ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM ESTMidgard’s Arithmetic Pipelines
Having taken a look at Midgard’s architecture from a high level perspective, we next want to dive deep into the heart of Midgard: its arithmetic pipelines. This is where the bulk of the work takes place on any modern GPU, and in most cases real-world GPU performance significantly hinges on the design decisions made here. Furthermore this is where Midgard’s most unconventional design decisions lie, and as a result it’s the arithmetic pipelines that make Midgard stand apart from anything else we’ve seen.
ARM describes Midgard as a Very Long Instruction Word (VLIW) design with Single Instruction Multiple Data (SIMD) characteristics (though officially it is called Sequential Long Instruction Word). What this means is that at a high level ARM is feeding multiple ALUs, including SIMD units, with a single long word of instructions. But perhaps it’s better we start at a low level instead.
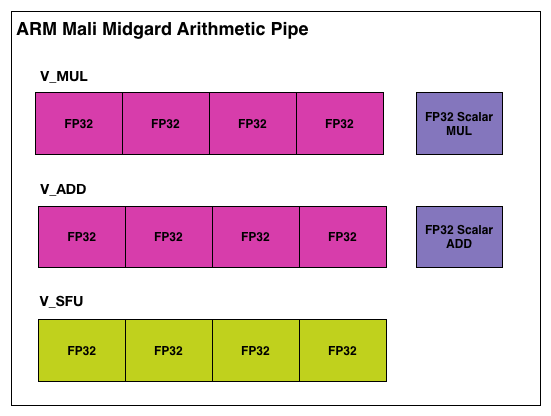
The above is a single Midgard arithmetic pipeline, in our example configured for FP32 operations. In it ARM uses a mix of both scalar and vector (SIMD) ALUs. Altogether ARM breaks it down as 3 vector ALUs and 2 scalar ALUs, each responsible for a specific type of operation.
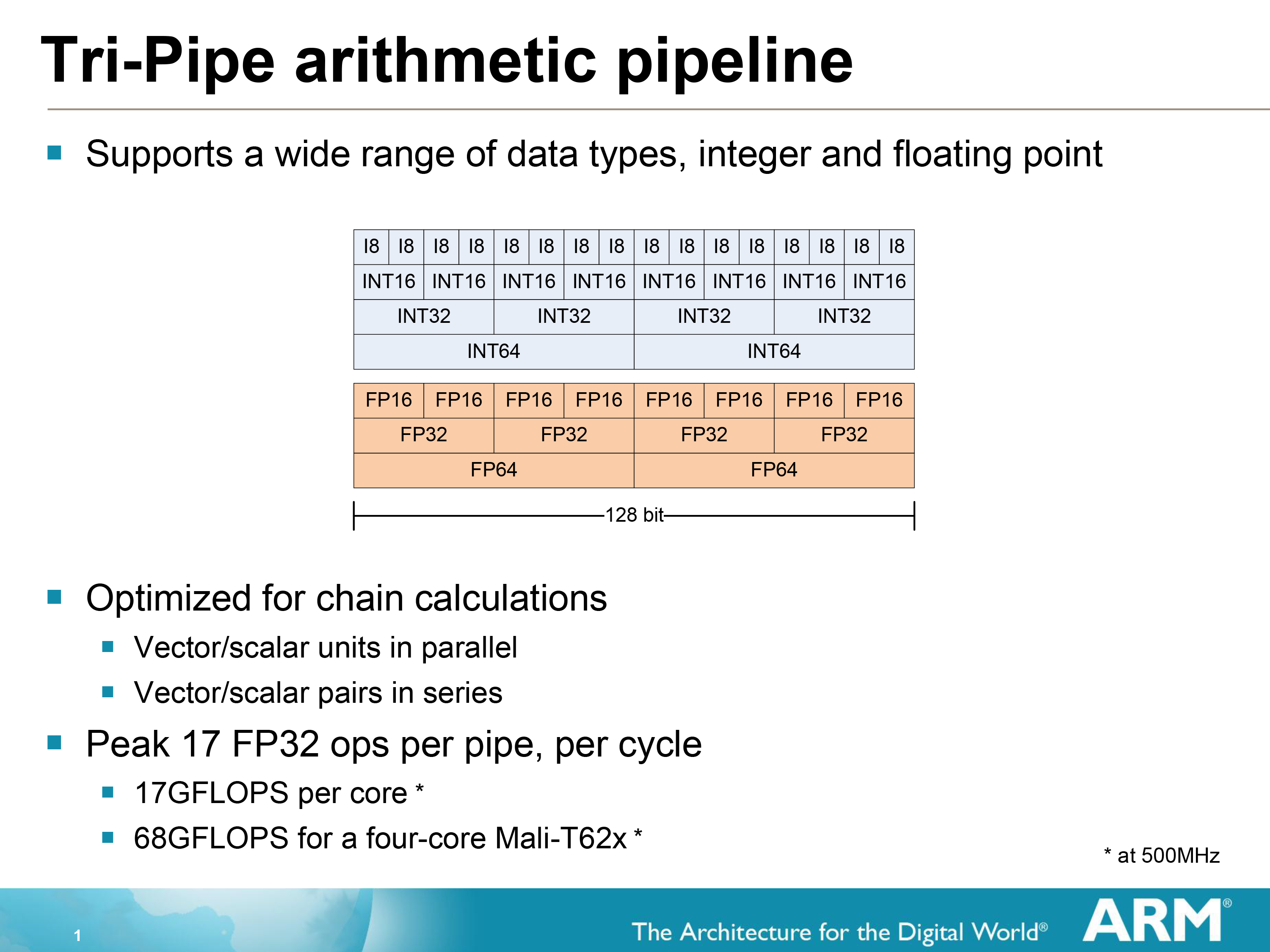
If we stop for a moment and look at the SIMD, we find out something very interesting about it as well. Remember earlier how we mentioned that Midgard is capable of 64bit operations? Well this is how they do it. Not with separate 64bit and 32bit units as in some other designs, but by using a single 128bit wide SIMD and decomposing operations based on their width. The 128bit SIMDs in a Midgard core can process 2 64 bit operations, 4 32bit operations, or even 8 16bit operations per clock cycle. Simply fill the SIMD with as many (identical) operations as will fit, and the SIMD will handle the rest.
The use of SIMDs and SIMD-like designs is not uncommon in GPUs, but it’s relatively rare to see a flexible SIMD of this nature. In the past other architecture designers have talked about this being a efficiency tradeoff – you lose some efficiency by using a flexible design rather than a rigid design – however in ARM’s case they have decided that they can meet all of their goals with a 128bit SIMD.
Jumping back up a level, from a hardware perspective a Midgard arithmetic pipeline is capable of up to 17 FP32 FLOPS. This is constructed as the following.
- 4 vector adds
- 4 vector multiplies
- 1 scalar add
- 1 scalar multiple
- 1 FDOT4 dot product (7 FLOPS)
The vector and scalar operations are relatively self-explanatory, while the dot products are a result of using the vector special functions unit. To that end every architecture possesses SFUs in some form to handle dot products, transcendentals, and other complex operations, but their inclusion in FLOPS counting is uncommon. Most architectures merely count FLOPS as adds and multiplies through the ubiquitous and all important MAD (Multiply-Add) instruction. NVIDIA’s forthcoming K1 (to pick a GPU with a desktop counterpart) has 192 FP32 ALUs, and via MADs can achieve up to 384 FLOPS per cycle.
Ultimately how ARM counts FLOPS is entirely up to them, but we do want to take a moment to rectify it with how we count FLOPS on our end. Dot products are a relatively common mathematical operation in rendering, enough so that it’s important to be able to do them quickly, but they are generally not counted for computing FLOPS.
Meanwhile for FP64 FLOPS, as one would expect Midgard’s performance is much lower. ARM does not provide the FLOPS breakdown for 64bit operations, but they tell us that it is a total of 5 FLOPS. Our best guess here is that 4 of those FLOPS are coming from the vector units (2 FP64 MADs) and then 1 more FP64 FLOP is coming off of the scalar units, which if our assumption is correct would imply that it is not capable of an FP64 MAD in 1 cycle. Overall on a MAD basis this puts FP64 performance at 5/10ths, or ½ FP32 performance, which is a very high FP64 performance ratio even compared to desktop GPU architectures.
Furthermore, in further rectifying how ARM presents some of its data with how we typically present data in our articles, we’re also going to be using a condensed version of the Midgard arithmetic pipeline from this point on. As most architectures either utilize ALUs that can perform a MAD on their own or simplify their descriptions to showcase 1 ALU (rather than explicitly over 2 ALUs as on Midgard), we will be using a condensed version of the Midgard arithmetic pipeline that is drawn in a similar manner. Since we always count a standard ALU as being capable of 2 FLOPs (SFUs withstanding), this makes our Midgard arithmetic pipeline illustration consistent with our previous illustrations. It’s for all intents and purposes the same pipeline, only condensed.
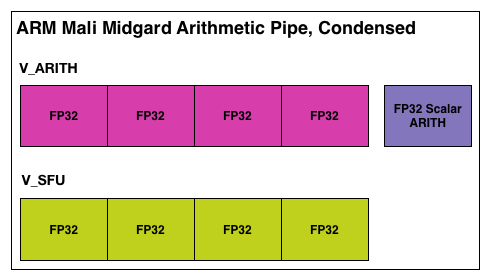
Finally, let’s take a quick look at a complete Midgard “tri pipe” core from an ALU standpoint. Since in T760 each core has 2 arithmetic units, a single core a just 2 of our condensed units. For a complete GPU this would then be multiplied by as many cores as the resulting design called for.








66 Comments
View All Comments
toyotabedzrock - Friday, July 4, 2014 - link
Didn't imagine also buy from ATI? Maybe that is why they are concerned with patents?Kevin G - Saturday, July 5, 2014 - link
There likely is a cross licensing agreement in place. Literally to build any modern GPU a company has to cross license patents. It works out to be zero sum in that money isn't exchanged but one company can use the other's patents (and future patents) royalty free.This also puts a rather high barrier to entry in the market.
nolaviz - Thursday, July 3, 2014 - link
Ah, the history... I led the integration of MALI55 into Zoran's APPROACH-5C. Sweet memories :)skiboysteve - Thursday, July 3, 2014 - link
Very interesting. Complete 100% opposite of the AMD architecture.Also, the fact that they can power down shader cores and even individual ALUs makes this pure ILP and zero TLP architecture really shine. Because the compiler only needs to optimize work on an ALU level.... Not on a shader or wavefront level. So then based upon demand they just feed more or less of these ALU-optomized-packets of work into the GPU and power down the rest of the ALUs. It makes complete sense. Make each ALU independent, compile work on a per ALU basis, then scale your ALU utilization at run time... And also scale your chip portfolio on ALU count. Perfect scalability in price, performance and power combined with straightforward driver work.
Awesome!
rootheday - Thursday, July 3, 2014 - link
Transaction Elimination might work for "render to texture", where the texture is then used later in the scene, but it doesn't make sense to me for the final render target that is shown on the screen.. Typically your final render target is part of a swap chain with 2 or 3 different buffers. So the CRC computed for a tile in Frame N would need to match the CRC for frame N-2 (or maybe N-3), not N-1.EdvardS - Thursday, July 3, 2014 - link
So each buffer has its own CRC buddy attached to it - problem solved :-) Longer buffer chains just reduces you temporal coherency a bit.hexgrid - Thursday, July 3, 2014 - link
Relying on a 32bit hash for transaction elimination is a very bad idea. Assuming a normal distribution of hash results, the Birthday Paradox means you've got a better than 50% chance of collision if you have more than ~5000 items being hashed. The compartmentalized comparisons (it looks like they only compare against the same tile) means the collision rate will be lower, but there will be collisions, and in some cases they will look terrible.If there's a glitch, there's an excellent chance it will persist for a while. For example, let's say I'm bringing up a "pause" menu. If the title overlay of the pause menu happens to hash to the same value as the background that it replaced, that one tile of the pause menu title won't appear. Next frame, it still won't appear, because again the hash value hasn't changed. Until something happens to actually change the title or make it disappear, the glitch will persist.
The "fix" will be to do GUI overlays in translucency and keep the background animating somehow to prevent cache misses from sticking around, but it's an ugly hardware hack that will force software workarounds.
EdvardS - Thursday, July 3, 2014 - link
What if the CRC is 64 bit for each small tile? Quite overkill and very hard to break.mkozakewich - Sunday, July 6, 2014 - link
If the pause screen fades in, wouldn't that change the image data enough that it would generate entirely different CRCs for each frame until the animation ended?At any rate, my rule of thumb would be that if it doesn't happen more often than a keyframe is dropped in a video, it'll be fine.
Krysto - Thursday, July 3, 2014 - link
I'd like you guys to do more 30x GFX loops, that how whether these GPU's only prop up high numbers at first, but then quickly get throttled. From what I noticed Imagination is the only one that doesn't throttle in that test. But I'm curious to see if K1 and T760 do.