Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
When it comes to our coverage of SoCs, one aspect we’ve been trying to improve on for some time now is our coverage and understanding of the GPU portion of those SoCs. In the PC space we’re fortunate that there are just three major players – Intel, NVIDIA, and AMD – and that all three of them have over the years learned how to become very open and forthcoming about their GPU architectures. As a result we’ve had a level of access that has allowed us to better understand PC GPUs in a way that in earlier times simply wasn’t possible.
In the SoC space however we haven’t been so fortunate. Our understanding of most SoC GPU architectures has not been nearly as deep due to the fact that SoC GPU designers have been less willing to come forward with public details about their architectures and how those architectures have evolved over the years. And this has been for what’s arguably a good reason – unlike the PC GPU space, where only 2 of the 3 players compete in either the iGPU or dGPU markets, in the SoC GPU space there are no fewer than 7 players, all of whom are competing in one manner or another: NVIDIA, Imagination Technologies, Intel, ARM, Qualcomm, Broadcom, and Vivante.
Some of these players use their designs internally while others license out their designs as IP for inclusion in 3rd party SoCs, but all these players are in a much more competitive market that is in a younger place in its life. All the while SoC GPU development still happens at a relatively quick pace (by GPU standards), leading to similarly quick turnarounds between GPU generations as GPU complexity has not yet stretched out development to a 3-4 year process. As a result of SoC GPUs still being a young and highly competitive market, it’s a foregone conclusion that there is still a period of consolidation ahead of us – not unlike what has happened to SoC integrators such as TI – which provides all the more reason for SoC GPU players to be conservative about providing public details about their architectures.
With that said, over the years we have made some progress in getting access to the technical details, due in large part to the existing openness policies of NVIDIA and Intel. Nevertheless, as two of the smaller players in the mobile GPU space this still leaves us with few details on the architectures behind the majority of SoC GPUs. We still want more.
This brings us to today. In what should prove to be an extremely eventful and important day for our coverage and understanding of SoC GPUs, we’d like to welcome Imagination Technologies to the “open architecture” table. Imagination chosen to share more details about the inner workings of their Rogue Series 6 and Series 6XT architectures, thereby giving us our first in-depth look at the architecture that’s powering a number of high-end products (not the least of which is all of Apple’s current-gen products) and descended from some of the most widely used SoC GPU designs of all time.

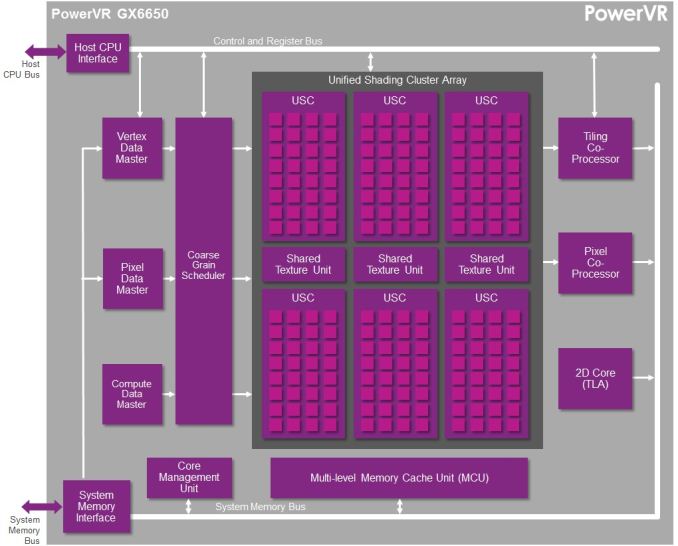
Now Imagination is not going to be sharing everything with us today. The bulk of the details Imagination is making available relate to their Unified Shading Cluster (USC) shading block, the heart of the Series 6/6XT GPUs. They aren’t discussing other aspects of their designs such as their geometry processors, cache structure, or Tile Based Deferred Rendering system – the company’s secret sauce and most potent weapon for SoC efficiency – but hopefully one day we’ll get there. In the meantime we will have our hands full just taking our first look at the Series 6/6XT USCs.
Finally, before we begin we’d like to thank Imagination for giving us this opportunity to evaluate their architecture in such great detail. We’ve been pushing for this for quite some time, so we’re pleased that this is coming to pass.
Imagination is publishing a pair of blogs and pseudo whitepapers on their website today: Graphics cores: trying to compare apples to apples, and PowerVR GX6650: redefining performance in mobile with 192 cores. Along with this they have also been answering many of our deepest technical questions, so we should have a good handle on the Rogue USC. So with that in mind, let’s dive in.








95 Comments
View All Comments
Sonicadvance1 - Tuesday, February 25, 2014 - link
Thanks for the response. Good to know. The article didn't really note anything about it.ryszu - Tuesday, February 25, 2014 - link
I misspoke actually, integer is a separate pipe in Rogue.Sonicadvance1 - Thursday, February 27, 2014 - link
Alright, then how much slower is Integer performance compared to floating point? Integer performance is an area that Nvidia struggles with as well.MrSpadge - Saturday, March 1, 2014 - link
This sounds different from any material Ryan showed or discussed. Could you elaborate, may directly to Ryan and have him update the article?Frenetic Pony - Monday, February 24, 2014 - link
I'm not sure what exactly is being babbled on about with tile based deferred rendering. It's just software, anyone can write and run it. Go onto a friendly GPU programming forum and they'll take you through it step by step.Scali - Monday, February 24, 2014 - link
Deferred rendering is a software solution. Tile-based deferred rendering is a hardware solution. The GPU cuts up the triangles in a set of tiles. Inside the GPU, there is a superfast 'framebuffer' the size of a tile (think of a special L1-cache). The GPU renders one tile at a time into this buffer, solving overdraw very quickly and efficiently, then it burst-writes the tile out to the framebuffer in videomemory. PowerVR has been using this technology since the early days of 3D acceleration (I have a PowerVR PCX2 card myself, and did a blog on it a while ago: http://scalibq.wordpress.com/2012/12/18/just-keepi...I suggest you read up on it, it is very interesting technology, and unlike any competing GPU.
Frenetic Pony - Monday, February 24, 2014 - link
No it isn't. Anyone with the proper feature set can do tile based deferred, most next gen games are going to be culling light lists out on something like an 8x8 pixel per tile basis, whether that's for forward rending or deferred. Which sounds exactly like what you described.It might be nice that there's some special little cache for it in PowerVr. But the basic idea as you've described it sounds exactly the same in principle as what DICE/EA's Frostbite does, as well as any number of other papers and games coming do.
Scali - Monday, February 24, 2014 - link
No, I don't think you quite get it. Culling lights in tiles is something different.In this case the geometry is batched up before drawing, then binned to tiles, and then the visibility (z-order) is solved on a per-tile basis.
It may sound the same as deferred rendering tricks in software, but it is not quite the same. These software tricks depend on multiple rendering passes, with z/stenciltesting to determine which pixels to shade. PowerVR can do it in a single pass (as far as the software is concerned).
Again, I suggest you read up on it.
Scali - Monday, February 24, 2014 - link
In fact, the PowerVR PCX2 card did not even need a z-buffer in videomemory at all. What "feature set" on a regular GPU would be able to render properly without a z-buffer?MrPoletski - Sunday, March 9, 2014 - link
Exactly, the Z-buffer is on chip. Incidentally, Multi-sampling AA increases your Z-buffer and framebuffer bandwidth requirements by a factor of x (for 4x AA). What if that were all on chip?I can't believe IMGTEC haven't made more noise about this.