ivy Bridge EP (Xeon E5-2600 v2), the LRDIMMs were faster at two and three DPC. And on Haswell EP (Xeon E5-2600 v3), the bandwidth speed gap at two and three DPC has increased while the latency tax (not seen in the picture) has been reduced.

Samsung LRDIMM on top, RDIMM below. Notice the data buffers on the LRDIMM
Several sources tell us that LRDIMMs will be about 20%-25% more expensive. Our task then is to help you decide wether or not the investment is worth it. In this review, we will show some preliminary results.
The latency penalty has been reduced, but what about capacity? As you can see by the 4G marking in the photo above, the DIMMs used in our current servers are still using the mature 4Gbit DRAM chip technology. So currently, the Xeon E5-2600 v2 platform is limited to 384GB of registered DDR4 or 768GB of LRDIMMs. Quad-ranked RDIMMs, which were expensive, slow, and could only be used at 2DPC, are dead. The current 64GB LRDIMMs can be used at 3DPC, but they are Octal (!) ranks using quad-die-packages. As a result they are slow at 3DPC and power hungry.
But the future looks bright. At the end of this year, dual-ranked modules, such as the ones you can see above, will use 8Gb. This results in 64GB LRDIMMs and 32GB RDIMMs. That means the Xeon E5 platform will soon be able to address up to 1.5TB of physical RAM. In the second half of 2015, 128GB LRDIMMs should be available too, allowing up to 3TB of RAM.








85 Comments
View All Comments
Assimilator87 - Tuesday, September 9, 2014 - link
That's great and all, but there's one huge flaw with SPARC processors. They cannot run Crysis.TiGr1982 - Tuesday, September 9, 2014 - link
But for the case of Xeon E5, are you ready to spend several grands to play Crysis?This kind of "joke" about "can it run Crysis" is really several years old, stop posting it please.
quixver - Tuesday, September 9, 2014 - link
SAP Hana is designed to run on a cluster of Linux nodes. And I believe HANA is going to be the only supported data store for SAP. And there are a large number of domains who have moved away from big *nixes. Are there use cases for big iron still? Sure. Are there use cases for commodity Xeon/Linux boxes? Sure. Posts like yours remind me of pitches from IBM/HP/Sun where they do nothing but spread fud.Brutalizer - Wednesday, September 10, 2014 - link
HANA is running on a scale-out cluster yes. But there are workloads that you can not run on a cluster. You need a huge single SMP server, for scaling-up instead. Scale-out (cluster) vs scale-up (one single huge server):https://news.ycombinator.com/item?id=8175726
"...I'm not saying that Oracle hardware or software is the solution, but "scaling-out" is incredibly difficult in transaction processing. I worked at a mid-size tech company with what I imagine was a fairly typical workload, and we spent a ton of money on database hardware because it would have been either incredibly complicated or slow to maintain data integrity across multiple machines...."
"....Generally it's just that [scaling-out] really difficult to do it right. Sometime's it's impossible. It's often loads more work (which can be hard to debug). Furthermore, it's frequently not even an advantage. Have a read of https://research.microsoft.com/pubs/163083/hotcbp1... Remember corporate workloads frequently have very different requirements than consumer..."
So the SPARC M7 server with 64TB in one single huge SMP server will be much faster than a HANA cluster running Enterprise software. Besides, the HANA cluster also tops out at 64TB RAM, just like the SPARC M7 server. An SMP server will always be faster than a cluster, because in a cluster nodes will be far away worst case, than in a tightly knit SMP server.
Here is an article about clusters vs SMP servers by the die-hard IBM fan Timothy Prickett Morgan (yes, IBM supporters hates Oracle):
http://www.enterprisetech.com/2014/02/14/math-big-...
shodanshok - Tuesday, September 9, 2014 - link
The top-of-the-line Haswell-EP discussed in this article costs about 4000$. A single mid-level SPARC T4 CPU costs over 12000$, and a T5 over 20000$. So, what are comparing?Moreover, while SPARC T4/T5 can dedicate all core resource to a single running thread (dynamic threading), the single S3 core powering T4/T5 is relatively simple, with 2 interger ALU and a single, weak FPU (but with some interesting feature, as a dedicated crypto block). In other words, they can not be compared to an Haswell core (read: they are slower).
The M6 CPU comparison is even worse: it costs even more (but I can find no precise number, sorry - and that alone tell much about the comparison story!), but the enlarged L3 cache can not magically solve all performance limitations. The only saving grace, at least for M6 CPU, is that it can address very large memory, with significant implications for those workloads that really need insane RAM amount.
M7 will be release next year - it is useless to throw it into the mix now.
T4/T5 and M6/M7 real competitor is Intel EX serie, which can scale up to 256 sockets if equipped with QPI switchs (while glueless systems scale to 8 sockets) and can address very large RAM. Moreover, the EX serie implement the (paranoid) reliability requirements asked in this very specific market niche.
Regards.
Brutalizer - Wednesday, September 10, 2014 - link
"...In other words, the old S3 core can not be compared to an Haswell core (read: they are slower)..."Well, you do know that the S3 core powered SPARC T5 holds several world records today? For instance, T5 is faster than the Xeon cpus at SPEC2006 cpu benchmarks:
https://blogs.oracle.com/BestPerf/entry/20130326_s...
The reason they benchmark against that particular Xeon E7 model, is because only it scales to 8-sockets, just like the SPARC T5. The E5 does not scale to 8-sockets. So the old S3 core which "does not compare to haswell core" seems to be faster in many benchmarks.
.
.
Intel EX scaling up to 256 sockets is just a cluster. Basically, a SGI Altix or UV2000 server. Clusters will never be able to serve thousands of users running Enterprise software. Such clusters are only fit serving one single user, running HPC number crunching benchmarks for days at a time. No sane person will try to run Enterprise business software on a cluster. Even SGI admits this, talking about their Altix server:
http://www.realworldtech.com/sgi-interview/6/
"...The success of Altix systems in the high performance computing market are a very positive sign for both Linux and Itanium. Clearly, the popularity of large processor count Altix systems dispels any notions of whether Linux is a scalable OS for scientific applications. Linux is quite popular for HPC and will continue to remain so in the future,...However, scientific applications (HPC) have very different operating characteristics from commercial applications (SMP). Typically, much of the work in scientific code is done inside loops, whereas commercial applications, such as database or ERP software are far more branch intensive. This makes the memory hierarchy more important, particularly the latency to main memory. Whether Linux can scale well with a SMP workload is an open question. However, there is no doubt that with each passing month, the scalability in such environments will improve. Unfortunately, SGI has no plans to move into this SMP market, at this point in time..."
Also, ScaleMP confirms that their huge Linux server (also 10.000s of cores, 100TBs of RAM) is also a cluster, capable only of running HPC number crunching workloads:
http://www.theregister.co.uk/2011/09/20/scalemp_su...
"...Since its founding in 2003, ScaleMP has tried a different approach. Instead of using special ASICs and interconnection protocols to lash together multiple server modes together into a SMP shared memory system, ScaleMP cooked up a special software hypervisor layer, called vSMP, that rides atop the x64 processors, memory controllers, and I/O controllers in multiple server nodes....vSMP takes multiple physical servers and – using InfiniBand as a backplane interconnect – makes them look like a giant virtual SMP server with a shared memory space. vSMP has its limits....The vSMP hypervisor that glues systems together is not for every workload, but on workloads where there is a lot of message passing between server nodes – financial modeling, supercomputing, data analytics, and similar parallel workloads. Shai Fultheim, the company's founder and chief executive officer, says ScaleMP has over 300 customers now. "We focused on HPC as the low-hanging fruit..."
You will never find Enterprise benchmarks for the SGI server or other Xeon 256-socket servers such as ScaleMP, such as SAP benchmarks. Because they are clusters. Read the links, if you dont believe me.
shodanshok - Saturday, September 13, 2014 - link
Hi,the 256 socket E7 system is not a cluster: it uses QPI switches to connect the various sockets and it run a single kernel image. After all, clusters scale to 1000s CPU, while single-image E7 systems are limited to 256 sockets max.
Regarding SPEC benchmark, please note that Oracle posts SPEC2006 _RATE_ (multi-threaded throughput) results only. For the very nature of Niagaras (T1-T5) processors, the RATE score is very competitive: they are barrel processors, and obviously they excel in total aggregate throughput. The funny thing is that in throughput per socket base, Ivy Bridge is already a competitive or even superior choice. Let use SPEC number (but remember that compiler optimization play a critical role here):
Oracle Corporation SPARC T5-8 (8 sockets, 128 cores, 1024 threads)
SPECint® 2006: not published
SPECint®_rate 2006: 3750
Per socket perf: 468.75
Per core perf: 29.27
Per thread perf: ~3.66
LINK: http://www.spec.org/cpu2006/results/res2013q2/cpu2...
PowerEdge R920 (Intel Xeon E7-4890 v2, 4 sockets, 60 cores, 120 threads)
SPECint® 2006: 59.7
SPECint®_rate 2006: 2390
Per socket perf: 597.5
Per core perf: 39.83
Per thread perf: 19.92
LINK: http://www.spec.org/cpu2006/results/res2014q1/cpu2...
LINK: http://www.spec.org/cpu2006/results/res2014q1/cpu2...
As you can see, from any metrics the S3 core is not a match for a Ivy core, let alone Haswell. Moreover, T1/T2/T3 did not have the dynamic threading features, leading to always-active barrel processing resulting in extremely slow single-thread processing (I saw relatively simple queries that took 18 _minutes_ on a T2 and no, disk weren't busy, but totally idling).
Sun's latency-oriented processor (the one really intended for big unix boxes) was the Rock processor, but it was cancelled without a clear explaination. LINK: http://en.wikipedia.org/wiki/Rock_(processor)
The funny thing about all this post, is that performance alone don't matter: _reliability_ was the real plus of big iron Unixes, followed by memory capacity. It is for these specific reason that Intel is not so verbose about Xeon E7 performance, while it really stress the added reliability and serviceability (RAS) features of the new platform, coupled with the SMI links that greatly increased memory capacity.
In the end, there is surely space for big, RISC, proprietary Unix boxes, however this space is shrinking rapidly.
Regards.
Brutalizer - Monday, September 15, 2014 - link
"...the 256 socket E7 system is not a cluster: it uses QPI switches to connect the various sockets and it run a single kernel image..."Well, they are a cluster, running a single Linux kernel image, yes. Have you ever seen benchmarks that are NOT clustered? Nope. You only see HPC benchmarks. For instance, no SAP benchmarks there.
Here is an example of such a Linux server we talk of; the ScaleMP server which has 10.000s of cores and 100TBs of RAM and run Linux. The server scales to 256 sockets, using a variant of QPI.
http://www.theregister.co.uk/2011/09/20/scalemp_su...
"...Since its founding in 2003, ScaleMP has tried a different approach [than building complex hardware]. Instead of using special ASICs and interconnection protocols to lash together multiple server modes together into a shared memory system, ScaleMP cooked up a special hypervisor layer, called vSMP, that rides atop the x64 processors, memory controllers, and I/O controllers in multiple server nodes. Rather than carve up a single system image into multiple virtual machines, vSMP takes multiple physical servers and – using InfiniBand as a backplane interconnect – makes them look like a giant virtual SMP server with a shared memory space. vSMP has its limits.
The vSMP hypervisor that glues systems together is not for every workload, but on workloads where there is a lot of message passing between server nodes – financial modeling, supercomputing, data analytics, and similar HPC parallel workloads. Shai Fultheim, the company's founder and chief executive officer, says ScaleMP has over 300 customers now. "We focused on HPC as the low-hanging fruit"
From 2013:
http://www.theregister.co.uk/2013/10/02/cray_turns...
"...Big SMP systems are very expensive to design and manufacture. Building your own proprietary crossbar interconnect and associated big SMP tech, is a very expensive proposition. But SMP systems provide performance advantages that are hard to match with distributed systems....The beauty of using ScaleMP on a cluster is that large shared memory, single o/s systems can be easily built and then reconfigured at will. When you need a hella large SMP box, you can one with as many as 128 nodes and 256 TB of memory..."
I have another link where SGI says their large Linux Altix box, is only for HPC cluster workloads. They dont do SMP workloads. Something that Enterprise software branches too much, but HPC workloads only run tight for loops - suitable to running on each node.
.
.
Regarding the SpecINT2006 benchmarks you showed, the SPARC T5 is a server processor. That means throughput, serving as many thousands of clients as possible in a given time. IT does not really matter if a client gets the answer in 0.2 or 0.6 seconds, as long as the server can serve 15.000 clients, instead of 800 clients as desktop cpus do. Desktop cpus focus on few strong threads, having low throughput. My point is that the old SPARC T5 does very well even on single threaded benchmarks, but is made for server loads (i.e. throughput) and crushes.
Let us see the the benchmarks of the announced SPARC M7 and compare them to x86 or IBM POWER8 or anyone else. It will annihilate. It has several TB/sec bandwidth, it is truly a server cpu.
shodanshok - Monday, September 15, 2014 - link
Hi,I remember Fujitsu clearly stating that the EX platform make possible to use 256 sockets in _single image_ server, without using any vSMP tech. Moreover, from my understanding vSMP uses Infiniband as back-end, not QPI (or HT): http://www.scalemp.com/technology/versatile-smp-vs...
Anyway, as I don't personally manage any of these systems, I can go wrong. However, any Internet reference I can found seems to prove my understanding: http://www.infoworld.com/d/computer-hardware/infow... Can you provide me doc link about the maximum EX's sockets limit?
Regarding your CPU evaluation, sorry sir, but you are _very_ wrong. Interactive systems (web server, OLTP, SAP, etc) are very latency sensitive. If to show a billing order the user had to wait for 18 minutes (!), it will be very upset.
Server CPU surely are better throughput-oriented that their desktop cousins. However, latency remain a significant player in server space. After all this is the very reason for which Oracle enhanced its T series with dynamic threading (having cancelled Rock).
The best server CPU (note: I am _not_ saying that Xeon are the best CPU) will have a high throughput within a reasonable latency threshould (99% percentile is a good target), all with reasonable power consumption (to no throw efficiency out of the window).
Regards.
Brutalizer - Tuesday, September 16, 2014 - link
You talk about 256-socket x86 servers such as the SGI Altix or UV2000 servers, not being a cluster. Fine for you. Have you ever wondered why the big mature Enterprise Unix and Mainframes are stuck at 32-sockets after decades of R&D? They have tried for decades to increase performance, for instance, Fujitsu has a 64-socket SPARC server right now, called M10-4S. Why are there no 128-socket mature Unix or Mainframe servers? And suddenly, out of nowhere, comes a small player, and their first Linux server has 128 or 256 sockets. Does this sound reasonable to you? A small player succeeds what IBM, HP and Oracle/Sun never did, pouring billions and decades and vast armies of engineers and researchers? Why are there not more 64-socket Unix servers than only Fujitsus? Why are there no 256-socket Unix servers? Can you answer me this?And another question) why are all benchmarks from 256-socket Altix, ScaleMP servers - only cluster HPC benchmarks? No SMP enterprise benchmarks? Why does everyone use these servers for HPC cluster workloads?
SGI talks about their large Linux server Altix here, which has 10.000s of cores (Is it 128 or 256 sockets?)
http://www.realworldtech.com/sgi-interview/6/
"...The success of Altix systems in the high performance computing market are a very positive sign for both Linux and Itanium. Clearly, the popularity of large processor count Altix systems dispels any notions of whether Linux is a scalable OS for scientific applications. Linux is quite popular for HPC and will continue to remain so in the future,...However, scientific applications (HPC) have very different operating characteristics from commercial applications (SMP). Typically, much of the work in scientific code is done inside loops, whereas commercial applications, such as database or ERP software are far more branch intensive. This makes the memory hierarchy more important, particularly the latency to main memory. Whether Linux can scale well with a SMP workload is an open question. However, there is no doubt that with each passing month, the scalability in such environments will improve. Unfortunately, SGI has no plans to move into this SMP market, at this point in time..."
Here, SGI says explictly that their Altix and the successor UV2000 is only for HPC cluster workloads - and not for SMP workloads. Just as ScaleMP says regarding their large Linux server with 10.000s of cores.
Both of them say these servers are only suitable for cluster workloads. And there are only cluster benchmarks out there. Ergo, in reality, these large Linux servers behave like clusters. If they only can run cluster workloads, then they are clusters.
I invite you to post links to any large Linux server, with as many as 32-sockets. Hint: you will not find any. The largest Linux server ever sold, has 8-sockets. It is just a plain 8-socket x86 server, sold by IBM, HP or Oracle. Linux has never scaled more than 8-sockets, because larger servers does not exist. Now I talk about SMP servers, not clusters. If you go to Linux clusters, you can find 10.000 cores and larger. But when you need to do SMP Enterprise business workloads, the largest Linux server is 8-sockets. Again: I invite you to post links to a larger Linux server than 8-sockets which is not a cluster, and not a Unix RISC server that someone tried to compile Linux onto. Examples of the latter is the IBM AIX P795 Unix server, or HP Itanium HP-UX "Big Tux" Unix server. They are Unix servers.
So, the largest Linux server has 8-sockets. Any larger Linux server than that, is a cluster - because they can only run cluster workloads as the manufacturers say. Linux scales terribly on a SMP server, 8-sockets seems to be limit.