Intel Xeon E5-2697 v2 and Xeon E5-2687W v2 Review: 12 and 8 Cores
by Ian Cutress on March 17, 2014 11:59 AM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
The Mac Pro (Late 2013)
When Anand reviewed the Mac Pro late last year, he received the full fat 12 core edition, using the E5-2697 v2 CPU with a 2.7 GHz rating. The CPU choices for the Mac Pro include 4, 6 and 8 core models, all with HyperThreading. Interestingly enough, the 4/6/8 core models all come from the E5-16xx line, meaning the CPUs are designed with single processor systems in mind. But to get to the 12 core/24 thread model at the high end, Apple used the E5-2697 v2, a processor optimized for dual CPU situations. Based on the die shots on the previous page, this has repercussions, but as Anand pointed out, it all comes down to power usage and turbo performance.
| Mac Pro (Late 2013) CPU Options | ||||||
| Intel CPU | E5-1620 v2 | E5-1650 v2 | E5-1680 v2 | E5-2697 v2 | ||
| Cores / Threads | 4 / 8 | 6 / 12 | 8 / 16 | 12 / 24 | ||
| CPU Base Clock | 3.7GHz | 3.5GHz | 3.0GHz | 2.7GHz | ||
| Max Turbo (1C) | 3.9GHz | 3.9GHz | 3.9GHz | 3.5GHz | ||
| L3 Cache | 10MB | 12MB | 25MB | 30MB | ||
| TDP | 130W | 130W | 130W | 130W | ||
| Intel SRP | $294 | $583 | ? | $2614 | ||
The Mac Pro is designed within a peak 450W envelope, and Intel has options with its CPUs. For the same TDP limit, Intel can create many cores as low frequency, or fewer cores at higher frequency. This is seen in the options on the Mac Pro – all the CPU choices have the same 130W TDP, but the CPU base clocks change as we rise up the core count. Moving from 4 cores to 8 cores keeps the maximum turbo (single core performance) at 3.9 GHz, but the base clock decreases the more cores are available. Finally at the 12-core model, the base frequency is at its lowest of the set, as well as the maximum turbo.
This has repercussions on workloads, especially for workstations. For the most part, the types of applications used on workstations are highly professional, and have big budgets with plenty of engineers designed to extract performance. That should bode well for the systems with more cores, despite the frequency per core being lower. However, it is not always that simple – the mathematics for the problem has to be able to take advantage of parallel computing. Simple programs run solely on one core because that is the easiest to develop, but if the mathematics wholly linear, then even enterprise software is restricted. This would lend a positive note to the higher turbo frequency CPUs. Intel attempts to keep the turbo frequency similar as long as it can while retaining the maximum TDP to avoid this issue; however at the 12-core model this is not possible. Quantifying your workload before making a purchase is a key area that users have to consider.
Benchmark Configuration
I talk about the Mac Pro a little because the processors we have for a ‘regular’ test today are 8-core and 12-core models. The 12-core is the same model that Anand tested in the Mac Pro – the Xeon E5-2697v2. The 8-core model we are testing today is different to the one offered in the Mac Pro, in terms of frequency and TDP:
| Intel SKU Comparison | |||
| Core i7-4960X | Xeon E5-2687W v2 | Xeon E5-2697 v2 | |
| Release Date | September 10, 2013 | September 10, 2013 | September 10, 2013 |
| Cores | 6 | 8 | 12 |
| Threads | 12 | 16 | 24 |
| Base Frequency | 3600 | 3400 | 2700 |
| Turbo Frequency | 4000 | 4000 | 3500 |
| L3 Cache | 15 MB | 25 MB | 30 MB |
| Max TDP | 130 W | 150 W | 130 W |
| Max Memory Size | 64 GB | 256 GB | 768 GB |
| Memory Channels | 4 | 4 | 4 |
| Memory Frequency | DDR3-1866 | DDR3-1866 | DDR3-1866 |
| PCIe Revision | 3.0 | 3.0 | 3.0 |
| PCIe Lanes | 40 | 40 | 40 |
| Multi-Processor | 1P | 2P | 2P |
| VT-x | Yes | Yes | Yes |
| VT-d | Yes | Yes | Yes |
| vPro | No | Yes | Yes |
| Memory Bandwidth | 59.7 GB/s | 59.7 GB/s | 59.7 GB/s |
| Price | $1059 | $2112 | $2618 |
The reason for this review is to put these enterprise class processors through the normal (rather than server) benchmarks I run at AnandTech for processors. Before I started writing about technology, as an enthusiast, it was always interesting to hear of the faster Xeons and how much that actually made a difference to my normal computing. I luckily have that opportunity and would like to share it with our readers.
The system set up is as follows:
| Test Setup | |
| Motherboards |
GIGABYTE GA-6PXSV3 MSI X79A-GD45 Plus for 3x GPU Configurations |
| Memory | 8x4 GB Kingston DDR3-1600 11-11-11 ECC |
| Storage | OCZ Vertex 3 256 GB |
| Power Supply | OCZ 1250 ZX Series |
| CPU Cooler | Corsair H80i |
| NVIDIA GPU | MSI GTX 770 Lightning 2GB |
| AMD GPU | ASUS HD 7970 3GB |
Many thanks to...
We must thank the following companies for kindly providing hardware for our test bed:
Thank you to GIGABYTE Server for providing us with the Motherboard and CPUs
Thank you to OCZ for providing us with 1250W Gold Power Supplies and SSDs.
Thank you to Kingston for the ECC Memory kit
Thank you to ASUS for providing us with the AMD HD7970 GPUs and some IO Testing kit.
Thank you to MSI for providing us with the NVIDIA GTX 770 Lightning GPUs.
Power Consumption
Power consumption was tested on the system as a whole with a wall meter connected to the OCZ 1250W power supply, while in a single MSI GTX 770 Lightning GPU configuration. This power supply is Gold rated, and as I am in the UK on a 230-240 V supply, leads to ~75% efficiency > 50W, and 90%+ efficiency at 250W, which is suitable for both idle and multi-GPU loading. This method of power reading allows us to compare the power management of the UEFI and the board to supply components with power under load, and includes typical PSU losses due to efficiency. These are the real world values that consumers may expect from a typical system (minus the monitor) using this motherboard.
While this method for power measurement may not be ideal, and you feel these numbers are not representative due to the high wattage power supply being used (we use the same PSU to remain consistent over a series of reviews, and the fact that some boards on our test bed get tested with three or four high powered GPUs), the important point to take away is the relationship between the numbers. These boards are all under the same conditions, and thus the differences between them should be easy to spot.
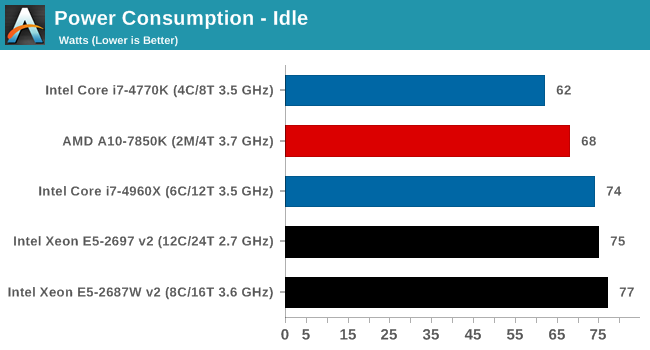
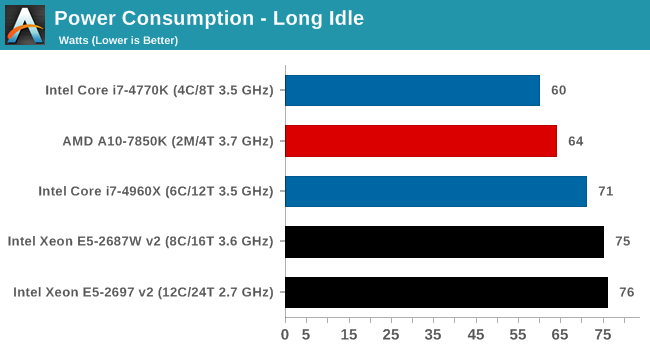
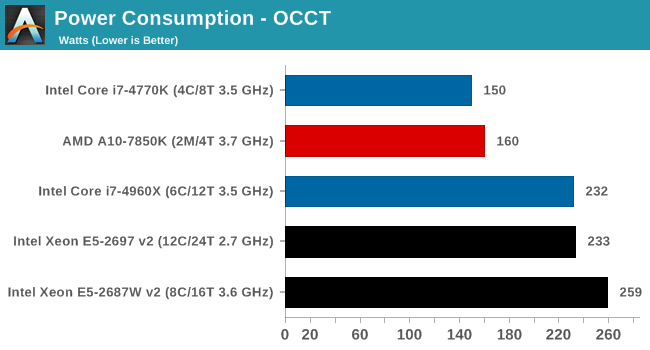
At idle, the Xeons are on par with the Core i7-4960X for power consumption in the GIGABYTE motherboard. At load the extra TDP of the E5-2687W v2 can be seen.
DPC Latency
Deferred Procedure Call latency is a way in which Windows handles interrupt servicing. In order to wait for a processor to acknowledge the request, the system will queue all interrupt requests by priority. Critical interrupts will be handled as soon as possible, whereas lesser priority requests, such as audio, will be further down the line. So if the audio device requires data, it will have to wait until the request is processed before the buffer is filled. If the device drivers of higher priority components in a system are poorly implemented, this can cause delays in request scheduling and process time, resulting in an empty audio buffer – this leads to characteristic audible pauses, pops and clicks. Having a bigger buffer and correctly implemented system drivers obviously helps in this regard. The DPC latency checker measures how much time is processing DPCs from driver invocation – the lower the value will result in better audio transfer at smaller buffer sizes. Results are measured in microseconds and taken as the peak latency while cycling through a series of short HD videos - less than 500 microseconds usually gets the green light, but the lower the better.
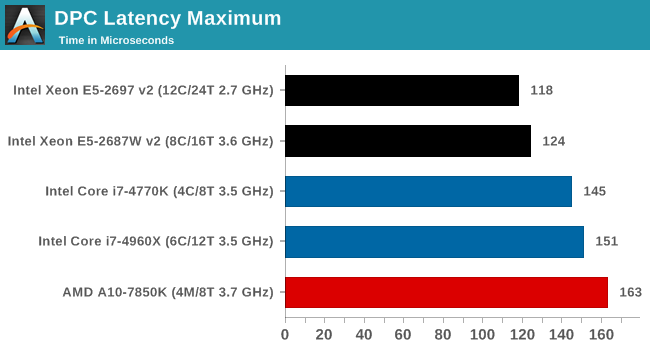
The DPC latency of the Xeons is closer to the 100 mark, which we saw during Sandy Bridge. Newer systems seem to be increasing the DPC latency - so far all Haswell consumer CPUs are at the 140+ line.








71 Comments
View All Comments
XZerg - Monday, March 17, 2014 - link
this bench also shows that the haswell had almost no CPU related performance benefits over IVB (if not slowed down performance) looking at 3770k vs 4770k and that haswell ups the gpu performance only.i really question intel's skuing of haswell...
Nintendo Maniac 64 - Monday, March 17, 2014 - link
Emulation?BMNify - Monday, March 17, 2014 - link
its a shame they didn't do a UHD x264 encode here as that would have shown a haswell AVX2 improvement (something like 90% over AVX), and why people will have to wait for the xeons to catch up to at least AVX2 if not AVX3.1psyq321 - Wednesday, March 19, 2014 - link
There is no "90% speedup over AVX" between HSW and IVB architectures.AVX (v1) is floating point only and thus was useless for x264. For floating point workloads you would be very lucky to get 10% improvement by jumping to AVX2. The only difference between AVX and AVX2 for floating point is the FMA instruction and gather, but gather is done in microcode for Haswell, so it is not actually much faster than manually gathering data.
Now, x264 AVX2 is a big improvement because it is an integer workload, and with AVX (v1) you could not do that. So x264 is jumping from SSE4.x to AVX2, which is a huge jump and it allows much more efficient processing.
For integer workloads that can be optimized so that you load and process eight 32-bit values at once, AVX2 Xeon EPs/EXs will be a big thing. Unfortunately, this is not so easy to do for a general-purpose algorithms. x264 team did the great job, but I doubt you will be using 14 core single Haswell EP (or 28 core dual CPU) for H.264 transcoding. This job can be done probably much more efficient with dedicated accelerators.
As for the scientific applications, they already benefit from AVX v1 for floating point workloads. AVX2 in Haswell is just a stop-gap as the gather is microcoded, but getting code ready for hardware gather in the future uArch is definitely a good way to go.
Finally, when Skylake arrives with AVX 3.1, this will be the next big jump after AVX (v1) for scientific / floating point use cases.
Kevin G - Monday, March 17, 2014 - link
Shouldn't both the Xeon E5-2687W v2 support 384 GB of memory? 4 channels * 3 slots per channel * 32 GB DIMM per slot? (Presumably it could be twice that using eight rank 64 GB DIMMs but I'm not sure if Intel has validated them on the 6 and 10 core dies.) Registered memory has to be used for the E6-2687w v2 to get to 256 GB, just is the chip not capable of running a third slots per channel? Seems like a weird handicap. I can only imagine this being more of a design guideline rule than anything explicit. The 150W CPU's are workstation focused which tend to only have 8 slots maximum.Also a bit weird is the inclusion of the E5-2400 series on the first page's table. While they use the same die, they use a different socket (LGA 1356) with triple memory support and only 24 PCI-e lanes. With the smaller physical area and generally lower TDP's, they're aimed squarely the blade server market. Socket LGA 2011 is far more popular in the workstation and 1U and up servers.
jchernia - Monday, March 17, 2014 - link
A 12 core chip is a server chip - the workstation/PC benchmarks are interesting, but the really interesting benchmarks would be on the server side.Ian Cutress - Monday, March 17, 2014 - link
Johan covered the server side in his article - I link to it many times in the review:http://www.anandtech.com/show/7285/intel-xeon-e5-2...
BMNify - Monday, March 17, 2014 - link
a mass of other's might argue a 12 core/24 thread chip or better is a potential "real-time" UHD x264 encoding machine , its just out of most encoders budgets, so NO SALE....Nintendo Maniac 64 - Monday, March 17, 2014 - link
Uh, where's the test set up for the 7850K?Nintendo Maniac 64 - Monday, March 17, 2014 - link
Also I believe I found a typo:"Haswell provided a significant post to emulator performance"
Shouldn't this say 'boost' rather than 'post'?