Samsung SSD 850 Pro (128GB, 256GB & 1TB) Review: Enter the 3D Era
by Kristian Vättö on July 1, 2014 10:00 AM ESTRAPID 2.0: Support For More RAM & Updated Caching Algorithm
When the 840 EVO launched a year ago, Samsung introduced a new feature called RAPID (Real-time Accelerated Processing of I/O Data). The idea behind RAPID is very simple: it uses the excess DRAM in your system to cache IOs, thus accelerating storage performance. Modern computers tend to have quite a bit of DRAM that is not always used by the system, so RAPID turns a portion of that into a DRAM cache.
With the 850 Pro, Samsung is introducing Magician 4.4 along with an updated version of RAPID. The 1.0 version of RAPID supported up to 1GB of DRAM (or up to 25% if you had less than 4GB of RAM) but the 2.0 version increases the RAM allocation to up to 4GB if you have 16GB of RAM or more. There is still the same 25% limit, meaning that RAPID will not use 4GB of your RAM if you only have 8GB installed in your system.
I highly recommend that you read the RAPID page of our 840 EVO review because Anand explained the architecture and behavior of RAPID in detail, so I will keep the fundamentals short and focus on what has changed.
In addition to increasing the RAM allocation, Samsung has also improved the caching algorithms. Unfortunately, I was not able to get any details before the launch but I am guessing that the new version includes better optimization for file types and IO sizes that get the biggest benefit from caching. Remember, while RAPID works at the block level, the software also looks at the file types to determine what files and IO blocks should be prioritized. The increased RAM allocation also needs an optimized set of caching algorithms because with a 4GB cache RAPID is able to cache more data at a time, which means it can relax the filetype and block size restrictions (i.e. it can also cache larger files/IOs).
To test how the new version of RAPID performs, I put it through our Storage Benches as well as PCMark 8’s storage test. Our testbed is equipped with 32GB of RAM, so we should be able to get the full benefit of RAPID 2.0.
| Samsung SSD 850 Pro 256GB | ||||
| ATSB - Heavy 2011 Workload (Avg Data Rate) | ATSB - Heavy 2011 Workload (Avg Service Time) | ATSB - Light 2011 Workload (Avg Data Rate) | ATSB - Light 2011 Workload (Avg Service Time) | |
| RAPID Disabled | 310.8MB/s | 676.7ms | 366.6MB/s | 302.5ms |
| RAPID Enabled | 549.1MB/s | 143.4ms | 664.4MB/s | 134.6ms |
The performance increase in our Storage Benches is pretty outstanding. In both the Heavy and Light suites the increase in throughput is around 80%, making the 850 Pro even faster than the Samsung XP941 PCIe SSD.
| Samsung SSD 850 Pro 1TB | ||||
| PCMark 8 - Storage Score | PCMark 8 - Storage Bandwidth | |||
| RAPID Disabled | 4998 | 298.6MB/s | ||
| RAPID Enabled | 5046 | 472.8MB/s | ||
PCMark 8, on the other hand, tells a different story. As you can see, the bandwidth is again much faster, about 60%, but the storage score is only a mere 1% higher.
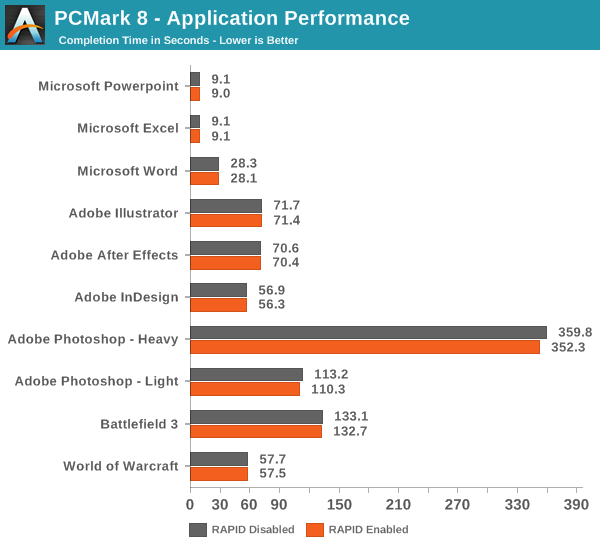
PCMark 8 also records the completion time of each task in the storage suite, which gives us an explanation as to why the storage scores are about equal. The fundamental issue is that today’s applications are still designed with hard drives in mind, meaning that they cannot utilize the full potential of SSDs. Even though the throughput is much higher with RAPID, the application performance is not because the software has been designed to wait several milliseconds for each IO to complete, so it does not know what to do when the response time is suddenly in the magnitude of a millisecond or two. That is why most applications load the necessary data to RAM when launched and only access storage when it is a must as back in the hard drive days, you wanted to avoid touching the hard drive as much as possible.
It will be interesting to see what the industry does with the software stack over the next few years. In the enterprise, we have seen several OEMs release their own APIs (like SanDisk’s ZetaScale) so companies can optimise their server software infrastructure for SSDs and take the full advantage of NAND. I do not believe that a similar approach works for the client market as ultimately everything is on the hands of Microsoft.
I also tried running the 2013 suite, a.k.a. The Destroyer, but for some reason RAPID did not like that and the system BSODed midway through the test. I am thinking that this is because our Storage Benches are ran without a partition, whereas RAPID also works at the file system level in the sense that it takes hints of what files should be cached. Due to that, it may be as simple as that under a high queue depth workload (like the ATSB2013), RAPID does not know what IOs to cache because there is no filesystem to guide it. I faced the same BSOD issue immediately when I fired up our IO consistency test (also ran without a partition), but when I tested with a similar 4KB random write workload using the new Iometer (which supports filesystem testing), there was absolutely no issue. This further suggests that the issue lies in our tests instead of the RAPID software itself as end-users will always run the drive with a partition anyway.
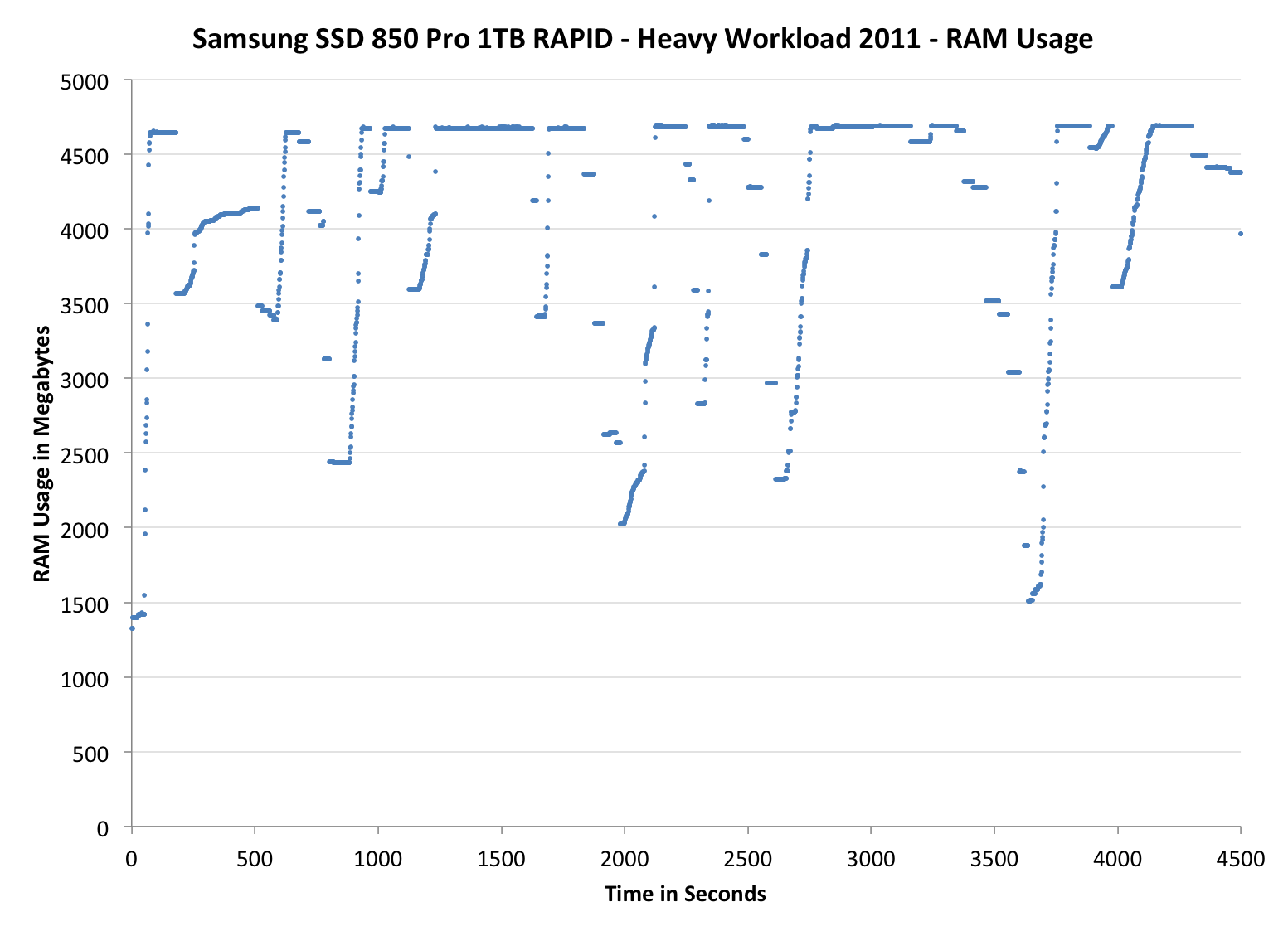
As Anand mentioned in the 840 EVO review, it is possible to monitor RAPID’s RAM usage by looking at the non-paged RAM pool. Instead of just looking at the resource monitor, I decided to take the monitoring one step further by recording the RAM usage over time with Windows’ Performance Monitor while running the 2011 Heavy workload. RAPID seems to behave fairly aggressively when it comes to RAM caching as the RAM usage increases to ~4.7GB almost immediately after firing up the test and stays there almost throughout the test. There are some drops, although I am not sure what is causing them. The idle times are limited to a maximum of 25 seconds when running the trace, so some drops could be caused by that. I need to do run some additional test and monitor the IOs to see if it is just the idle times of whether RAPID is excluding certain types of IOs.

I also ran ATTO to see how the updated RAPID responses to different transfer sizes. It looks like read performance scales quite linearly until hitting the IO size of 256KB. ATTO stores its performance values in 32-bit integers and with RAPID enabled performance exceeds the size of the result variable, thus wrapping around back to 0.
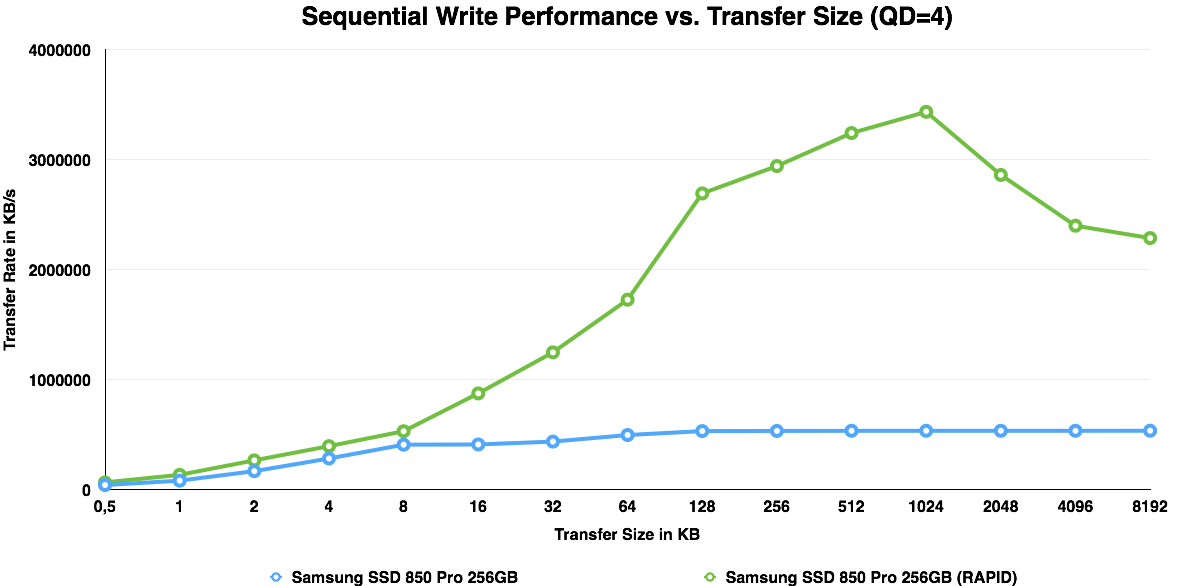
With writes, RAPID continues to cache fluently until hitting 1MB, which is when it starts to cache less aggressively.








160 Comments
View All Comments
Squuiid - Saturday, March 14, 2015 - link
Plus, the MX100 reliability is horrible. Just google MX100 BSOD, disappearing drive.I have 2x MX100 512GB SSDs and I recommend you don't buy one, no matter how cheap they are.
nightauthor - Tuesday, July 1, 2014 - link
For business purposes, I would rather pay twice as much and get a 10 year warranty vs the 3 year supplied by Crucial. Though, for my daily, I would probably go with the Crucial.TheWrongChristian - Wednesday, July 2, 2014 - link
No current SATA drives push low queue depth random IOs to the point of saturating SATA II, let alone SATA III.At high queue depths, perhaps. But then, that is not a typical workload for most users, desktop or server.
Plus, it's a new drive, prices will come down.
jwcalla - Monday, June 30, 2014 - link
Unless they're doing 5% OP the capacities are kinda... off.melgross - Monday, June 30, 2014 - link
I think there's a slight misunderstanding of manufacturing cost. While the die size may be the same, or even smaller than a competing technology, the 32 level chip does cost more to make per area. There are more masks, more layers, more etching and washing cycles, and more chance of defects.Right now, I do see why the cost is higher. I can on,y assume that as this technology progresses, that cost will drop per area. But it will always remain higher than an SLC, MLC or TLC chip.
So there is a balance here.
Kristian Vättö - Tuesday, July 1, 2014 - link
You are correct. I did mention yield and equipment cost in the final paragraph but I figured I won't go into detail about masks and etching since those would have required an in-depth explanation of how NAND is manufactured :)R0H1T - Tuesday, July 1, 2014 - link
It would be great if Anand or you do a writeup on 3d NAND & deal with the specific pros & cons of it as compared to traditional 2d NAND & if possible include something related to manufacturing processes of these & how they're different OR more/less expensive, certainly as in case of V-NAND?MrSpadge - Tuesday, July 1, 2014 - link
You wouldn't need too much detail - just saying that the number of process steps increases by probably around an order of magnitude should make this pretty clear.frenchy_2001 - Tuesday, July 1, 2014 - link
It is probably more than that, as Samsung is currently manufacturing 32 layers of cells. Each layer requires multiple operations (deposit, etching, washing...). Their biggest advantage comes from regressing to 40nm: at that technology, each operation is *MUCH* cheaper than the equivalent one at 1X pitch (15~19nm).So, total cost is an unknown, but should be very competitive, after recovering the initial R&D investment.
Spatty - Tuesday, July 1, 2014 - link
And not to mention 3D NAND is still basically bleeding edge. It's still in the stages of where a new DDR generation arrives, much higher costs then current gen.