X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTSingle-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
This is more or less the worst-case scenario for "brawny" cores like Haswell or Power 8. Or in other words, it should be the best-case scenario for a less wide "energy optimized" ARM or Atom core, as the wide issue cores cannot achieve their full potential.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
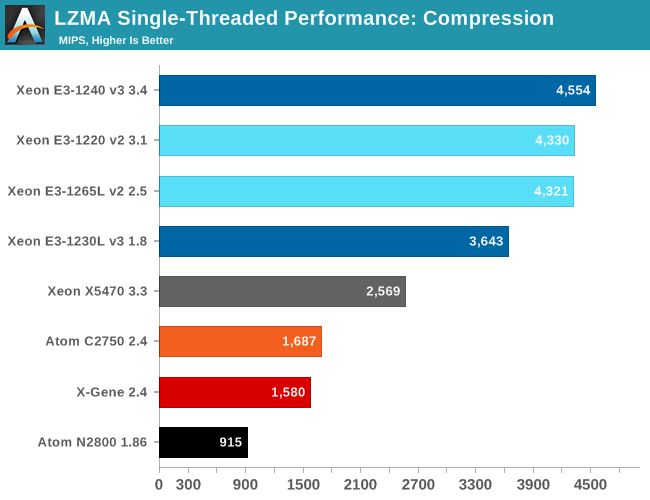
Despite the fact that the X-Gene has a 4-wide core, it is not able to outperform the dual issue Atom "Silvermont" core. Which is disappointing, considering that the AppliedMicro marketing claimed that the X-Gene would reach Xeon E5 levels. A 2.4GHz "Penryn/Harpertown" core reaches about 1860, which means that the X-Gene core still has a lot of catching up to do. It is nowhere near the performance levels of Ivy Bridge or Haswell.
Of course, the ARM ecosystem is still in its infancy. We tried out the new gcc 4.9.2, which has better support for AArch64. Compression became 6% faster, however decompression performance regressed by 4%....
Both the Xeon E3-1265L and E3-1220 v2 can boost to 3.5GHz, so they offer the same integer performance. The only reason that the Xeon E3-1240 v3 can offer higher performance is the slightly higher clock (3.8GHz Turbo Boost). The ultra efficient Xeon E3-1230L is capable of offering 80% of the performance of the 80W Xeon E3-1240. That is an excellent start.
As a long-time CPU enthusiast, you'll forgive me if I find the progress that Intel made from the 45nm "Harpertown" (X5470) to 22nm Xeon E3-1200 v3 pretty impressive. If we disable Turbo Boost, the Xeon E3-1240 at 3.4GHz achieves about 4200. This means that the Haswell architecture has an IPC that is no less than 63% better while running "IPC unfriendly" software.
The Xeon E3-1230L and Atom C2750 run at similar clock speeds in this single threaded task (2.8GHz vs 2.6GHz), but you can see how much difference a wide complex architecture makes. The Haswell Core is able to run about twice as many instructions in parallel as the Silvermont core. Meanwhile the Silvermont core is about 45% more efficient clock for clock than the old Saltwell core of the Atom N2800. The Haswell core result clearly shows that well designed wide architectures remain quite capable in "high ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
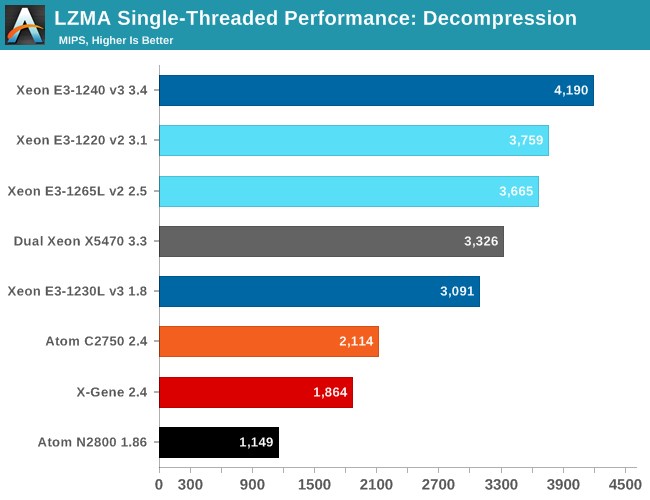
Decompression uses a rather exotic instruction mix and the progress made here is much smaller. The Haswell core is about 15% faster clock for clock than the old Harpertown core. Compared to the Silvermont core, the Haswell core is about 40% more efficient in this kind of software. The X-Gene core is about 10% slower than the Atom C2000.








47 Comments
View All Comments
Wilco1 - Tuesday, March 10, 2015 - link
GCC4.9 doesn't contain all the work in GCC5.0 (close to final release, but you can build trunk). As you hinted in the article, it is early days for AArch64 support, so there is a huge difference between a 4.9 and 5.0 compiler, so 5.0 is what you'd use for benchmarking.JohanAnandtech - Tuesday, March 10, 2015 - link
You must realize that the situation in the ARM ecosystem is not as mature as on x86. the X-Gene runs on a specially patched kernel that has some decent support for ACPI, PCIe etc. If you do not use this kernel, you'll get in all kinds of hardware trouble. And afaik, gcc needs a certain version of the kernel.Wilco1 - Tuesday, March 10, 2015 - link
No you can use any newer GCC and GLIBC with an older kernel - that's the whole point of compatibility.Btw your results look wrong - X-Gene 1 scores much lower than Cortex-A15 on the single threaded LZMA tests (compare with results on http://www.7-cpu.com/). I'm wondering whether this is just due to using the wrong compiler/options, or running well below 2.4GHz somehow.
JohanAnandtech - Tuesday, March 10, 2015 - link
Hmm. the A57 scores 1500 at 1.9 GHz on compression. The X-Gene scores 1580 with Gcc 4.8 and 1670 with gcc 4.9. Our scores are on the low side, but it is not like they are impossibly low.Ubuntu 14.04, 3.13 kernel and gcc 4.8.2 was and is the standard environment that people will get on the the m400. You can tweak a lot, but that is not what most professionals will do. Then we can also have to start testing with icc on Intel. I am not convinced that the overall picture will change that much with lots of tweaking
Wilco1 - Tuesday, March 10, 2015 - link
Yes, and I'd expect the 7420 will do a lot better than the 5433. But the real surprise to me is that X-Gene 1 doesn't even beat the A15 in Tegra K1 despite being wider, newer and running at a higher frequency - that's why the results look too low.I wouldn't call upgrading to the latest compiler tweaking - for AArch64 that is kind of essential given it is early days and the rate of development is extremely high. If you tested 32-bit mode then I'd agree GCC 4.8 or 4.9 are fine.
CajunArson - Tuesday, March 10, 2015 - link
This is all part of the problem: Requiring people to use cutting edge software with custom recompilation just to beat a freakin' Atom much less a real CPU?You do realize that we could play the same game with all the Intel parts. Believe me, the people who constantly whine that Haswell isn't any faster than Sandy Bridge have never properly recompiled computationally intensive code to take advantage of AVX2 and FMA.
The fact that all those Intel servers were running software that was only compiled for a generic X86-64 target without requiring any special tweaking or exotic hacking is just another major advantage for Intel, not some "cheat".
Klimax - Tuesday, March 10, 2015 - link
And if we are going for cutting edge compiler, then why not ICC with Intel's nice libraries... (pretty sure even ancient atom would suddenly look not that bad)Wilco1 - Tuesday, March 10, 2015 - link
To make a fair comparison you'd either need to use the exact same compiler and options or go all out and allow people to write hand optimized assembler for the kernels.68k - Saturday, March 14, 2015 - link
You can't seriously claim that recompiling an existing program with a different (well known and mature) compiler is equal to hand optimize things in assembler. Hint, one of the options is ridiculous expensive, one is trivial.aryonoco - Monday, March 9, 2015 - link
Thank you Johan. Very very informative article. This is one of the least reported areas of IT in general, and one that I think is poised for significant uptake in the next 5 years or so.Very much appreciate your efforts into putting this together.