Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
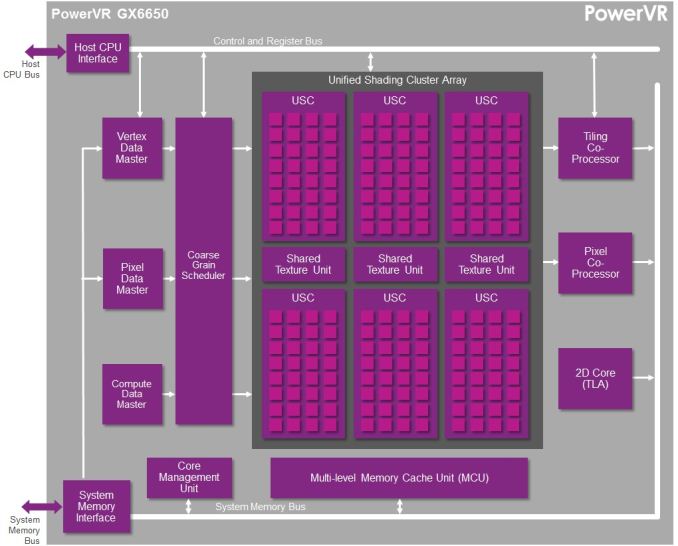
When it comes to our coverage of SoCs, one aspect we’ve been trying to improve on for some time now is our coverage and understanding of the GPU portion of those SoCs. In the PC space we’re fortunate that there are just three major players – Intel, NVIDIA, and AMD – and that all three of them have over the years learned how to become very open and forthcoming about their GPU architectures. As a result we’ve had a level of access that has allowed us to better understand PC GPUs in a way that in earlier times simply wasn’t possible.
In the SoC space however we haven’t been so fortunate. Our understanding of most SoC GPU architectures has not been nearly as deep due to the fact that SoC GPU designers have been less willing to come forward with public details about their architectures and how those architectures have evolved over the years. And this has been for what’s arguably a good reason – unlike the PC GPU space, where only 2 of the 3 players compete in either the iGPU or dGPU markets, in the SoC GPU space there are no fewer than 7 players, all of whom are competing in one manner or another: NVIDIA, Imagination Technologies, Intel, ARM, Qualcomm, Broadcom, and Vivante.
Some of these players use their designs internally while others license out their designs as IP for inclusion in 3rd party SoCs, but all these players are in a much more competitive market that is in a younger place in its life. All the while SoC GPU development still happens at a relatively quick pace (by GPU standards), leading to similarly quick turnarounds between GPU generations as GPU complexity has not yet stretched out development to a 3-4 year process. As a result of SoC GPUs still being a young and highly competitive market, it’s a foregone conclusion that there is still a period of consolidation ahead of us – not unlike what has happened to SoC integrators such as TI – which provides all the more reason for SoC GPU players to be conservative about providing public details about their architectures.
With that said, over the years we have made some progress in getting access to the technical details, due in large part to the existing openness policies of NVIDIA and Intel. Nevertheless, as two of the smaller players in the mobile GPU space this still leaves us with few details on the architectures behind the majority of SoC GPUs. We still want more.
This brings us to today. In what should prove to be an extremely eventful and important day for our coverage and understanding of SoC GPUs, we’d like to welcome Imagination Technologies to the “open architecture” table. Imagination chosen to share more details about the inner workings of their Rogue Series 6 and Series 6XT architectures, thereby giving us our first in-depth look at the architecture that’s powering a number of high-end products (not the least of which is all of Apple’s current-gen products) and descended from some of the most widely used SoC GPU designs of all time.

Now Imagination is not going to be sharing everything with us today. The bulk of the details Imagination is making available relate to their Unified Shading Cluster (USC) shading block, the heart of the Series 6/6XT GPUs. They aren’t discussing other aspects of their designs such as their geometry processors, cache structure, or Tile Based Deferred Rendering system – the company’s secret sauce and most potent weapon for SoC efficiency – but hopefully one day we’ll get there. In the meantime we will have our hands full just taking our first look at the Series 6/6XT USCs.
Finally, before we begin we’d like to thank Imagination for giving us this opportunity to evaluate their architecture in such great detail. We’ve been pushing for this for quite some time, so we’re pleased that this is coming to pass.
Imagination is publishing a pair of blogs and pseudo whitepapers on their website today: Graphics cores: trying to compare apples to apples, and PowerVR GX6650: redefining performance in mobile with 192 cores. Along with this they have also been answering many of our deepest technical questions, so we should have a good handle on the Rogue USC. So with that in mind, let’s dive in.








95 Comments
View All Comments
Ryan Smith - Monday, February 24, 2014 - link
Aww geeze. I can't believe we put a whole extra row in there...Thank you for pointing that out. It has been corrected (along with everything else you mentioned).
boostern - Monday, February 24, 2014 - link
One question for Ryan: you said that having 12 ROPs is alittle bit strange given the bandwidth constraints in the mobile world. In an earlier article (2011 http://www.anandtech.com/show/4686/samsung-galaxy-... ) anand draw a picture explaing the savings in term of bandwidth of a TBDR architecture: http://images.anandtech.com/reviews/smartphones/sa...Do you think that taking into account this bandwidth savings, those 12 ROPs would make more sense?
Thank you in advance and sorry for my english.
ryszu - Monday, February 24, 2014 - link
The fillrate we have is largely agnostic of the TBDR and its bandwidth savings. It's there for high resolution UIs more than anything else.boostern - Monday, February 24, 2014 - link
Thank you Rys.Are you the Rys of Beyond 3D that works for IMGTec?
ryszu - Monday, February 24, 2014 - link
Guilty as charged!boostern - Monday, February 24, 2014 - link
What an honour :)MrPoletski - Sunday, March 9, 2014 - link
By the way, how does the PowerVR architecture do at cryptocoin mining?MrSpadge - Saturday, March 1, 2014 - link
If the front end runs at half the ALU clock I wonder if the ROPS might also run at half clock? In this case it would make sense to put more of them in.Krysto - Monday, February 24, 2014 - link
From everything I've seen so far, PowerVR5 Series was more ahead of the competition than PowerVR6 Series is right now. In fact Nvidia has already surpassed them, especially when you consider the full OpenGL 4.4 API support, and Adreno and Mali have become very competitive, too, and Mali T760 should also have around 380 Gflops of performance, along with hardware assisted global illumination.I think the days of PowerVR/Apple devices having higher GPU performance than competition are behind us, and it's for the best.
ryszu - Monday, February 24, 2014 - link
Why is it for the best?