X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTSingle-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
This is more or less the worst-case scenario for "brawny" cores like Haswell or Power 8. Or in other words, it should be the best-case scenario for a less wide "energy optimized" ARM or Atom core, as the wide issue cores cannot achieve their full potential.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
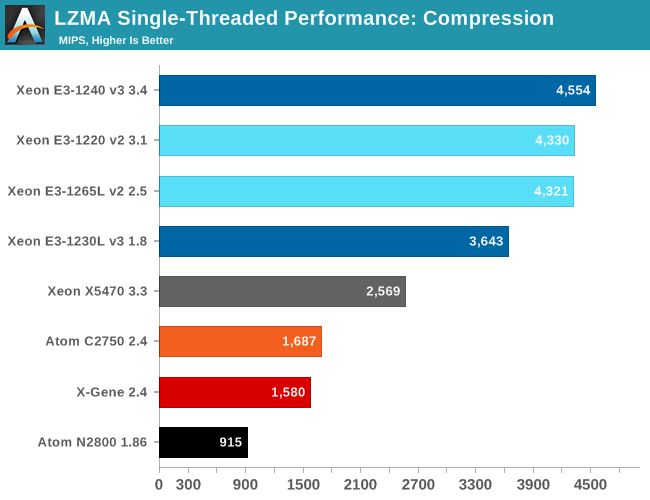
Despite the fact that the X-Gene has a 4-wide core, it is not able to outperform the dual issue Atom "Silvermont" core. Which is disappointing, considering that the AppliedMicro marketing claimed that the X-Gene would reach Xeon E5 levels. A 2.4GHz "Penryn/Harpertown" core reaches about 1860, which means that the X-Gene core still has a lot of catching up to do. It is nowhere near the performance levels of Ivy Bridge or Haswell.
Of course, the ARM ecosystem is still in its infancy. We tried out the new gcc 4.9.2, which has better support for AArch64. Compression became 6% faster, however decompression performance regressed by 4%....
Both the Xeon E3-1265L and E3-1220 v2 can boost to 3.5GHz, so they offer the same integer performance. The only reason that the Xeon E3-1240 v3 can offer higher performance is the slightly higher clock (3.8GHz Turbo Boost). The ultra efficient Xeon E3-1230L is capable of offering 80% of the performance of the 80W Xeon E3-1240. That is an excellent start.
As a long-time CPU enthusiast, you'll forgive me if I find the progress that Intel made from the 45nm "Harpertown" (X5470) to 22nm Xeon E3-1200 v3 pretty impressive. If we disable Turbo Boost, the Xeon E3-1240 at 3.4GHz achieves about 4200. This means that the Haswell architecture has an IPC that is no less than 63% better while running "IPC unfriendly" software.
The Xeon E3-1230L and Atom C2750 run at similar clock speeds in this single threaded task (2.8GHz vs 2.6GHz), but you can see how much difference a wide complex architecture makes. The Haswell Core is able to run about twice as many instructions in parallel as the Silvermont core. Meanwhile the Silvermont core is about 45% more efficient clock for clock than the old Saltwell core of the Atom N2800. The Haswell core result clearly shows that well designed wide architectures remain quite capable in "high ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
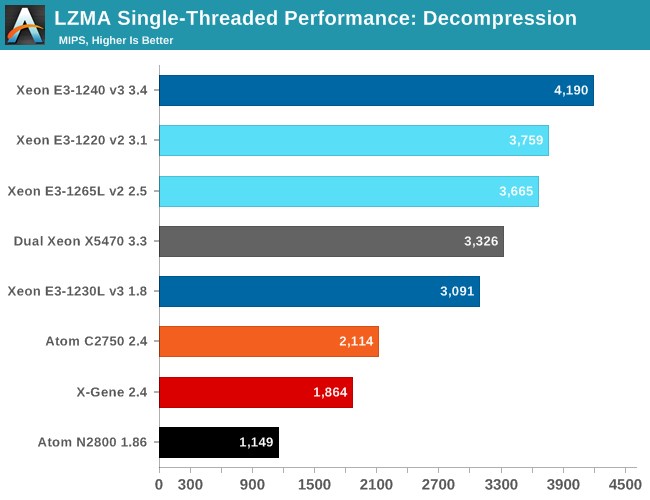
Decompression uses a rather exotic instruction mix and the progress made here is much smaller. The Haswell core is about 15% faster clock for clock than the old Harpertown core. Compared to the Silvermont core, the Haswell core is about 40% more efficient in this kind of software. The X-Gene core is about 10% slower than the Atom C2000.








47 Comments
View All Comments
JohanAnandtech - Tuesday, March 10, 2015 - link
Thanks! It is been a long journey to get all the necessary tests done on different pieces of hardware and it is definitely not complete, but at least we were able to quantify a lot of paper specs. (25 W TDP of Xeon E3, 20W Atom, X-Gene performance etc.)enzotiger - Tuesday, March 10, 2015 - link
SeaMicro focused on density, capacity, and bandwidth.How did you come to that statement? Have you ever benchmark (or even play with) any SeaMicro server? What capacity or bandwidth are you referring to? Are you aware of their plan down the road? Did you read AMD's Q4 earning report?
BTW, AMD doesn't call their server as micro-server anymore. They use the term dense server.
Peculiar - Tuesday, March 10, 2015 - link
Johan, I would also like to congratulate you on a well written and thorough examination of subject matter that is not widely evaluated.That being said, I do have some questions concerning the performance/watt calculations. Mainly, I'm concerned as to why you are adding the idle power of the CPUs in order to obtain the "Power SoC" value. The Power Delta should take into account the difference between the load power and the idle power and therefore you should end up with the power consumed by the CPU in isolation. I can see why you would add in the chipset power since some of the devices are SoCs and do no require a chipset and some are not. However, I do not understand the methodology in adding the idle power back into the Delta value. It seems that you are adding the load power of the CPU to the idle power of the CPU and that is partially why you have the conclusion that they are exceeding their TDPs (not to mention the fact that the chipset should have its own TDP separate from the CPU).
Also, if one were to get nit picky on the power measurements, it is unclear if the load power measurement is peak, average, or both. I would assume that the power consumed by the CPUs may not be constant since you state that "the website load is a very bumpy curve with very short peaks of high CPU load and lots of lows." If possible, it may be more beneficial to measure the energy consumed over the duration of the test.
JohanAnandtech - Wednesday, March 11, 2015 - link
Thanks for the encouragement. About your concerns about the perf/watt calculations. Power delta = average power (high web load measured at 95% percentile = 1 s, an average of about 2 minutes) - idle power. Since idle power = total idle of node, it contains also the idle power of the SoC. So you must add it to get the power of the SoC. If you still have doubts, feel free to mail me.jdvorak - Friday, March 13, 2015 - link
The approach looks absolutely sound to me. The idle power will be drawn in any case, so it makes sense to add it in the calculation. Perhaps it would also be interesting to compare the power consumed by the differents systems at the same load levels, such as 100 req/s, 200 req/s, ... (clearly, some higher loads will not be achievable by all of them).Johan, thanks a lot for this excellent, very informative article! I can imagine how much work has gone into it.
nafhan - Wednesday, March 11, 2015 - link
If these had 10gbit - instead of gbit - NICs, these things could do some interesting stuff with virtual SANs. I'd feel hesitant shuttling storage data over my primary network connection without some additional speed, though.Looking at that moonshot machine, for instance: 45 x 480 SSD's is a decent sized little SAN in a box if you could share most of that storage amongst the whole moonshot cluster.
Anyway, with all the stuff happening in the virtual SAN space, I'm sure someone is working on that.
Casper42 - Wednesday, April 15, 2015 - link
Johan, do you have a full Moonshot 1500 chassis for your testing? Or are you using a PONK?