The Intel Xeon E7 v2 Review: Quad Socket, Up to 60 Cores/120 Threads
by Johan De Gelas on February 21, 2014 6:00 AM EST- Posted in
- IT Computing
- Intel
- Xeon
- Ivy Bridge EX
- server
- Brickland
OpenFoam
Several of our readers have already suggested that we look into OpenFoam. That's easier said than done, as good benchmarking means you have to master the sofware somewhat. Luckily, my lab was able to work with the professionals of Actiflow. Actiflow specialises in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFoam to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.

The Ferrari 599: an improved product thanks to Openfoam.
We were allowed to use one of their test cases as a benchmark, but we are not allowed to discuss the specific solver. All tests were done on OpenFoam 2.2.1 and openmpi-1.6.3.
Many CFD calculations do not scale well on clusters, unless you use InfiniBand. InfiniBand switches are quite expensive and even then there are limits to scaling. We do not have an InfiniBand switch in the lab, unfortunately. Although it's not as low latency as InfiniBand, we do have a good 10G Ethernet infrastructure, which performs rather well.
So we added a fifth configuration to our testing: the quad-node Intel Server System H2200JF. The only CPU that we have eight of right now is the Xeon E5-2650L 1.8GHz. Yes, it is not perfect, but this is the start of our first clustered HPC benchmark. This way we can get an of idea whether or not the Xeon E7 v2 platform can replace a complete quad-node cluster system and at the same time offer much higher RAM capacity.
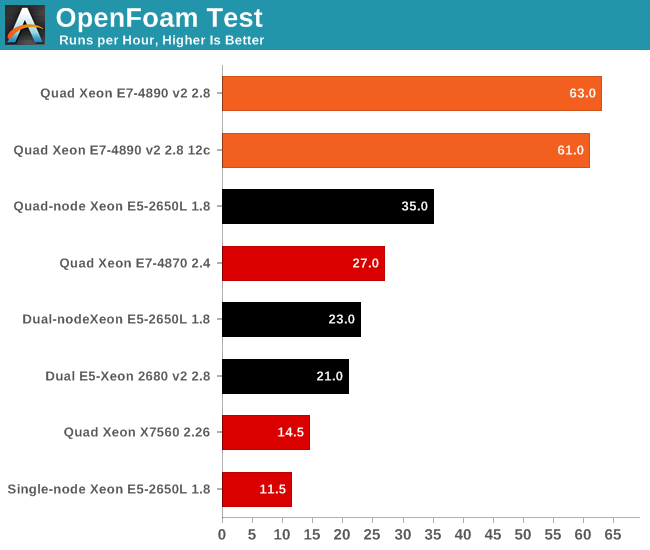
The results are pretty amazing: the quad Xeon E7-4980 v2 runs circles around our quad-node HPC cluster. Even if we were to outfit it with 50% higher clocked Xeons, the quad Xeon E7 v2 would still be the winner. Of course, there is no denying that our quad-node cluster is a lot cheaper to buy. Even with an InfiniBand switch, an HPC cluster with dual socket servers is a lot cheaper than a quad socket Intel Xeon E7 v2.
However, this bodes well for the soon to be released Xeon E5-46xx v2 parts. QPI links are even lower latency than InfiniBand. But since we do not have a lot of HPC testing experience, we'll leave it up to our readers to discuss this in more detail.
Another interesting detail is that the Xeon 2650L at 1.8GHz is about twice as fast as a Xeon L5650. We found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance tremendously. Seasoned OpenFoam users, let us know whether is the accurate assessment.








125 Comments
View All Comments
Kevin G - Monday, February 24, 2014 - link
"Thus, the x86 does not scale above 8-sockets."The SGI UV2000 is a fully cache coherent server that scales up to 256 sockets. It uses some additional glue logic but this is no different than what Oracle uses to obtain similar levels of scalibility.
"Some examples of Scale-out servers (clusters) are all servers on the Top-500 supercomputer list. Other examples are SGI Altix / UV2000 servers... Scale-up servers, are one single fat huge server."
SGI correctly classifies these as scale-up servers as they are not a cluster. ( http://www.sgi.com/products/servers/uv/ )
"The reason is the Linux kernel devs does not have access to 32 socket SMP server, because they dont exist, so how can Linux kernel be optimized for 32 sockets?"
"Ted Tso, the famous Linux kernel developer writes:
http://thunk.org/tytso/blog/2010/11/01/i-have-the-... "
Oh wow, you're confusing a file system with the kernel. You do realize that Linux has suport for many different file systems? Even then Ext4 is actually shown to scale after a few patches per that link. Also of particular note is that 4 years ago when that article was writen Ext4 was not suited for production purposes. In the years since, this has changed as has its scalability.
"For instance the Big Tux HP server, compiled Linux to 64 socket HP integrity server with catastrophic results, the cpu utilization was ~40%, which means every other cpu idles under full load. Google on Big Tux and read it yourself."
Big Tux was an ancient Itanium server that was constrained by equally ancient FSB architecture. Even with HP-UX, developers are lucky to get high utilization rates due to the quirks of Itanium's EPIC design.
"SGI servers are only used for HPC clustered workloads, and never for SMP enterprise workloads:
http://www.realworldtech.com/sgi-interview/6/ "
Readers should note that this link is a decade old and obviously SGI technology has changed over the past decade.
"Thus, this Intel Xeon E7 cpu are only used up to 8-sockets servers. For more oomph, you need 32 socket or even 64 sockets - Unix or Mainframes."
Modern x86 and Itanium chips form Intel only scale to 8 sockets without additional glue logic. This is similar to modern SPARC chips from Oracle which need glue logic to scale past 8 sockets. IBM is the only major vendor which does not use glue logic as the GX/GX+/GX++ use a multi-tiered ring topology (one for intra-MCM and one for inter-MCM communication).
"Another reason why this Intel Xeon E7 can not touch the high end server market (beyond scalability limitations) is that the RAS is not good enough."
Actually Stratus offers Xeon servers with processor lock step: http://www.stratus.com/Products/Platforms/ftServer...
x86 servers have enough RAS that HP is moving their NonStop mainframe line to Xeons:
http://h17007.www1.hp.com/us/en/enterprise/servers...
"Thus:
-Intel Xeon E7 does not scale above 8-sockets. Unix does. So you will never challenge the high end market where you need extreme performance. Besides, the largest Unix servers (Oracle) have 32TB RAM. Intel Xeon E7 has only 6TB RAM - which is nothing. So x86 does not scale cpu wise, nor RAM wise."
The new Xeon E7v2's can have up to 1.5 TB of memory per socket and in an 8 socket system that's 12 TB before needing glue logic. The SGI UV2000 scales to 256 sockets and 64 TB of memory. Note that SGI's UV2000's memory capacity is actually limited by the 46 bit physical address space while maintaining full coherency.
"-Intel Xeon E7 has no sufficient RAS, and the servers are unreliable, besides the x86 architecture which is inherently buggy and bad (some sysadmins would not touch a x86 server with a ten feet pole, and only use OpenVMS/Unix or Mainframe):
http://www.anandtech.com/show/3593 "
Nice. You totally missed the point of that article. It was more a commentary on yearly ISA increases in the x86 space and differences between AMD and Intel's implementations. This mainly played out with the FMA instructions between AMD and Intel (AMD supported 4 operand FMA in Bulldozer where as Intel supported 3 operand FMA in Sandybridge. AMD's Piledriver core added support for 3 operand FMA.) Additionally, ISA expansion should be relatively rare, not a yearly cadence to foster good software adoption.
ISA expansion has been a part of every platform so by your definition, everything is buggy and bad (and for reference, IBM's z/OS mainframes have even more instructions than x86 does).
"-Oracle is much much much much cheaper than IBM POWER systems. The Oracle SPARC servers pricing is X for each cpu. So if you buy the largest M6-32 server with 32TB of RAM you pay 32 times X. Whereas IBM POWER systems costs more and more the more sockets you buy. If you buy 32 sockets, you pay much much much more than for 8 sockets."
This came out of no where in the conversation. Seriously, in the above post, where did you mention pricing for POWER or SPARC systems? Your fanboyism is showing. I think you cut/paste this from the wrong script.
Brutalizer - Tuesday, February 25, 2014 - link
Regarding my link about Ted Tso, talking about filesystems. You missed my point. He says explicitly, that Linux kernel developers did not have access to large 48 core systems. 48 cores, translates to... 8-sockets. I tried to explain this in my post, but apparently failed. My point is, if prominent Linux kernel developers think 8-socket servers are "exotic hardware" - how do well do you think that linux scales on 8-sockets? No Linux developer has such a big server with 8-sockets to optimize Linux to. Let alone 16 or 32 sockets. I would be very surprised if Linux scaled well beyond 8-sockets without even optimizing for larger servers.Then you talk about how large the SGI UV2000 servers are, etc etc. And my link where SGI explains that their predecessor Altix server is only suitable for HPC workloads - is rejected by you. And the recent ScaleMP link I showed, where they say it is only used for HPC workloads - is also rejected by you I believe - on what grounds I dont know. Maybe because it is 2 years old? Or the font on the web page is different? I dont know, but you will surely find something to reject the link on.
Maybe you do accept that the SGI Altix server is a cluster fit for HPC workloads, as explained by SGI? But you do not accept that the UV2000 is a successor to Altix - but instead the UV2000 server is a full blown SMP server somehow. When the huge companies IBM and Oracle and HP are stuck at 32 sockets, suddenly, SGI has no problems scaling to 1000s of cpus for a very cheap price. You dont agree something is a bit weird in your logical reasoning?
Unix: lot of research during decades from the largest companies: IBM, Oracle and HP - are stuck at 32 sockets, after decades of research. Extremely expensive servers, one single 32 socket server at $35 million.
Linux: No problemo sailing past 32 sockets, hey, we talk about 100.000s of cores. Good work by the small SGI company (the largest UV2000 server has 262.144 cores). And also, same work by the startup ScaleMP - also selling 1000s of sockets. For a cheap price. But hey, why being modest and stop at quarter million of cores? Why not quarter million sockets? Or a couple of millions?
There is no problem here? What the three largest companies can not do, under decades, SGI and ScaleMP and other Linux startups has no problem with? Quarter of million of cores? Are you sh-tting me? Do you really believe it is a SMP server, used for SMP workloads, even though both SGI and ScaleMP says their servers are for HPC clustering workloads?
Brutalizer - Tuesday, February 25, 2014 - link
And how do you explain the heavy use of HPC libraries such as MPI in the UV2000 clusters? You will never find MPI in an enterprise business system. They are only used for scientific computataions. And SMP server does not use MPI at all, didnt you know?http://www.google.se/url?sa=t&rct=j&q=&...
Kevin G - Tuesday, February 25, 2014 - link
Very simple: MPI is a technique to ensure data locality for processing regardless it is if a cluster or a multi-socket system. It reduces the number of hops data has to traverse regardless if it is a SMP link between sockets or a network interface between independent systems. Fewer hops means greater efficiency and greater efficiency equates to greater throughput.Also if would have actually read that link you'd have realized that the UV2000 is not a cluster. It is a fully coherent system with up to 64 TB of globally addressable memory.
Kevin G - Tuesday, February 25, 2014 - link
"Regarding my link about Ted Tso, talking about filesystems. You missed my point. He says explicitly, that Linux kernel developers did not have access to large 48 core systems. "A lot of Linux developers are small businesses or individuals as is the beauty of open source software - everyone can contribute. It also means that not everyone will have equal access to resources. There are some large companies that invest heavily into Linux like IBM. They have managed to tune Linux to get to 2.7% the performance of AIX on their 32 socket, 256 core, 1024 thread p795 system in SPECjbb2005. Considering the small 2.7% difference, I'd argue that Linux scales rather well compared to AIX.
"Then you talk about how large the SGI UV2000 servers are, etc etc. And my link where SGI explains that their predecessor Altix server is only suitable for HPC workloads - is rejected by you."
Yes and rightfully so because you're a decade old link to their predecessor that has a different architecture.
"But you do not accept that the UV2000 is a successor to Altix - but instead the UV2000 server is a full blown SMP server somehow. When the huge companies IBM and Oracle and HP are stuck at 32 sockets, suddenly, SGI has no problems scaling to 1000s of cpus for a very cheap price. You dont agree something is a bit weird in your logical reasoning?"
Not at all. SGI developed the custom glue logic, NUMALink6, to share memory and pass coherency throughout 256 sockets. Oracle developed the same type of glue logic for SPARC that SGI developed for x86. Only thing noteworthy here is that SGI got this type of technology to market first in their 256 socket system before Oracle could ship it in their 96 socket systems. The source for this actually comes from a link that you kindly provided: http://www.theregister.co.uk/2013/08/28/oracle_spa...
And for the record, IBM has a similar interconnect as well for the POWER7. The thing about the IBM interconnect is that it is not cache coherent across the glue logic, though the 32 dies on one side of the glue are fully cache coherent. The main reason for loosing coherency in this topology is the physical address space of the POWER7 can exceeded at which point coherency would simply fail anyway. All the memory in these systems is addressable through the virtual memory though. Total number of dies is 16384, 131,072 cores, and 524,288 threads. Oh, and this system can run either AIX or Linux when maxed out. Source: http://www.theregister.co.uk/Print/2009/11/27/ibm_...
So really, all the big players have this technology. The differences are just how many sockets a system can have before this additional glue logic is necessary, how far coherency goes and the performance impact of the additional traffic hops the glue logic adds.
"There is no problem here? What the three largest companies can not do, under decades, SGI and ScaleMP and other Linux startups has no problem with? Quarter of million of cores? Are you sh-tting me? Do you really believe it is a SMP server, used for SMP workloads, even though both SGI and ScaleMP says their servers are for HPC clustering workloads?"
The SGI UV2000 fits all the requirements for a big SMP box: cache coherent, global address space and a single OS/hypervisor for the whole system. And as I mentioned earlier, both IBM and Oracle also have their own glue logic to scale to large number of cores.
As for the whole 'under decades' claim, scaling to large numbers of cores hasn't been possible until relatively recently. The integration of memory controllers and point-to-point coherency links has vastly simplified the topology for scaling to a large number of sockets. To scale efficiently with a legacy FSB architecture, the north bridge chip with the memory controller would need to have a FSB connection to each socket. Want 16 sockets? The system would need 16 FSB stemming off of that single chip. Oh and for 16 sockets the memory bandwidth would have to increase as well, figure one DDRx channel per FSB. That'd be 16 FSB links and 16 memory channels coming off of a single chip. That is not practical by any means. IBM in some of their PowerPC/POWER systems used a ring topology before memory controllers were integrated. Scaling there was straightforward: just had more hops on the ring but performance would suffer due to the latency penalty for making each additional hop.
As for what the future holds, both Intel and IBM have been interested in silicon photonics. By directly integrating fiber connections into chip dies, high end Xeons and POWER chips respectively will scale to even further heights than they do today. By ditching copper, longer distances between sockets can be obtained with a signal repeater, a limiting factor today.
BOMBOVA - Tuesday, February 25, 2014 - link
Yes you are insightful, . learned, and express yourself with linearity, " your a teacher " thanks, but where are you other thoughts ? Cheers from Thomas in Vancouver Canadahelixone - Tuesday, February 25, 2014 - link
The E7 v2 family of processors should give Intel a seat at the scale-up table, with architectural support for 15 cores/socket, 32 socket systems and 1.5 TB RAM per socket. IE: A single system with 480 fat cores and 48TB RAM.Sure, they aren't going to take the top of the scale-up charts with this generation, but they should have another belly-busting course of eating into the remaining Sparc, Power and (yes) Itanium niches. (It's only a matter of time until scale-up will be owned by Intel, with all other architectures being in decline.. IE: Oracle, and IBM will only be able to justify so much development into a lagging platform.)
Personally, I am curious if in 15-20 years we'll be talking about ARM64 servers taking on/out the legacy x86 scale-up servers.
Nenad - Thursday, February 27, 2014 - link
Intel based servers can scale over 8 CPUs. While you seem very biased toward "big iron", it should be noted that each vendor have some proprietary solution to connect multiple sockets. And Intel is offering non-proprietary way to connect up to 8 sockets. Above that you can use same approach as "big iron" Oracle/IBM solutions and offer proprietary interconnect of groups of 8xIntel CPU. Even IBM used to do that - I was working with Intel based servers with much more CPU sockets that maximal 4 sockets supported back then by Intel. Those servers used proprietary IBM interconnect between boxes each containing 4 sockets (I think each CPU had 4 cores then), 32GB RAM and I/O.While using two such boxes instead of one will not result in linear performance improvement (box interconnect is slower than link between inner 8 sockets), such servers use OS that support NUMA architecture (Non uniform memory access) to reduce between-box communications. In addition, many enterprize applications are optimized for such NUMA scenarios and scale almost linearly. We used Windows as OS (support NUMA) and MS SQL as enterprise app (support NUMA), and scalability was excellent even above native Intel 4/8 sockets.
And nowdays such Intel based servers are even better, with 8 CPUs (=120 cores) and 6TB RAM PER BOX, multiply with number of boxes you use.
End result: even without linear scaling , multi-box Intel servers can outperform IBM/Oracle servers while costing less. Your "only UNIX can scale up" comment is clearly wrong - what really keep UNIX/IBM/Oracle in enterprise is not scale-up ability, it is software that was historically made for those OS. Not to mention that enterprises are VERY conservative ("can you show us 10 companies bigger than us, in our region, that use that Windows/Intel for main servers? No? Then we will stay at UNIX or IBM - noone was ever fired for choosing iBM after all ;p" - but even that is slowly changing , probably because they can see those "10 companies")
Pox - Wednesday, March 12, 2014 - link
On the plus side, for Linux development, older 32 and 64 socket mainframes can now be had fairly cheap relative to their "new" pricing. This will aid the ongoing scaling development of Linux. You can grab a Superdome for under 10k, but you will still have to fill the server and additional cabinets with cells, processors and memory. But all in all, they are getting much easier to afford in the broker market.Phil_Oracle - Monday, February 24, 2014 - link
Need to ask yourself: Why is it that IBM hasn’t published any benchmarks in 3+ years except for certain corner cases? When IBM released Power7, they released benchmarks across every benchmark out there from TPC-C, TPC-H, SPECjbb2005, SPEC_OMP, SPEC CPU2006, SAP, etc. When Power7+ came out, there were only non I/O based benchmarks released. No DB benchmarks, no STREAM benchmark,etc. So maybe Oracle had no choice but to compare against 3-year old results? And why hasn’t IBM published newer results? Maybe because Power7+ is less than a 10% improvement? That’s what IBM's own rPerf metric tells us.