The Mac Pro Review (Late 2013)
by Anand Lal Shimpi on December 31, 2013 3:18 PM ESTMac Pro vs. Consumer Macs
For my final set of CPU performance charts I put the new Mac Pro through the same set of tests I do all new Macs. There are definitely multithreaded components to these tests (some are indeed highly threaded), but the suite also values good single threaded performance. Here we'll get an idea of how the new Mac Pro, in its most expensive configuration, fares as a normal Mac.
I've already gone through Cinebench 11.5 results, but the following graphs should put in perspective the Mac Pro's performance relative to all consumer Macs:
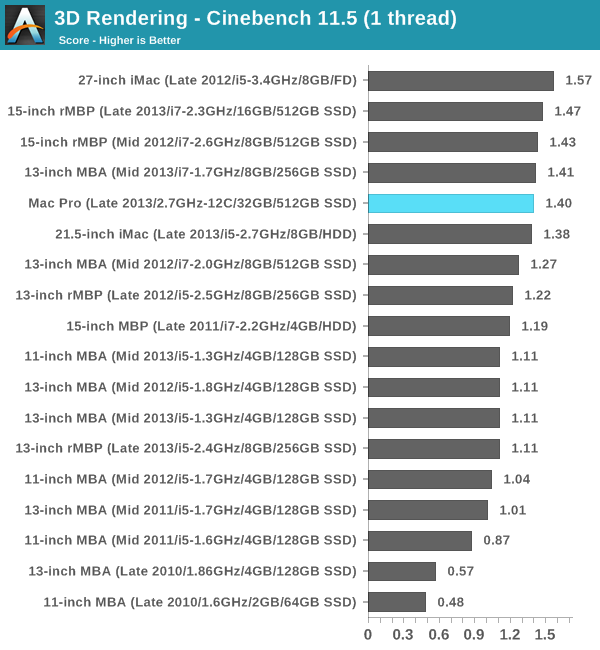
If there's one graph that tells the story of why Intel's workstation roadmap is ridiculous, it's this one. The Mac Pro follows Intel's workstation roadmap, which ends up being cut down versions of Intel's server silicon, which happens to be a generation behind what you can get on the desktop. So while the latest iMac and MacBook Pro ship with Intel's latest Haswell cores, the Mac Pro uses what those machines had a year ago: Ivy Bridge. Granted everything else around the CPU cores is beefed up (there's more cache, many more PCIe lanes, etc...), but single threaded performance does suffer as a result.
Now part of this is exaggerated by the fact that I'm reviewing the 2.7GHz 12-core Mac Pro configuration. Single core turbo tops out at 3.5GHz vs. 3.9GHz for the rest of the parts. I suspect if you had one of the 8-core models you'd see peak single threaded performance similar to what the 2012 27-inch iMac delivers. The 2013 27-inch iMac with its fastest CPU should still be quicker though. We're not talking about huge margins of victory here, a matter of a handful of percent, but as a much more expensive machine it's frustrating to not see huge performance leadership in all areas.
The Mac Pro is designed to offer competitive single threaded performance, but really deliver for everyone who depends on great multithreaded performance:
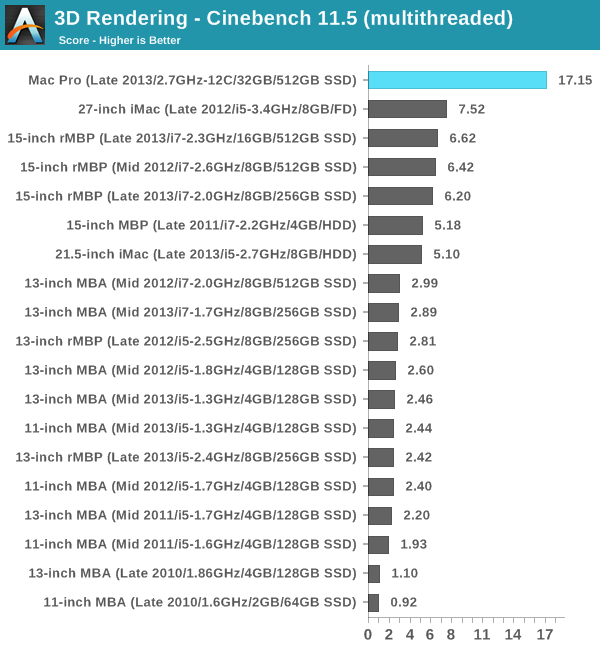
If you need more cores, the Mac Pro is literally the only solution Apple offers that can deliver. We're talking about multiple times the performance offered by anything else in Apple's lineup with a Pro suffix.
I'm slowly but surely amassing Cinebench 15 results. The story doesn't really change here, I just thought I'd publish the numbers in case anyone wants data using this new test:
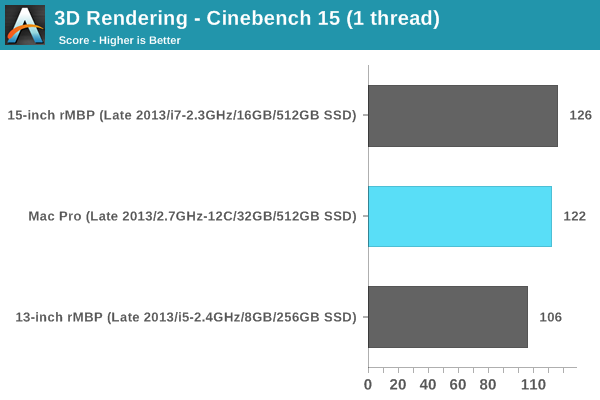
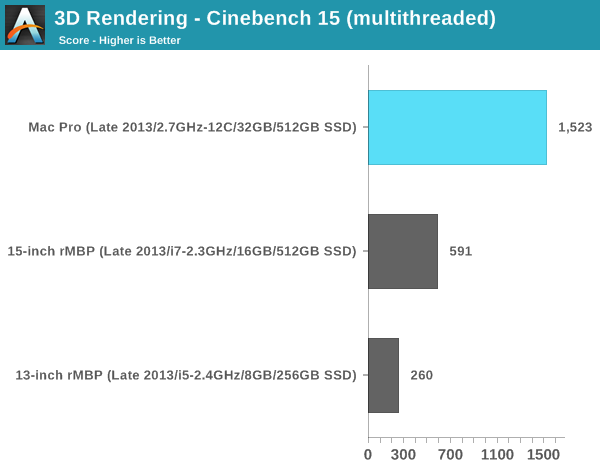
The latest versions of iPhoto and iMovie break comparisons to my older benchmarks so I've had to drop them here. I still have our Photoshop CS5 and Lightroom 3 tests though:
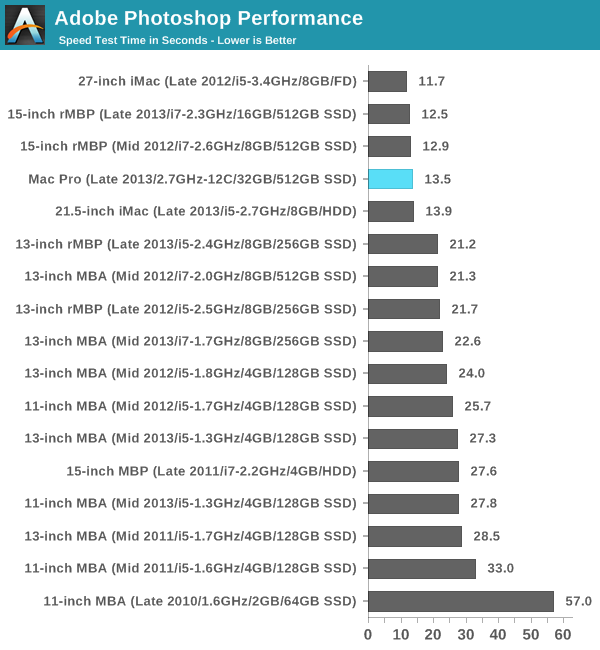
As I mentioned earlier, threading seems to have improved on newer versions of Photoshop. In CS5 our benchmark looks more like a lightly threaded test by comparison. Out of curiosity I ran the test under Photoshop CS6 and came away with a completion time of around 6 seconds.
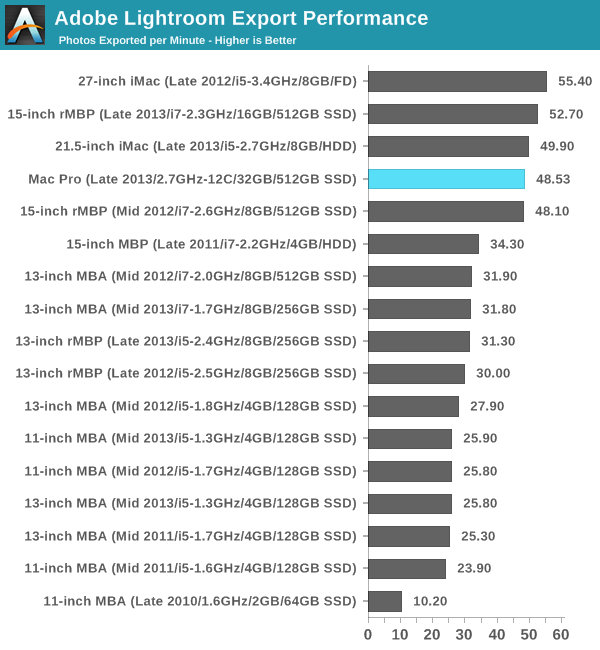
Our Lightroom 3 export test tells a very similar story. Anyone with lighter workloads looking for a huge performance increase thanks to the Mac Pro will have to look elsewhere. The Mac Pro is at least performance competitive, but in these lightly threaded workloads you won't see a huge uplift.








267 Comments
View All Comments
uhuznaa - Wednesday, January 1, 2014 - link
For whatever it's worth: I'm supporting a video pro and what I can see in that crowd is that NOBODY cares for internal storage. Really. Internal storage is used for the software and of course the OS and scratch files and nothing else. They all use piles of external drives which are much closer to actual "media" you can carry around and work with in projects with others and archive.I fact I tried for a while to convince him of the advantages of big internal HDDs and he wouldn't have any of it. He found the flood of cheap USB drives you can even pick up at the gas station in the middle of the night the best thing to happen and USB3 a gift from heaven. They're all wired this way. Compact external disks that you can slap paper labels on with the name of the project on it and the version of that particular edit and that you can carry around are the best thing since sliced bread for them. And after a short while I had to agree that they're perfectly right with that for what they do.
Apple is doing this quite right. Lots of bays are good for servers, but this is not a server. It's a workstation and work here means mostly work with lots of data that wants to be kept in nice little packages you can plug in and safely out and take with you or archive in well-labeled shelves somewhere until you find a use for it later on.
(And on a mostly unrelated note: Premiere Pro may be the "industry standard" but god does this piece of software suck gas giants through nanotubes. It's a nightmarish UI thinly covering a bunch of code held together by chewing gum and duct tape. Apple may have the chance of a snowflake in hell against that with FCP but they absolutely deserve kudos for trying. I don't know if I love Final Cut, but I know I totally hate Premiere.)
lwatcdr - Wednesday, January 1, 2014 - link
"My one hope is that Apple won’t treat the new Mac Pro the same way it did its predecessor. The previous family of systems was updated on a very irregular (for Apple) cadence. "This is the real problem. Haswell-EP will ship this year and it used a new socket. The proprietary GPU physical interface will mean those will probably not get updates quickly and they will be expensive. Today the Pro is a very good system but next year it will be falling behind.
boli - Wednesday, January 1, 2014 - link
Hi Anand, cheers for the enjoyable and informative review.Regarding your HiDPI issue, I'm wondering if this might be an MST issue? Did you try in SST mode too?
Just wondering because I was able to add 1920x1080 HiDPI to my 2560x1440 display no problem, by adding a 3840x2160 custom resolution to Switch Res X, which automatically added 1920x1080 HiDPI to the available resolutions (in Switch Res X).
mauler1973 - Wednesday, January 1, 2014 - link
Great review! Now I am wondering if I can replicate this kind of performance in a hackintosh.Technology Never Sleeps - Wednesday, January 1, 2014 - link
Good article but I would suggest that your editor or proof reader review your article before its posted. It takes away from the professional nature of the article and website with so many grammatical errors.Barklikeadog - Wednesday, January 1, 2014 - link
Once again, a standard 2009 model wouldn't fair nearly as well here. Even with a Radeon HD 4870 I bet we'd be seeing significantly lower performance.Great review Anand, but I think you meant fare in that sentence.
name99 - Wednesday, January 1, 2014 - link
" Instead what you see at the core level is a handful of conservatively selected improvements. Intel requires that any new microarchitectural feature introduced has to increase performance by 2% for every 1% increase in power consumption."What you say is true, but not the whole story. It implies that these sorts of small improvements are the only possibility for the future and that's not quite correct.
In particular branch prediction has become good enough that radically different architectures (like CFP --- Continuous Flow Processing --- become possible). The standard current OoO architecture used by everyone (including IBM for both POWER and z, and the ARM world) grew from a model based on no speculation to some, but imperfect, speculation. So what it does is collect speculated results (via the ROB and RAT) and dribble those out in small doses as it becomes clear that the speculation was valid. This model never goes drastically off the rails, but is very much limited in how many OoO instructions it can process, both at the complete end (size of the ROB, now approaching 200 fused µ-instructions in Haswell) and at the scheduler end (trying to find instructions that can be processed because their inputs are valid, now approaching I think about 60 instructions in Haswell).
These figures give us a system that can handle most latencies (FP instructions, divisions, reasonably long chains of dependent instructions, L1 latency, L2 latency, maybe even on a good day L3 latency) but NOT memory latency.
And so we have reached a point where the primary thing slowing us down is data memory latency. This has been a problem for 20+ years, but now it's really the only problem. If you use best of class engineering for your other bits, really the only thing that slows you down is waiting on (data) memory. (Even waiting on instructions should not ever be a problem. It probably still is, but work done in 2012 showed that the main reason instruction prefetching failed was that the prefetched was polluted by mispredicted branches and interrupts. It's fairly easy to filter both of these once you appreciate the issue, at which point your I prefetcher is basically about 99.5% accurate across a wide variety of code. This seems like such an obvious an easy win that I expect it to move into all the main CPUs within 5 yrs or so.)
OK, so waiting on memory is a problem. How do we fix it?
The most conservative answer (i.e. requires the fewest major changes) is data pre fetchers, and we've had these growing in sophistication over time. They can now detect array accesses with strides across multiple cache lines, including backwaters, and we have many (at least 16 on Intel) running at the same time. Each year they become smarter about starting earlier, ending earlier, not polluting the cache with unneeded data. But they only speed up regular array accesses.
Next we have a variety of experimental prefetchers that look for correlations in the OFFSETs of memory accesses; the idea being that you have things like structs or B-tree nodes that are scattered all over memory (linked by linked lists or trees or god knows what), but there is a common pattern of access once you know the base address of the struct. Some of these seem to work OK, with realistic area and power requirements. If a vendor wanted to continue down the conservative path, this is where they would go.
Next we have a different idea, runahead execution. Here the idea is that when the “real” execution hits a miss to main memory, we switch to a new execution mode where no results will be stored permanently (in memory or in registers); we just run ahead in a kind of fake world, ignoring instructions that depend on the load that has missed. The idea is that, during this period we’ll trigger new loads to main memory (and I-cache misses). When the original miss to memory returns its result, we flush everything and restart at the original load, but now, hopefully, the runahead code started some useful memory accesses so that data is available to us earlier.
There are many ways to slice this. You can implement it fairly easily using SMT infrastructure if you don’t have a second thread running on the core. You can do crazy things that try to actually preserve some of the results you generate during the runahead phase. Doing this naively you burn a lot of power, but there are some fairly trivial things you can do to substantially reduce the power.
In the academic world, the claim is that for a Nehalem type of CPU this gives you about a 20% boost at the cost of about 5% increased power.
In the real world it was implemented (but in a lousy cheap-ass fashion) on the POWER6 where it was underwhelming (it gave you maybe a 2% boost over the existing prefetchers); but their implementation sucked because it only ran 64 instructions during the run ahead periods. The simulations show that you generate about one useful miss to main memory per 300 instructions executed, so maybe two or three during a 400 to 500 cycles load miss to main memory, but 64 is just too short.
It was also supposed to be implemented in the SUN Rock processor which was cancelled when Oracle bought Sun. Rock tried to be way more ambitious in their version of this scheme AND suffered from a crazy instruction fetch system that had a single fetch unit trying to feed eight threads via round robin (so each thread gets new instructions every eight cycles).
Both these failures don’t, I think, tell us if this would work well if implemented on, say, an ARM core rather than adding SMT.
Which gets us to SMT. Seems like a good idea, but in practice it’s been very disappointing, apparently because now you have multiple threads fighting over the same cache. Intel, after trying really hard, can’t get it to give more than about a 25% boost. IBM added 4 SMT threads to POWER7, but while they put a brave face on it, the best the 4 threads give you is about 2x single threaded performance. Which, hey, is better than 1x single threaded performance, but it’s not much better than what they get from their 2 threaded performance (which can do a lot better than Intel given truly massive L3 caches to share between threads).
But everything so far is just add-ons. CFP looks at the problem completely differently.
The problem we have is that the ROB is small, so on a load miss it soon fills up completely. You’d want the ROB to be about 2000 entries in size and that’s completely impractical. So why do we need the ROB? To ensure that we write out updated state properly (in small dribs and drabs every cycle) as we learn that our branch prediction was successful.
But branch prediction these days is crazy accurate, so how about a different idea. Rather than small scale updating successful state every cycle, we do a large scale checkpoint every so often, generally just before a branch that’s difficult to predict. In between these difficult branches, we run out of order with no concern for how we writeback state — and in the rare occasions that we do screw up, we just roll back to the checkpoint. In between difficult branches, we just run on ahead even across misses to memory — kinda like runahead execution, but now really doing the work, and just skipping over instructions that depend on the load, which will get their chance to run (eventually) when the load completes.
Of course it’s not quite that simple. We need to have a plan for being able to unwind stores. We need a plan for precise interrupts (most obviously for VM). But the basic idea is we trade today’s horrible complexity (ROB and scheduler window) for a new ball of horrible complexity that is not any simpler BUT which handles the biggest current problem, that the system grinds to a halt at misses to memory, far better than the current scheme.
The problem, of course, is that this is a hell of a risk. It’s not just the sort of minor modification to your existing core where you know the worst that can go wrong; this is a leap into the wild blue yonder on the assumption that your simulations are accurate and that you haven’t forgotten some show-stopping issue.
I can’t see Intel or IBM being the first to try this. It’s the sort of thing that Apple MIGHT be ambitious enough to try right now, in their current state of so much money and not having been burned by a similar project earlier in their history. What I’d like to see is a university (like a Berkeley/Stanford collaboration) try to implement it and see what the real world issues are. If they can get it to work, I don’t think there’s a realistic chance of a new SPARC or MIPS coming out of it, but they will generate a lot of valuable patents, and their students who worked on the project will be snapped up pretty eagerly by Intel et al.
stingerman - Wednesday, January 1, 2014 - link
I think Intel has another two years left on the Mac. Apple will start phasing it out on the MacBook Air, Mac Mini and iMac. The MacBook rPros and finally the Mac Pro. Discreet x86 architecture is dead ending. Apple's going to move their Macs to SOC that they design. It will contain most of the necessary components and significantly reduce the costs of the desktops and notebooks. The Mac Pro will get it last giving time for the Pro Apps to be ported to Apple's new mobile and desktop 64-bit processors.tahoey - Wednesday, January 1, 2014 - link
Remarkable work as always. Thank you.DukeN - Thursday, January 2, 2014 - link
Biased much, Anand?Here's the Lenovo S30 I bought a couple of weeks back, and no it wasn't $4000 + like you seem to suggest.
http://www.cdw.com/shop/products/Lenovo-ThinkStati...
You picked probably the most overpriced SKU in the bunch just so you can prop up the ripoff that is your typical Apple product.
Shame.