X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTMemory Subsystem Bandwidth
While the Xeon E5 has ample bandwidth for most applications courtesy of the massive quad-channel memory subsystem, the Xeon E3 and Atom C2000 only have two memory channels. The Xeon E3 and Atom C2000 also do not support the fastest DRAM modules (DDR3-1600, Xeon E5: DDR4-2133), so memory bandwidth can be a problem for some applications.
We measured the memory bandwidth in Linux. The binary was compiled with the Open64 compiler 5.0 (Opencc). It is a multi-threaded, OpenMP based, 64-bit binary. The following compiler switches were used:
-Ofast -mp -ipa
To keep things simple, we only report the Triad sub-benchmark of our OpenMP enabled Stream benchmark.
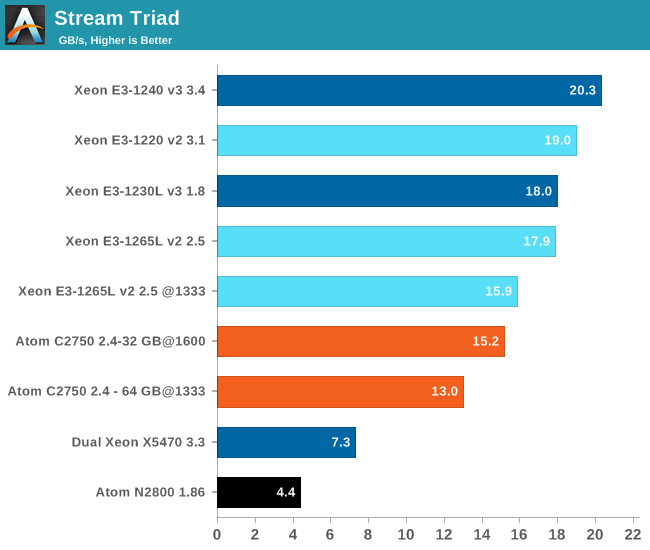
First of all, we should note that the clock speed of the CPU has very little influence on the Stream score. Notice the small difference (12.7%) between the Xeon E3-1240 that can boost to 3.6GHz and the Xeon E3-1230L that is limited to 2.3GHz (Turbo Boost with four cores busy).
The Xeon E3-1200 v3 is slightly more efficient than the Xeon E3-1200 v2; we measured a 7% bandwidth improvement. The Xeon E3 also offers up to 33% more bandwidth than the Atom C2750 with the same DIMMs.
To do an apples-to-apples comparison with the X-Gene 1, we compiled the same OpenMP enabled Stream benchmark (O3 –fopenmp –static).
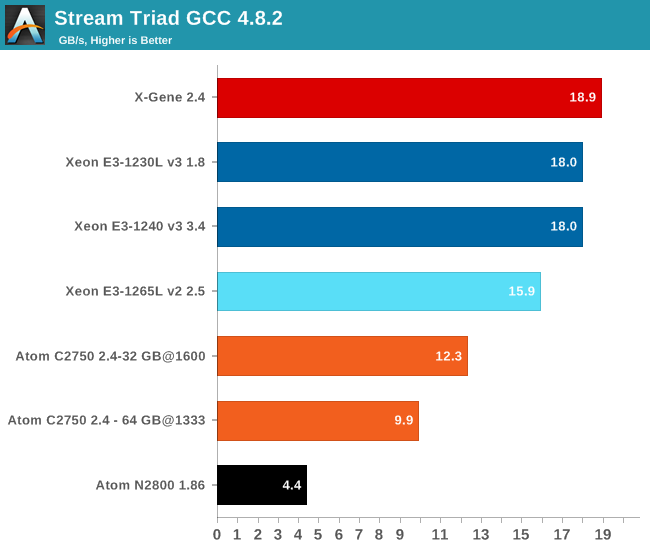
The Xeon E3 has the most efficient memory controller: it can extract almost as much bandwidth as the quad-channel memory controller of the X-Gene and about 46% more than the Atom. Our guess is that the X-Gene still has quite a bit of headroom to improve the memory subsystem. There is work to be done on the compiler side and on the hardware.








47 Comments
View All Comments
JohanAnandtech - Tuesday, March 10, 2015 - link
Are you sure this is up to date? gcc tells me -march=native is not supported.JohanAnandtech - Tuesday, March 10, 2015 - link
Update. march=native does not work. I have tried -march=armv8-a but does not do much (it is probably the default). O3 makes the biggest difference. Omit it and you get 5.7 GB/s. With -O3, I am at 18 GB/s and more (stream m400)Alone-in-the-net - Tuesday, March 10, 2015 - link
Apologies. For AArch64 the only is "armv8-a", for intel, -march=native sets it to use the one for your CPU.https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/AArch...
https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/i386-...
From version 4.9.x and above of GCC, you can really start to add tuning for the CPU.
https://gcc.gnu.org/onlinedocs/gcc-4.9.2/gcc/AArch...
-mtune=name
Specify the name of the target processor for which GCC should tune the performance of the code. Permissible values for this option are: ‘generic’, ‘cortex-a53’, ‘cortex-a57’.
Additionally, this option can specify that GCC should tune the performance of the code for a big.LITTLE system. The only permissible value is ‘cortex-a57.cortex-a53’.
Where none of -mtune=, -mcpu= or -march= are specified, the code will be tuned to perform well across a range of target processors.
Alone-in-the-net - Tuesday, March 10, 2015 - link
Also support for the XGene1 as a compilation target is only from GCC5.https://gcc.gnu.org/gcc-5/changes.html
Support has been added for the following processors (GCC identifiers in parentheses): ARM Cortex-A72 (cortex-a72) and initial support for its big.LITTLE combination with the ARM Cortex-A53 (cortex-a72.cortex-a53), Cavium ThunderX (thunderx), Applied Micro X-Gene 1 (xgene1). The GCC identifiers can be used as arguments to the -mcpu or -mtune options, for example: -mcpu=xgene1
The_Assimilator - Monday, March 9, 2015 - link
So AMD, how's that bet on ARM you made looking now?extide - Monday, March 9, 2015 - link
Don't count them out yet. I really wish that intel didn't abandon ARM for the Atom, I bet they could come out with a sweet armv8 core if they had to, and on their process it would be sweet.BlueBlazer - Monday, March 9, 2015 - link
That AMD Opteron A1100 looking more like abandonware as more time passes on, and that was like 8 months ago. Until now not a single real world deployment nor was used in any of AMD's own SeaMicro servers. Currently available as development kit with a rather steep price tag.tuxRoller - Monday, March 9, 2015 - link
You REALLY should be using GCC 5. that includes many improvements for the armv8 isa. I'd suggest grabbing a nightly of Fedora 22, but Ubuntu 15.04 may be using gcc5 as well.Wilco1 - Monday, March 9, 2015 - link
Agreed, nobody doing anything on AArch64 should contemplate using GCC4.8. Even 4.9 is way out of date. GCC5.0 with latest GLIBC gives major speedups across the board.JohanAnandtech - Tuesday, March 10, 2015 - link
"Way out of date?" We tried out 4.9.2, which has been released on October 30th 2014. That is about 4 months old. https://www.gnu.org/software/gcc/releases.html. Latest version is 4.8.4, 5.0 has not even been released AFAIK.