NVIDIA Tegra K1 Preview & Architecture Analysis
by Brian Klug & Anand Lal Shimpi on January 6, 2014 6:31 AM ESTThe GPU
Despite the Denver surprise, the big story behind Tegra K1 is its GPU. Prior to K1, all previous Tegra designs implemented some derivative of what became known as the GeForce ULP core. This was a non-unified architecture that, at times, looked a lot like NV40. The design was never all that impressive from a performance or power efficiency standpoint. It was cost effective and often constrained by a narrow memory interface.
Going into Project Logan, which became Tegra K1, NVIDIA made the decision (around 3 years ago) to abandon the GeForce ULP roadmap and instead combine mobile and PC GPU roadmaps. Tegra K1 would be the first design to leverage a PC GPU, in this case Kepler. The bigger implication is that all future Tegra SoCs will integrate PC GPUs. The even crazier part of all of this is that all future NVIDIA GPUs will start out as mobile first designs (including Maxwell). Productization and market availability may happen in a different order, but all architectures will start as mobile designs and then be adopted to fit other, higher power segments. This is very much like Intel’s mobile-first realization of the mid-2000s with regards to notebook processors, but with NVIDIA and smartphone/tablet GPUs.
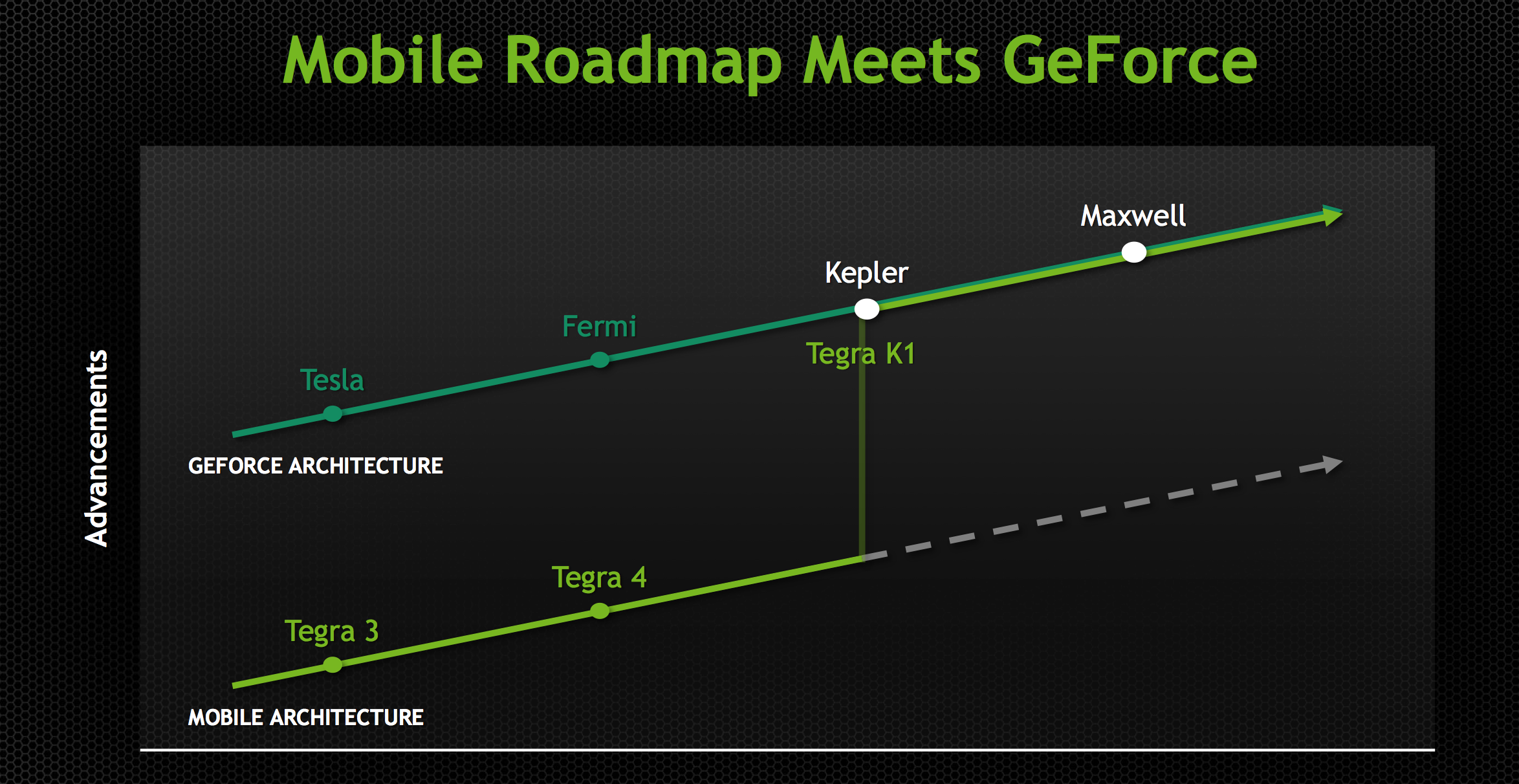
Kepler makes the move into mobile largely unchanged. This is a full Kepler implementation with the same size register file, shared L1 and is 100% ISA compatible with its big brother. It turns out that Kepler, as it was originally designed, was pretty good for mobile. If you take a GeForce 740M (2 SMX/384 CUDA core design), you’re looking at roughly a 19W GPU. Of that 19W, around 3W is memory IO, PCIe and other non-GPU things. You can subtract another 6W for leakage, bringing you down to 10W. Now that’s a 2 SMX design, so divide it in half and now you’re down to 5W. Drop the clock from 1GHz down to 900MHz, and the voltage as well, and now we’re talking around 2 - 3W for the GPU core and that’s without any re-architecting. Granted you can’t just subtract out things like leakage like that, but you get the point. Kepler wasn’t a bad starting point for a good mobile GPU design.

Tegra K1 features a single SMX (in a single GPC), which amounts to 192 CUDA cores. NVIDIA made the rookie mistake of calling Tegra K1 a 192-core processor, which made for some great headlines but largely does the industry a disservice.
Tessellation and geometry engines aren’t crippled compared to desktop Kepler. FP64 support is also present, at 1/24 the FP32 rate. There are 4 ROPs and 8 texture units, down from 16 in the PC version of Kepler. The big changes however are in the interconnects between all of the parts of the GPU.
The bigger implementations of Kepler have to be able to efficiently move data between multiple SMXes, ROPs and memory controllers. The interconnect fabric needed to do that doesn’t scale down well for mobile, where in many cases we’re dealing with one or two of those things instead of a dozen. By removing the complexity that exists in the bigger Kepler’s fabric you limit the ability for mobile Kepler to scale, but then again mobile Kepler is never going to scale to the sizes of big desktop GPUs so it’s not an issue. There are other changes outside of interconnect, with improved clock gating among other focuses on power efficiency.

NVIDIA updated the texture units to support ASTC, something that isn’t present in the desktop Kepler variants at this point. NVIDIA also hopes to use the GPU’s color compression features to reduce memory bandwidth requirements in UI rendering and not just 3D games.

With the changes NVIDIA made to the design, Kepler ends up being a < 2W GPU perfect for mobile. NVIDIA provided us with some data showing SoC + DRAM power while running GFXBench 3.0 (Manhattan), an OpenGL ES 3.0 test:
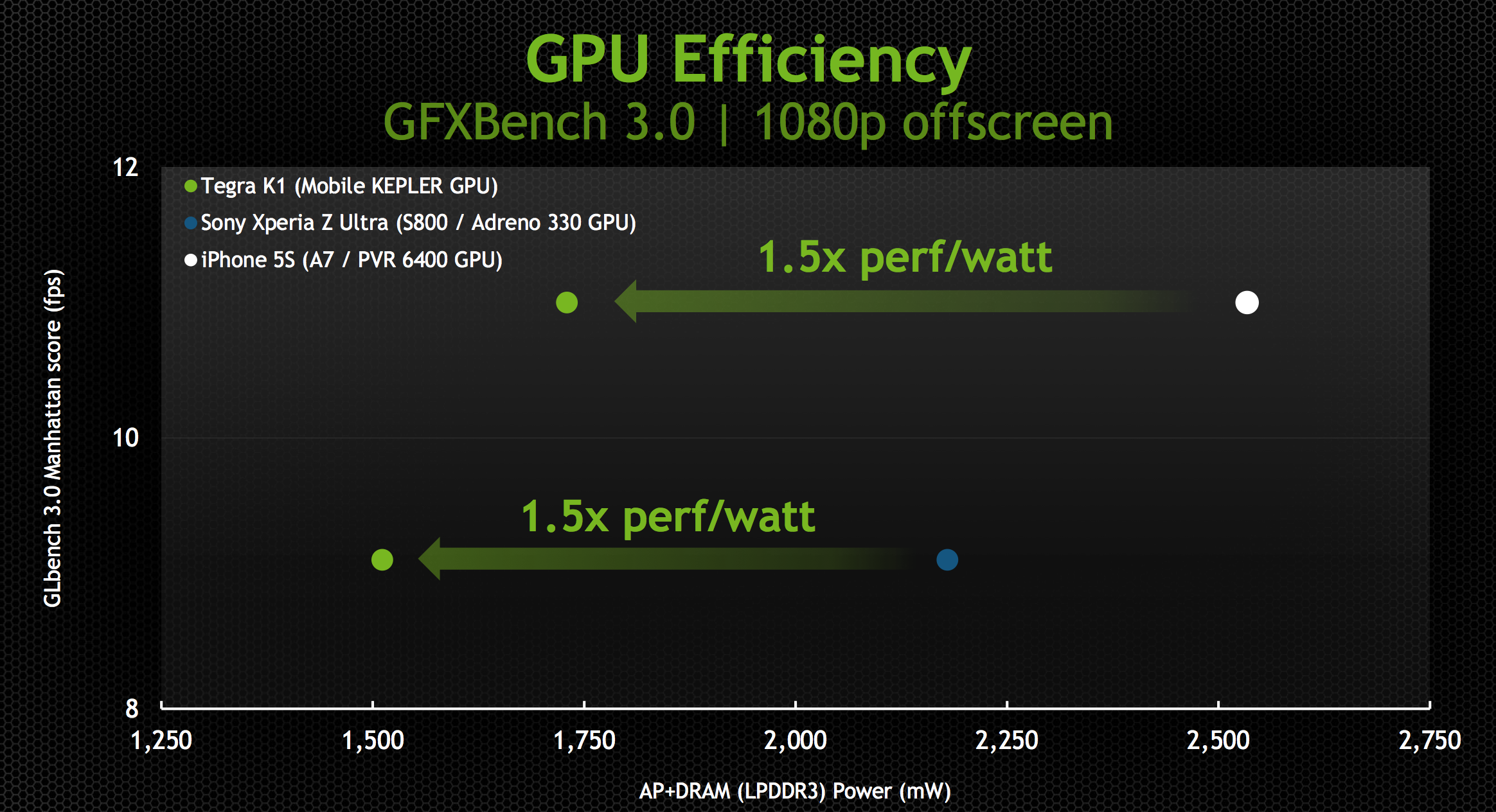
The data is presented in NVIDIA’s usual way where we’re not looking at peak performance but rather how Tegra K1 behaves when normalized to the performance of Apple’s A7 or Qualcomm’s Snapdragon 800. In both cases NVIDIA is claiming the ability to deliver equal performance at substantially better power efficiency.
NVIDIA shared some live demos that echoed the data above. Peak performance was capped to that of the A7 or Snapdragon 800, but SoC level power was always lower. It remains to be seen what power consumption looks like in a shipping configuration (which is almost always optimized for peak performance not equal performance at lower power), but it’s safe to say that concerns about Kepler being too power hungry for mobile are overrated.
The most compelling argument in favor of putting Kepler in a mobile SoC actually has to do with its API support. In one swift move NVIDIA goes from being disappointing in API support to industry leading. Since this is a full Kepler implementation (just a lower power/performing version) Tegra K1 maintains full API compatibility with NVIDIA’s flagship GeForce products. OpenGL ES 3.0 is supported but so are full OpenGL 4.4, DX11 and CUDA 6.0.

NVIDIA made it a point to say that high-end games developed for the PC or even current generation consoles could be ported over to Tegra K1 without issue. It’s perhaps over reaching a bit to claim the latter given the delta in performance (which NVIDIA hopes to make up in 4 generations!), but you can definitely argue that titles built for the previous generation of consoles (Xbox 360/PS3) could easily be ported to Tegra K1.
At its CES press conference NVIDIA teased the idea that Tegra K1 is actually more powerful than the last generation of consoles. The slide below attempts to drive that point home:
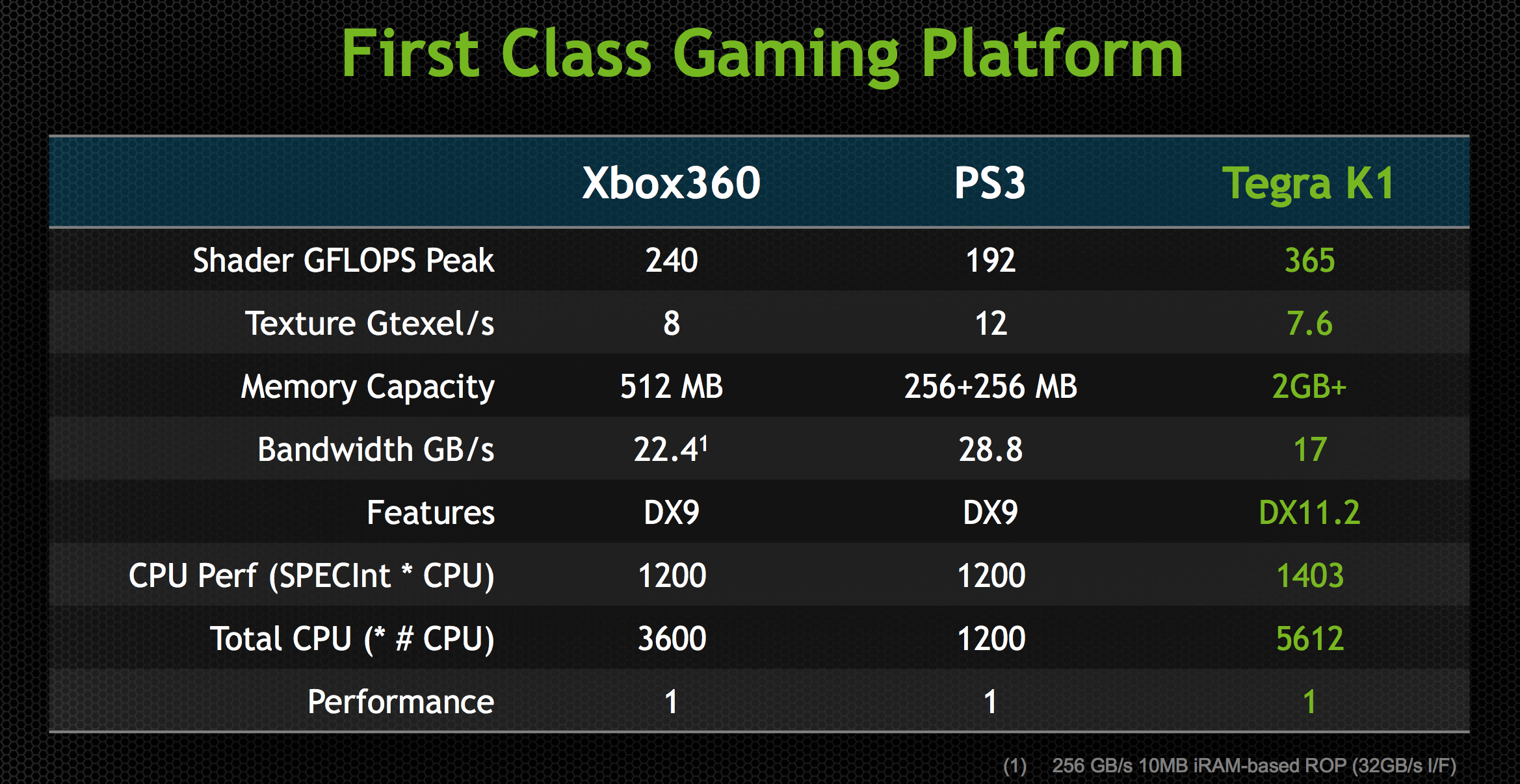
With a GPU clock of 950MHz (admittedly, a bit on the high end), NVIDIA can deliver substantially more raw horsepower than either previous generation console (192 CUDA cores * 2 FLOPS per core * 950MHz). Peak texture filtering performance and more importantly, memory bandwidth are lower than what was possible on these consoles but the numbers we’re talking about here aren’t substantial enough to prevent porting from happening. There may be some optimization needed but it definitely looks like Tegra K1 is the first mobile platform that can more or less run Xbox 360/PS3 titles, at least from a performance standpoint.
In pursuit of making porting and game development as simple as possible, NVIDIA demonstrated its NSight Tegra plugins for Visual Studio. Without changing the IDE that developers are used to, NSight Tegra allows developers to use the NDK toolchain all within Visual Studio. I’m not enough of a developer to know whether or not NVIDIA’s efforts in this space truly make life easy enough to port Xbox 360/PS3 games over to Android, but its VS integration demos looked convincing at least.
NVIDIA had a port of Serious Sam 3 running on Tegra K1 demo hardware just fine. Any games that are prepped for Steam OS are very easy to port over to Android. Once you make the move to OpenGL, the rest is allegedly fairly simple. The Serious Sam 3 port apparently took a matter of a couple of weeks to get ported over, with the bulk of the effort going into mapping controls to an Android environment.








88 Comments
View All Comments
name99 - Monday, January 6, 2014 - link
This is not especially new (though it might have been in Transmeta's time).Given the existence of robust and generally accurate branch prediction, a number of architectures have been proposed that are based on checkpoints and rollbacks rather than a ROB. There are a number of ways you can slice this, with the newest, richest, ideas having names like CFP (Continuous Flow Processing) and DOE (Distributed OutOfOrder Execution), both created by folks with Intel affiliations.
What these architectures do is help you with long memory latency delays because (in spite of what the above author said) OoO doesn't help much there. OoO covers L1 delays, most L2 delays, some L3 delays if you're lucky, and very little of the main memory delay. That's why prefetching is still an active area of research (e.g. there were some minor but cute improvements to prefetch in Ivy Bridge). The problem is the length of the ROB limits how far you can cover latency in a ROB architecture, and you can't make the ROB much larger because that increases the size (and slows down) the register file. Checkpoint architectures are not constrained in this way.
HOWEVER all this is neither here nor there.
There are three interesting claims being made about Denver
- it uses a checkpoint architecture. Interesting if true, because this type of architecture has the potential to be the general replacement for ROB OoO; even if the first implementation is only equivalent of ROB OoO, there are many new optimizations it opens up
- it uses some sort of "Code Morphing". Who knows WTF this means. Could be anything from rewriting ARM assembly to an internal ISA (like Apple have done many times, from 68K->PPC to Rosetta; likewise DEC did this to run x86 binaries on Alpha) to PPro style µOps to something very minor like the way POWER "cracks" a few instructions to simpler instructions.
- it is "7-wide". If this is an issue width, it's a bullshit measure that no-one who knows anything cares about. If this is a Decode/Rename/Dispatch width, it is a major leap forward, and the only likely way it is doable at such low power is through use of a trace cache which records dependency and remap information. If nVidia has this, it would be very cool.
Given that this is nVidia, my betting would be that every one of these is underwhelming. The exciting checkpoint architecture is in fact a standard ROB (with standard ROB limitations). The code morphing is minor cracking of a few "hard" instructions. The 7-wide refers to issue width so, ho-hum.
Loki726 - Tuesday, January 7, 2014 - link
"This is not especially new."Agreed. I mainly posted it for reference in case someone had not seen it before.
Da W - Monday, January 6, 2014 - link
For that matter i would prefer a Kabini surface mini and for AMD to follow Nvidia in game streaming (from PC or from Xbox one).chizow - Monday, January 6, 2014 - link
Great write-up guys, you're right, this is the most exciting announcement I've seen in the CPU/GPU/SoC space in a very long time, similar to A7 Cyclone but 2x that due to both CPU and GPU bombshells. It's probably the first analysis I've read in full because everything was just that interesting relative to what the rest of the industry is doing.One burning question that I did not see touched upon at all, here or elsewhere:
****What does Tegra K1 do for Nvidia's Kepler IP tech licensing prospects?
It seems to me, even if Tegra itself is not a smash hit for Nvidia in terms of design wins, the GPU technology is so disruptive that even if it gets into a few major designs (Surface 3, Nexus 7 2014, Asus Transformer for example) it may very well *FORCE* the other major industry players (Intel, Samsung, Apple) that don't have their own in-house graphics IP to license Kepler to remain competitive?
What do you all think? Any buzz on that front at CES?
OreoCookie - Friday, January 10, 2014 - link
As far as I can tell, nVidia only compared the GPU performance of the A7 to Tegra K1 but not the CPU performance. I'd be very curious to see how the Denver cores compare to Apple's Cyclone cores, though.Also, given Tegra's release date, it'll compete with Apple's A8.
Krysto - Saturday, January 11, 2014 - link
Based on the (limited) technical description and how massive those cores are, along with clock speeds that are almost twice as high as what Apple typically uses, I'd say they will beat Apple's A8 (probably just an upgraded Cyclone) pretty easily - unless Nvidia did something stupid with that software translation that adds too much overhead and and cuts the performance too much.But since we don't know exactly what's going on inside of those CPU cores, we'll have to wait for more details or a direct comparison (and hopefully Denver actually arrives this fall, and not next year).
OreoCookie - Sunday, January 12, 2014 - link
Initially, I thought so, too, but knowing it's a Transmeta Crusoe-like design, I'd be much more cautious about performance. At the same clockspeed, the Crusoe was about half or a third as fast as a Pentium III. The advantage was that the cpus consumed much less power.Of course that tells us nothing of a comparison between the A7 or A8 and a Denver-based K1 other than that the architectures are not directly comparable.
name99 - Monday, January 6, 2014 - link
"We’ve seen code morphing + binary translation done in the past, including famously in Transmeta’s offerings in the early 2000s, but it’s never been done all that well at the consumer client level.
"
Actually we've seen a few different versions of it which have worked just fine.
One obvious example (not consumer, but transparent) was IBM's switch over from custom cores to POWER cores for i-Series.
More on the consumer end, Apple have been doing this for years if you use OpenCL on their products --- they convert, on the fly, a byte code version of the GPU instructions to the target GPU. And of course anything that uses a JIT, whether it's targeting Java or JS (or Dalvik for that matter) is doing a similar sort of thing.
There may be uniquely painful aspects to doing this for x86/Windows, especially 15 years ago, but I don't think Transmeta's failure tells us anything --- this mainstream-ish tech. Especially now, in a world with hypervisors, where you have a more well-defined "space" for control code to run and bring up the OS step by step.
ruthan - Tuesday, January 7, 2014 - link
Ok, they maybe have enough GPU performance in this chip on paper. But how is final TDP SOC power consumation for 64 bit piece?But if you want to have realy PS3 or Xbox performance, which was advertised / promised till original Ipad and we still arent here at all.
Other problem are game engines middleware performance, because 80% of mobile games using Unity3D engine, which in by my experience, much more HW resources greedy and inefficient (C# - has automatic garbage collection, all in Unity running in single thread, GUI performance is terrible, PhysX implementation is signle thread) that, that console developement kits.
Back into problem, GPU is maybe ok, but for final overall performance you need also CPU with desktop like performance and to freed GPU with data and im dont think so that these weak ARM is nearly here.
So in overall i dont agree with these big perfromance and desktop like performance promises at all, would be ok, but it is only empty words.
kwrzesien - Tuesday, January 7, 2014 - link
I think nVidia has finally done it with a great SoC/GPU! I hope they get a few very solid design wins, it could change alot.Looking at those beautiful chip diagrams I think they have the CPU/CPU balance just right.