Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTMemory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readeable we limited ourselves to the CPUs that were different. The Xeon E5-2695 and 2699 have a very similar memory subsytem (dual memory controller) so we tested only the E5-2699.
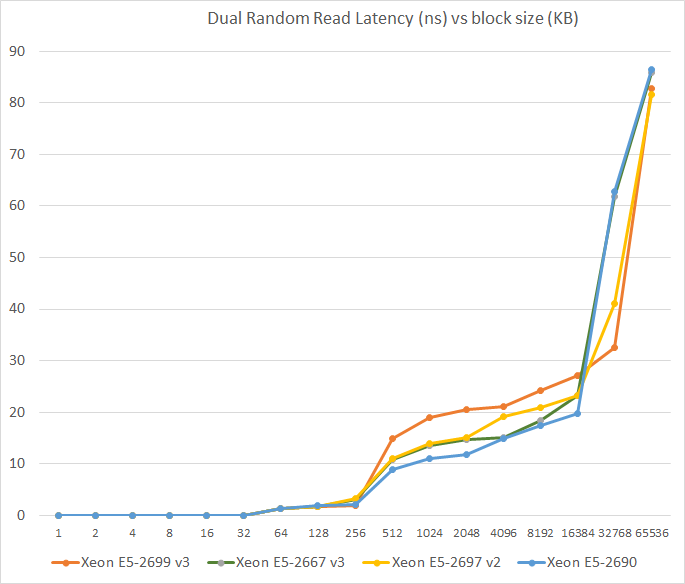
The massive L3 caches do have some disadvantages: latency goes up. The L3 cache of the Xeon E5-2699 v3 (45MB) has a latency between 20 and 32 ns while the 20MB cache of the Xeon E5-2690 hovers between 15 and 20 ns. That translates to about 90 cycles versus 60, which is considerable. However, it's not a case of the Haswell's L3 cache being a lot worse: the 20MB L3 cache of the Xeon E5-2667 v3 is only slightly slower than the Xeon E5-2690 and is still faster than the Xeon E5-2697 v2 (30MB). The main culprit is simply dealing with a huge amount of cache on the E5-2699 v3. In the next test, we will focus on the latency of the DRAM subsystem.
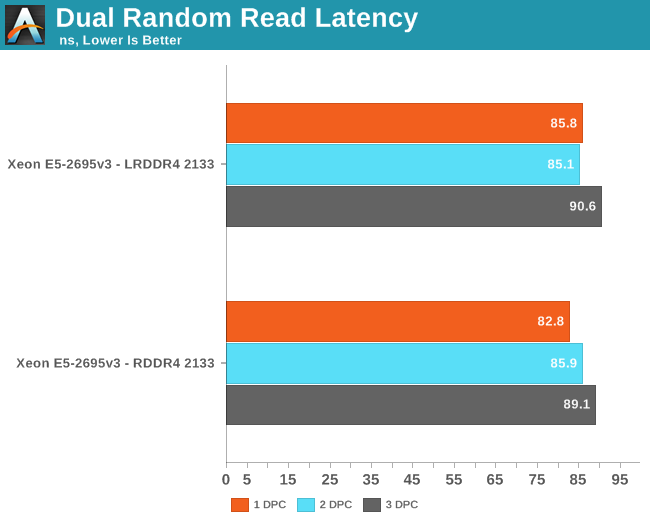
The DRAM subsystem is still three or four times slower than the massive L3 cache. LRDIMMs still have a very small latency overhead – +3.6% at the most – but that is neglible.
DDR4-2133 seems to have the same latency as DDR3-1866 . We measured 81.6 ns on the Xeon E5-2697 v2. Considering that DDR4-2400 is just around the corner, DDR4 will quickly give a performance boost to the new platform.








85 Comments
View All Comments
martinpw - Monday, September 8, 2014 - link
There is a nice tool called i7z (can google it). You need to run it as root to get the live CPU clock display.kepstin - Monday, September 8, 2014 - link
Most Linux distributions provide a tool called "turbostat" which prints statistical summaries of real clock speeds and c state usage on Intel cpus.kepstin - Monday, September 8, 2014 - link
Note that if turbostat is missing or too old (doesn't support your cpu), you can build it yourself pretty quick - grab the latest linux kernel source, cd to tools/power/x86/turbostat, and type 'make'. It'll build the tool in the current directory.julianb - Monday, September 8, 2014 - link
Finally the e5-xxx v3s have arrived. I too can't wait for the Cinebench and 3DS Max benchmark results.Any idea if now that they are out the e5-xxxx v2s will drop down in price?
Or Intel doesn't do that...
MrSpadge - Tuesday, September 9, 2014 - link
Correct, Intel does not really lower prices of older CPUs. They just gradually phase out.tromp - Monday, September 8, 2014 - link
As an additional test of the latency of the DRAM subsystem, could you please run the "make speedup" scaling benchmark of my Cuckoo Cycle proof-of-work system at https://github.com/tromp/cuckoo ?That will show if 72 threads (2 cpus with 18 hyperthreaded cores) suffice to saturate the DRAM subsystem with random accesses.
-John
Hulk - Monday, September 8, 2014 - link
I know this is not the workload these parts are designed for, but just for kicks I'd love to see some media encoding/video editing apps tested. Just to see what this thing can do with a well coded mainstream application. Or to see where the apps fades out core-wise.Assimilator87 - Monday, September 8, 2014 - link
Someone benchmark F@H bigadv on these, stat!iwod - Tuesday, September 9, 2014 - link
I am looking forward to 16 Core Native Die, 14nm Broadwell Next year, and DDR4 is matured with much better pricing.Brutalizer - Tuesday, September 9, 2014 - link
Yawn, the new upcoming SPARC M7 cpu has 32 cores. SPARC has had 16 cores for ages. Since some generations back, the SPARC cores are able to dedicate all resources to one thread if need be. This way the SPARC core can have one very strong thread, or massive throughput (many threads). The SPARC M7 cpu is 10 billion transistors:http://www.enterprisetech.com/2014/08/13/oracle-cr...
and it will be 3-4x faster than the current SPARC M6 (12 cores, 96 threads) which holds several world records today. The largest SPARC M7 server will have 32-sockets, 1024 cores, 64TB RAM and 8.192 threads. One SPARC M7 cpu will be as fast as an entire Sunfire 25K. :)
The largest Xeon E5 server will top out at 4-sockets probably. I think the Xeon E7 cpus top out at 8-socket servers. So, if you need massive RAM (more than 10TB) and massive performance, you need to venture into Unix server territory, such as SPARC or POWER. Only they have 32-socket servers capable of reaching the highest performance.
Of course, the SGI Altix/UV2000 servers have 10.000s of cores and 100TBs of RAM, but they are clusters, like a tiny supercomputer. Only doing HPC number crunching workloads. You will never find these large Linux clusters run SAP Enterprise workloads, there are no such SAP benchmarks, because clusters suck at non HPC workloads.
-Clusters are typically serving one user who picks which workload to run for the next days. All SGI benchmarks are HPC, not a single Enterprise benchmark exist for instance SAP or other Enterprise systems. They serve one user.
-Large SMP servers with as many as 32 sockets (or even 64-sockets!!!) are typically serving thousands of users, running Enterprise business workloads, such as SAP. They serve thousands of users.