X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTSingle-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
This is more or less the worst-case scenario for "brawny" cores like Haswell or Power 8. Or in other words, it should be the best-case scenario for a less wide "energy optimized" ARM or Atom core, as the wide issue cores cannot achieve their full potential.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
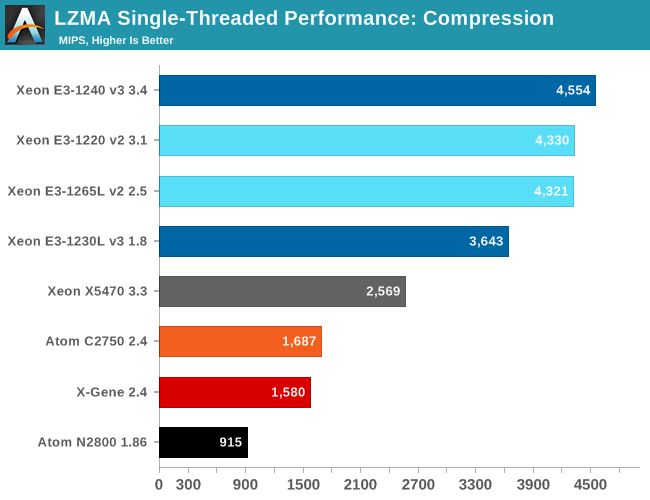
Despite the fact that the X-Gene has a 4-wide core, it is not able to outperform the dual issue Atom "Silvermont" core. Which is disappointing, considering that the AppliedMicro marketing claimed that the X-Gene would reach Xeon E5 levels. A 2.4GHz "Penryn/Harpertown" core reaches about 1860, which means that the X-Gene core still has a lot of catching up to do. It is nowhere near the performance levels of Ivy Bridge or Haswell.
Of course, the ARM ecosystem is still in its infancy. We tried out the new gcc 4.9.2, which has better support for AArch64. Compression became 6% faster, however decompression performance regressed by 4%....
Both the Xeon E3-1265L and E3-1220 v2 can boost to 3.5GHz, so they offer the same integer performance. The only reason that the Xeon E3-1240 v3 can offer higher performance is the slightly higher clock (3.8GHz Turbo Boost). The ultra efficient Xeon E3-1230L is capable of offering 80% of the performance of the 80W Xeon E3-1240. That is an excellent start.
As a long-time CPU enthusiast, you'll forgive me if I find the progress that Intel made from the 45nm "Harpertown" (X5470) to 22nm Xeon E3-1200 v3 pretty impressive. If we disable Turbo Boost, the Xeon E3-1240 at 3.4GHz achieves about 4200. This means that the Haswell architecture has an IPC that is no less than 63% better while running "IPC unfriendly" software.
The Xeon E3-1230L and Atom C2750 run at similar clock speeds in this single threaded task (2.8GHz vs 2.6GHz), but you can see how much difference a wide complex architecture makes. The Haswell Core is able to run about twice as many instructions in parallel as the Silvermont core. Meanwhile the Silvermont core is about 45% more efficient clock for clock than the old Saltwell core of the Atom N2800. The Haswell core result clearly shows that well designed wide architectures remain quite capable in "high ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
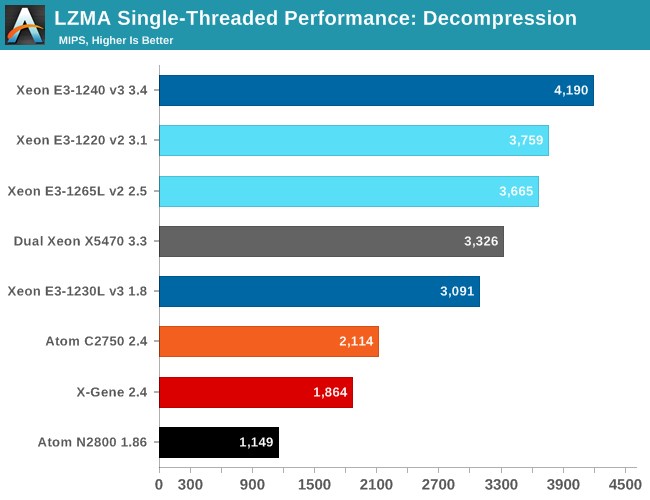
Decompression uses a rather exotic instruction mix and the progress made here is much smaller. The Haswell core is about 15% faster clock for clock than the old Harpertown core. Compared to the Silvermont core, the Haswell core is about 40% more efficient in this kind of software. The X-Gene core is about 10% slower than the Atom C2000.








47 Comments
View All Comments
JohanAnandtech - Tuesday, March 10, 2015 - link
Are you sure this is up to date? gcc tells me -march=native is not supported.JohanAnandtech - Tuesday, March 10, 2015 - link
Update. march=native does not work. I have tried -march=armv8-a but does not do much (it is probably the default). O3 makes the biggest difference. Omit it and you get 5.7 GB/s. With -O3, I am at 18 GB/s and more (stream m400)Alone-in-the-net - Tuesday, March 10, 2015 - link
Apologies. For AArch64 the only is "armv8-a", for intel, -march=native sets it to use the one for your CPU.https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/AArch...
https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/i386-...
From version 4.9.x and above of GCC, you can really start to add tuning for the CPU.
https://gcc.gnu.org/onlinedocs/gcc-4.9.2/gcc/AArch...
-mtune=name
Specify the name of the target processor for which GCC should tune the performance of the code. Permissible values for this option are: ‘generic’, ‘cortex-a53’, ‘cortex-a57’.
Additionally, this option can specify that GCC should tune the performance of the code for a big.LITTLE system. The only permissible value is ‘cortex-a57.cortex-a53’.
Where none of -mtune=, -mcpu= or -march= are specified, the code will be tuned to perform well across a range of target processors.
Alone-in-the-net - Tuesday, March 10, 2015 - link
Also support for the XGene1 as a compilation target is only from GCC5.https://gcc.gnu.org/gcc-5/changes.html
Support has been added for the following processors (GCC identifiers in parentheses): ARM Cortex-A72 (cortex-a72) and initial support for its big.LITTLE combination with the ARM Cortex-A53 (cortex-a72.cortex-a53), Cavium ThunderX (thunderx), Applied Micro X-Gene 1 (xgene1). The GCC identifiers can be used as arguments to the -mcpu or -mtune options, for example: -mcpu=xgene1
The_Assimilator - Monday, March 9, 2015 - link
So AMD, how's that bet on ARM you made looking now?extide - Monday, March 9, 2015 - link
Don't count them out yet. I really wish that intel didn't abandon ARM for the Atom, I bet they could come out with a sweet armv8 core if they had to, and on their process it would be sweet.BlueBlazer - Monday, March 9, 2015 - link
That AMD Opteron A1100 looking more like abandonware as more time passes on, and that was like 8 months ago. Until now not a single real world deployment nor was used in any of AMD's own SeaMicro servers. Currently available as development kit with a rather steep price tag.tuxRoller - Monday, March 9, 2015 - link
You REALLY should be using GCC 5. that includes many improvements for the armv8 isa. I'd suggest grabbing a nightly of Fedora 22, but Ubuntu 15.04 may be using gcc5 as well.Wilco1 - Monday, March 9, 2015 - link
Agreed, nobody doing anything on AArch64 should contemplate using GCC4.8. Even 4.9 is way out of date. GCC5.0 with latest GLIBC gives major speedups across the board.JohanAnandtech - Tuesday, March 10, 2015 - link
"Way out of date?" We tried out 4.9.2, which has been released on October 30th 2014. That is about 4 months old. https://www.gnu.org/software/gcc/releases.html. Latest version is 4.8.4, 5.0 has not even been released AFAIK.