Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTThe Magic Inside the Uncore
We were already been spoiled by Ivy Bridge EP as it implemented a pretty complex uncore architecture. With Haswell EP, the communication between memory controllers, LLC, and cores has become even more intricate.
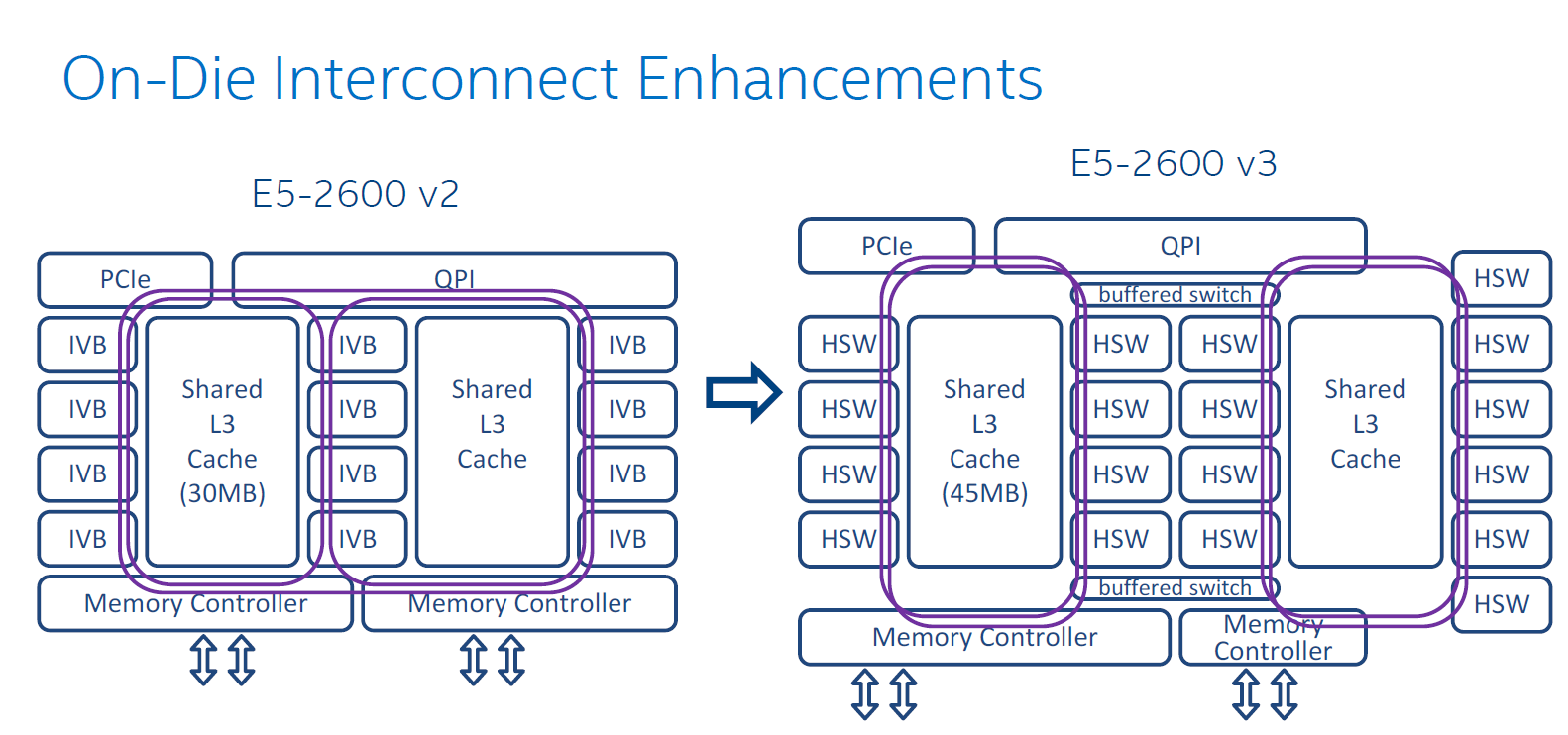
The Sandy Bridge EP CPU consisted of two columns of cores and LLC slices, connected by a single ring bus. The top models of the Ivy Bridge EP had three columns connected by a dual ring bus, with outer and inner rings as pictured above. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The 14 and 18 core SKUs now have four columns of cores and LLC slices, and as a result scheduling gets very complicated. Intel has now segregated the dual ring buses and integrated two buffered switches to simplify scheduling. It's somewhat comparable with the way an Ethernet switch divides a network into segments. Each ring can act independently, and as result the effective bandwidth increases, which is especially helpful when FMA/AVX instructions are working on 256-bit chunks of data.
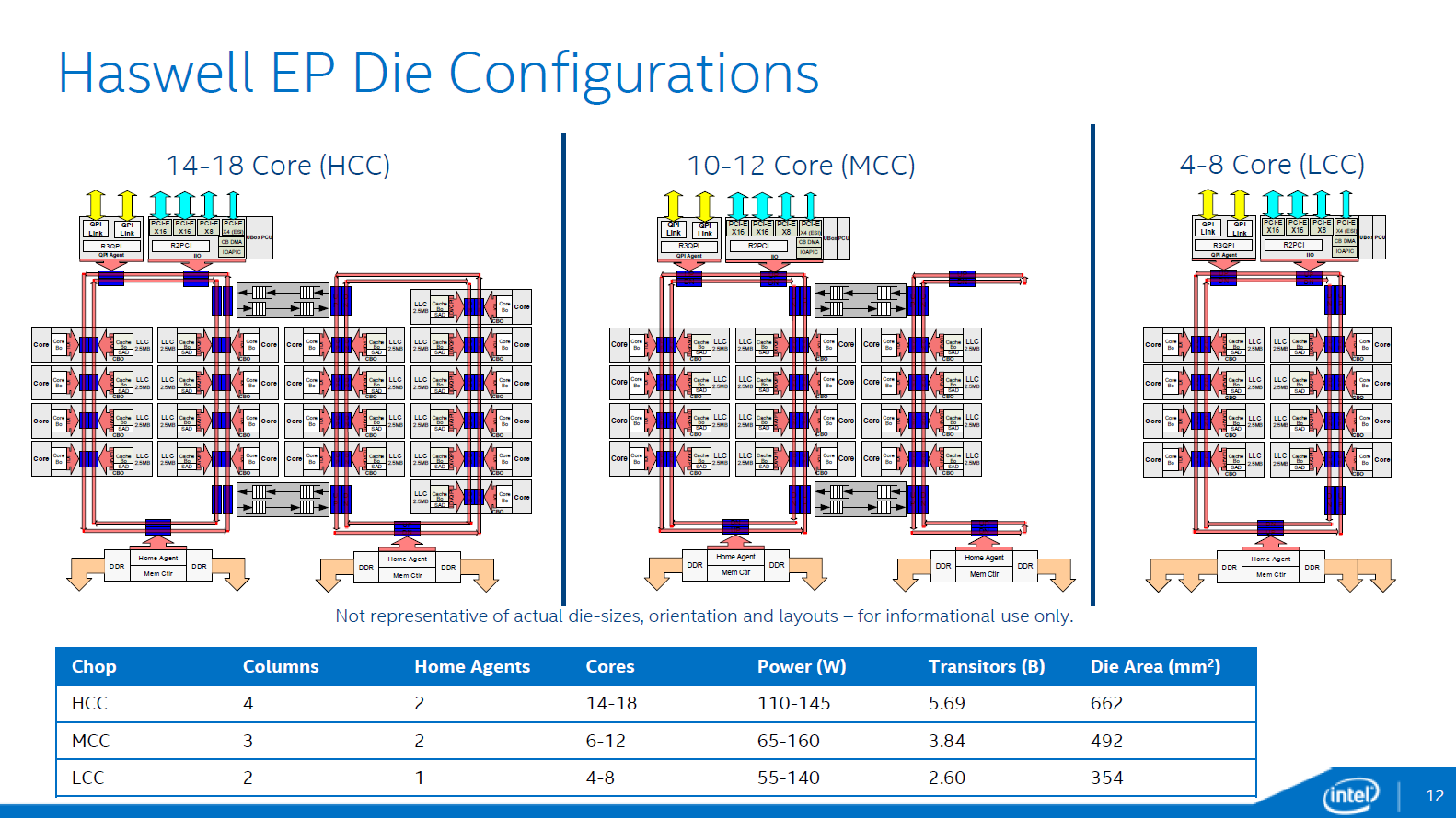
In total there are now three different die configurations. The first one, from four up to eight cores, is very similar to the lower count Ivy Bridge EPs. It has one dual ring, two columns of cores, and only one memory controller. The LLC cache is smaller on this die and has a lower latency.
The second configuration supports 10-12 cores and is a smaller version of the third die configuration that we described above. These dies have two memory controllers. The blue points indicate where data can jump onto the ring buses. Note that the die configurations are not symmetrical. For example an 18-core CPU has 8 cores (4-4) and 20MB LLC on one side, with 25MB LLC and 10 cores on the other. The middle configuration drops six to eight of the cores on the right ring, with an associated amount of LLC.
Data/instructions of one core are not stored in the adjacent cache slice. This could have lowered latency in some cases but it can create hotspots. Data is stored based on the physical address, ensuring all LCC cache slices are uniformly accessed. Transactions take the shortest path.
Rings are one of the entities that work on a separate voltage and frequency, just like cores. So if more I/O or coherency messaging is going on than processing, power can be dynamically allocated to speed up the rings.
Cache Coherency
The Home Agents are used for cache coherency and requests to DRAM. In dies that have two memory controllers, each home agent will use two channels. In dies that have one memory controller, each home agent will address four channels. While the smaller dies have faster LLC caches, Intel estimates that the second memory controller will extract 5% to 10% more bandwidth.
The two socket Haswell EP supports three snooping modes as you can see below. The first, Early Snoop, was available starting with Sandy Bridge EP models. With Ivy Bridge EP a second mode, Home Snoop, was introduced. Haswell EP now adds a third mode, Cluster on Die.
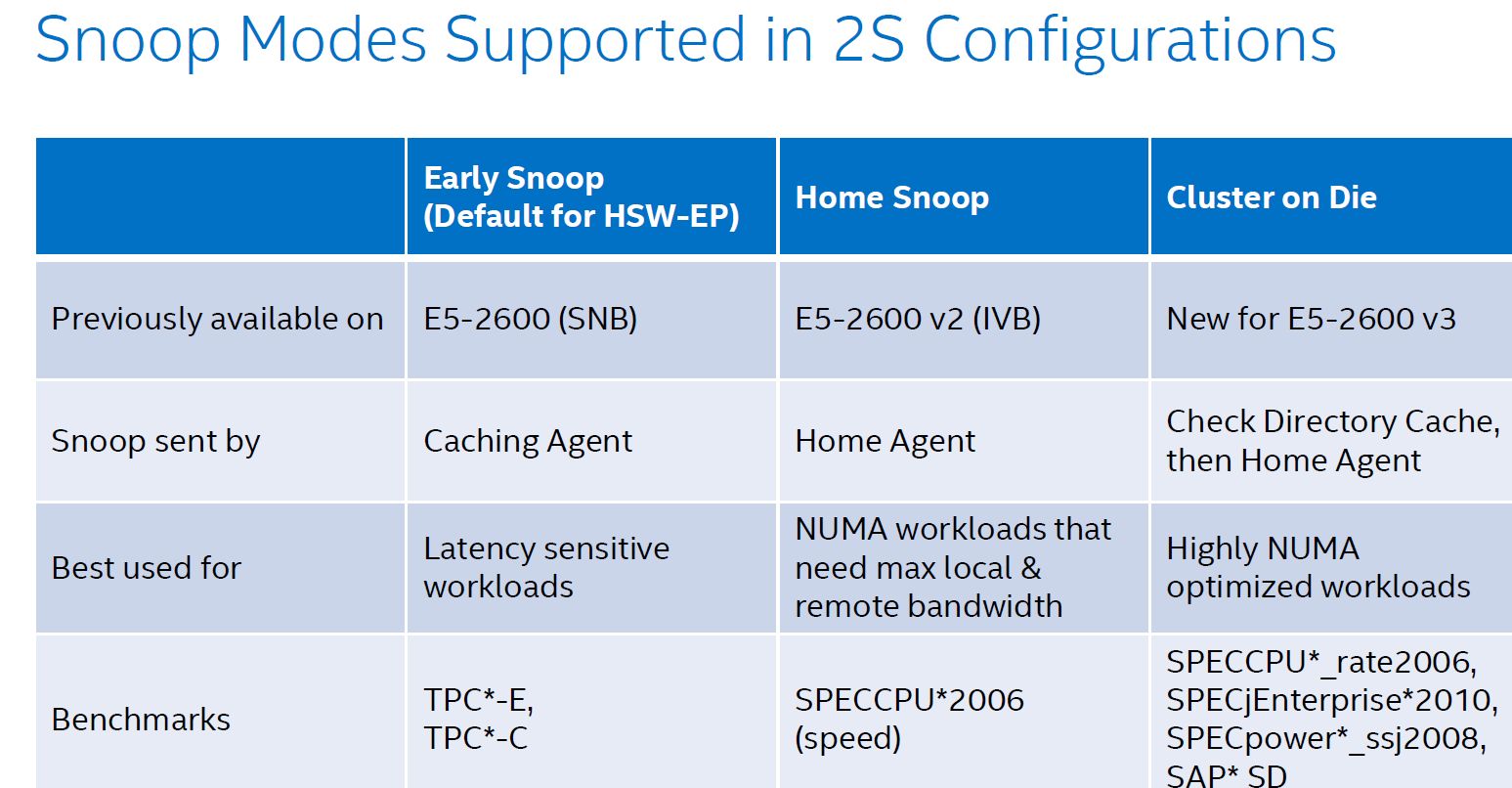
These snoop modes can be set in the BIOS.
Ivy Bridge used home snooping and had a directory in memory. The latest Xeon has directory caches (about 14KB) in each Home Agent. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. Another result is that directory updates in memory are less frequent and there are less broadcast snoops. Cluster On Die mode is the latest addition to the coherency protocols.
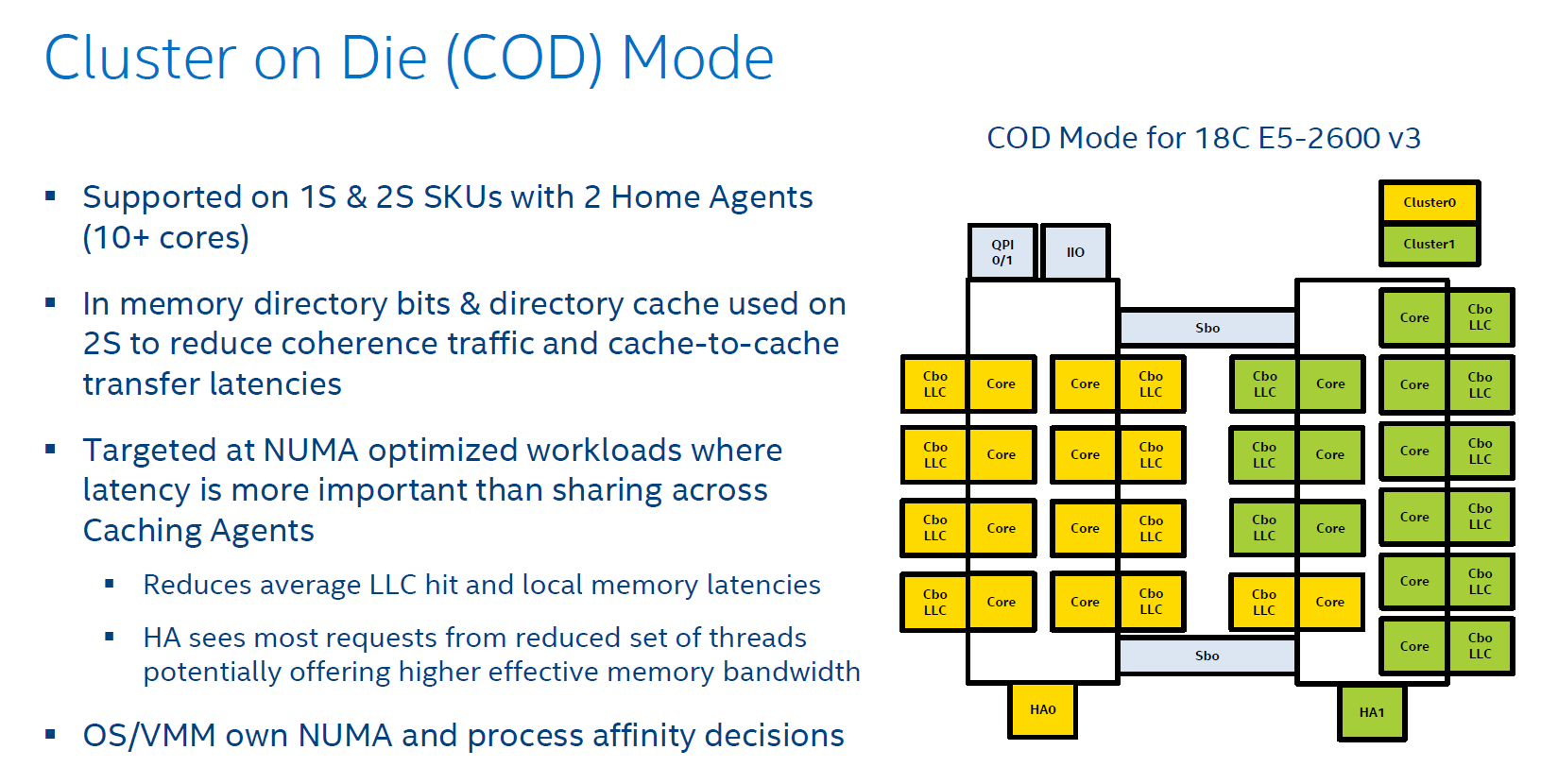
Cluster On Die can be understood as if you split the CPU and LLC into two parts that behave like two CPUs in NUMA. The OS is presented two affinity domains. As a result, the latency of LLC is lowered, but the hitrate is slightly lower. However if your application is NUMA aware, data and instructions are kept close to the part of the CPU that is processing them.
Higher QPI speeds, also notice the "COD" and "Early snoop" option.
And finally, QPI has been sped up to 9.6 GT/s, from 8 GT/s (as you can see in the BIOS shot).
More improvements
The list of (small) improvements is long and we have not been able to test all of them out. But here is an overview of what also improved
- Lower VM Entry/exit latency. The latency of going and forth to the Hypervisor has been improved compared to Westmere. Sandy Bridge slightly increase this compared to Westmere.
- VMCS shadowing. De VM Control Structure can be exposed to hypervisors running on top of the main hypervisor. So you get VT-x inside your nested hypervisor
- EPT Access and Dirty Bits. This makes it easier to move memory pages around, which is essiential for Live Migration / vMotion
- Cache monitoring (CMT) & allocation technology (CAT). CMT allow you to "measure" if a certain Virtual machine hogs the LLC . In certain SKUs is possible have control over the placement of data in the last-level cache.
Most of the improvements listed are specific for virtualized servers. However, cache allocation monitoring is also available for "native" OS.








85 Comments
View All Comments
martinpw - Monday, September 8, 2014 - link
There is a nice tool called i7z (can google it). You need to run it as root to get the live CPU clock display.kepstin - Monday, September 8, 2014 - link
Most Linux distributions provide a tool called "turbostat" which prints statistical summaries of real clock speeds and c state usage on Intel cpus.kepstin - Monday, September 8, 2014 - link
Note that if turbostat is missing or too old (doesn't support your cpu), you can build it yourself pretty quick - grab the latest linux kernel source, cd to tools/power/x86/turbostat, and type 'make'. It'll build the tool in the current directory.julianb - Monday, September 8, 2014 - link
Finally the e5-xxx v3s have arrived. I too can't wait for the Cinebench and 3DS Max benchmark results.Any idea if now that they are out the e5-xxxx v2s will drop down in price?
Or Intel doesn't do that...
MrSpadge - Tuesday, September 9, 2014 - link
Correct, Intel does not really lower prices of older CPUs. They just gradually phase out.tromp - Monday, September 8, 2014 - link
As an additional test of the latency of the DRAM subsystem, could you please run the "make speedup" scaling benchmark of my Cuckoo Cycle proof-of-work system at https://github.com/tromp/cuckoo ?That will show if 72 threads (2 cpus with 18 hyperthreaded cores) suffice to saturate the DRAM subsystem with random accesses.
-John
Hulk - Monday, September 8, 2014 - link
I know this is not the workload these parts are designed for, but just for kicks I'd love to see some media encoding/video editing apps tested. Just to see what this thing can do with a well coded mainstream application. Or to see where the apps fades out core-wise.Assimilator87 - Monday, September 8, 2014 - link
Someone benchmark F@H bigadv on these, stat!iwod - Tuesday, September 9, 2014 - link
I am looking forward to 16 Core Native Die, 14nm Broadwell Next year, and DDR4 is matured with much better pricing.Brutalizer - Tuesday, September 9, 2014 - link
Yawn, the new upcoming SPARC M7 cpu has 32 cores. SPARC has had 16 cores for ages. Since some generations back, the SPARC cores are able to dedicate all resources to one thread if need be. This way the SPARC core can have one very strong thread, or massive throughput (many threads). The SPARC M7 cpu is 10 billion transistors:http://www.enterprisetech.com/2014/08/13/oracle-cr...
and it will be 3-4x faster than the current SPARC M6 (12 cores, 96 threads) which holds several world records today. The largest SPARC M7 server will have 32-sockets, 1024 cores, 64TB RAM and 8.192 threads. One SPARC M7 cpu will be as fast as an entire Sunfire 25K. :)
The largest Xeon E5 server will top out at 4-sockets probably. I think the Xeon E7 cpus top out at 8-socket servers. So, if you need massive RAM (more than 10TB) and massive performance, you need to venture into Unix server territory, such as SPARC or POWER. Only they have 32-socket servers capable of reaching the highest performance.
Of course, the SGI Altix/UV2000 servers have 10.000s of cores and 100TBs of RAM, but they are clusters, like a tiny supercomputer. Only doing HPC number crunching workloads. You will never find these large Linux clusters run SAP Enterprise workloads, there are no such SAP benchmarks, because clusters suck at non HPC workloads.
-Clusters are typically serving one user who picks which workload to run for the next days. All SGI benchmarks are HPC, not a single Enterprise benchmark exist for instance SAP or other Enterprise systems. They serve one user.
-Large SMP servers with as many as 32 sockets (or even 64-sockets!!!) are typically serving thousands of users, running Enterprise business workloads, such as SAP. They serve thousands of users.