Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTMemory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readeable we limited ourselves to the CPUs that were different. The Xeon E5-2695 and 2699 have a very similar memory subsytem (dual memory controller) so we tested only the E5-2699.
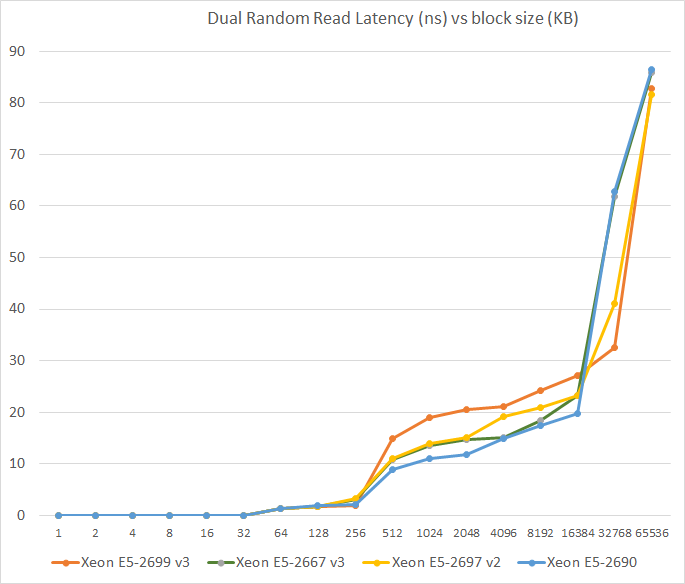
The massive L3 caches do have some disadvantages: latency goes up. The L3 cache of the Xeon E5-2699 v3 (45MB) has a latency between 20 and 32 ns while the 20MB cache of the Xeon E5-2690 hovers between 15 and 20 ns. That translates to about 90 cycles versus 60, which is considerable. However, it's not a case of the Haswell's L3 cache being a lot worse: the 20MB L3 cache of the Xeon E5-2667 v3 is only slightly slower than the Xeon E5-2690 and is still faster than the Xeon E5-2697 v2 (30MB). The main culprit is simply dealing with a huge amount of cache on the E5-2699 v3. In the next test, we will focus on the latency of the DRAM subsystem.
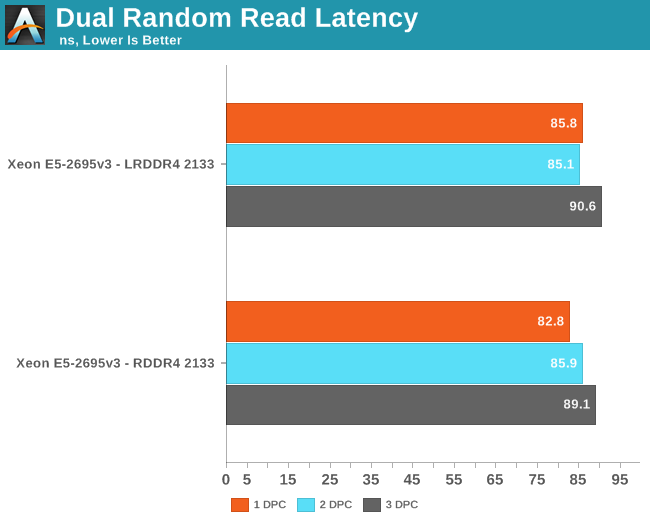
The DRAM subsystem is still three or four times slower than the massive L3 cache. LRDIMMs still have a very small latency overhead – +3.6% at the most – but that is neglible.
DDR4-2133 seems to have the same latency as DDR3-1866 . We measured 81.6 ns on the Xeon E5-2697 v2. Considering that DDR4-2400 is just around the corner, DDR4 will quickly give a performance boost to the new platform.








85 Comments
View All Comments
cmikeh2 - Monday, September 8, 2014 - link
In the SKU comparison table you have the E5-2690V2 listed as a 12/24 part when it is in fact a 10/20 part. Just a tiny quibble. Overall a fantastic read.KAlmquist - Monday, September 8, 2014 - link
Also, the 2637 v2 is 4/8, not 6/12.isa - Monday, September 8, 2014 - link
Looking forward to a new supercomputer record using these behemoths.Bruce Allen - Monday, September 8, 2014 - link
Awesome article. I'd love to see Cinebench and other applications tests. We do a lot of rendering (currently with older dual Xeons) and would love to compare these new Xeons versus the new 5960X chips - software license costs per computer are so high that the 5960X setups will need much higher price/performance to be worth it. We actually use Cinema 4D in production so those scores are relevant. We use V-Ray, Mental Ray and Arnold for Maya too but in general those track with the Cinebench scores so they are a decent guide. Thank you!Ian Cutress - Monday, September 8, 2014 - link
I've got some E5 v3 Xeons in for a more workstation oriented review. Look out for that soon :)fastgeek - Monday, September 8, 2014 - link
From my notes a while back... two E5-2690 v3's (all cores + turbo enabled) under 2012 Server yielded 3,129 for multithreaded and 79 for single.While not Haswell, I can tell you that four E5-4657L V2's returned 4,722 / 94 respectively.
Hope that helps somewhat. :-)
fastgeek - Monday, September 8, 2014 - link
I don't see a way to edit my previous comment; but those scores were from Cinebench R15wireframed - Saturday, September 20, 2014 - link
You pay for licenses for render Nodes? Switch to 3DS, and you get 9999 nodes for free (unless they changed the licensing since I last checked). :)Lone Ranger - Monday, September 8, 2014 - link
You make mention that the large core count chips are pretty good about raising their clock rate when only a few cores are active. Under Linux, what is the best way to see actual turbo frequencies? cpuinfo doesn't show live/actual clock rate.JohanAnandtech - Monday, September 8, 2014 - link
The best way to do this is using Intel's PCM. However, this does not work right now (only on Sandy and Ivy, not Haswel) . I deduced it from the fact that performance was almost identical and previous profiling of some of our benchmarks.