The AMD Radeon R9 290X Review
by Ryan Smith on October 24, 2013 12:01 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Hawaii
- Radeon 200
XDMA: Improving Crossfire
Over the past year or so a lot of noise has been made over AMD’s Crossfire scaling capabilities, and for good reason. With the evolution of frame capture tools such as FCAT it finally became possible to easily and objectively measure frame delivery patterns. The results of course weren’t pretty for AMD, showcasing that Crossfire may have been generating plenty of frames, but in most cases it was doing a very poor job of delivering them.
AMD for their part doubled down on the situation and began rolling out improvements in a plan that would see Crossfire improved in multiple phases. Phase 1, deployed in August, saw a revised Crossfire frame pacing scheme implemented for single monitor resolutions (2560x1600 and below) which generally resolved AMD’s frame pacing in those scenarios. Phase 2, which is scheduled for next month, will address multi-monitor and high resolution scaling, which faces a different set of problems and requires a different set of fixes than what went into phase 1.
The fact that there’s even a phase 2 brings us to our next topic of discussion, which is a new hardware DMA engine in GCN 1.1 parts called XDMA. Being first utilized on Hawaii, XDMA is the final solution to AMD’s frame pacing woes, and in doing so it is redefining how Crossfire is implemented on 290X and future cards. Specifically, AMD is forgoing the Crossfire Bridge Interconnect (CFBI) entirely and moving all inter-GPU communication over the PCIe bus, with XDMA being the hardware engine that makes this both practical and efficient.

But before we get too far ahead of ourselves, it would be best to put the current Crossfire situation in context before discussing how XDMA deviates from it.
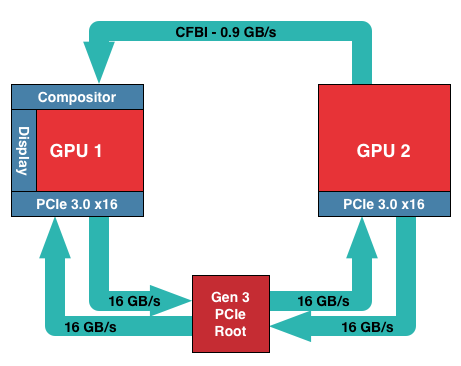
In AMD’s current CFBI implementation, which itself dates back to the X1900 generation, a CFBI link directly connects two GPUs and has 900MB/sec of bandwidth. In this setup the purpose of the CFBI link is to transfer completed frames to the master GPU for display purposes, and to so in a direct GPU-to-GPU manner to complete the job as quickly and efficiently as possible.
For single monitor configurations and today’s common resolutions the CFBI excels at its task. AMD’s software frame pacing algorithms aside, the CFBI has enough bandwidth to pass around complete 2560x1600 frames at over 60Hz, allowing the CFBI to handle the scenarios laid out in AMD’s phase 1 frame pacing fix.
The issue with the CFBI is that while it’s an efficient GPU-to-GPU link, it hasn’t been updated to keep up with the greater bandwidth demands generated by Eyefinity, and more recently 4K monitors. For a 3x1080p setup frames are now just shy of 20MB/each, and for a 4K setup frames are larger still at almost 24MB/each. With frames this large CFBI doesn’t have enough bandwidth to transfer them at high framerates – realistically you’d top out at 30Hz or so for 4K – requiring that AMD go over the PCIe bus for their existing cards.
Going over the PCIe bus is not in and of itself inherently a problem, but pre-GCN 1.1 hardware lacks any specialized hardware to help with the task. Without an efficient way to move frames, and specifically a way to DMA transfer frames directly between the cards without involving CPU time, AMD has to resort to much uglier methods of moving frames between the cards, which are in part responsible for the poor frame pacing we see today on Eyefinity/4K setups.
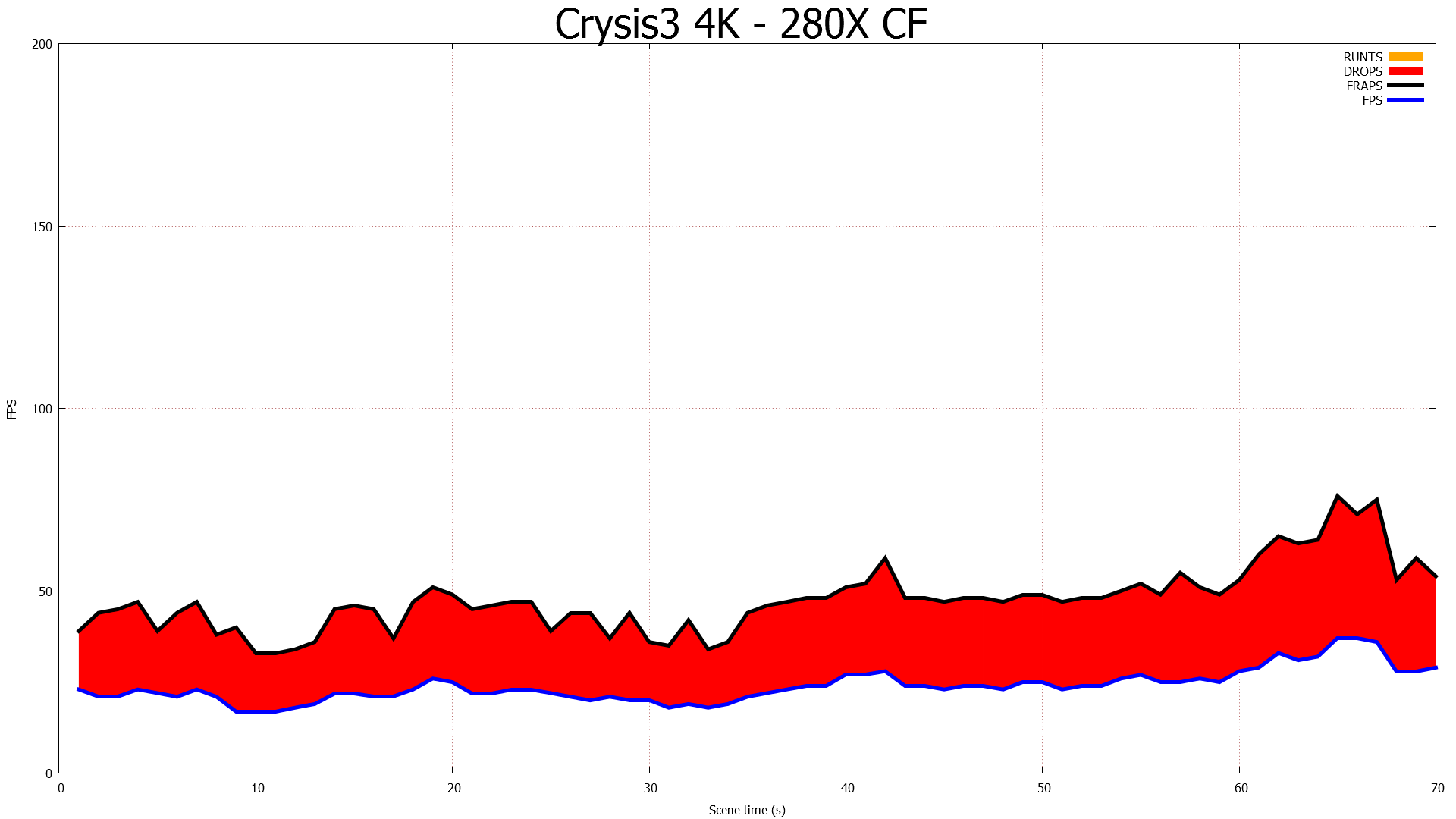
CFBI Crossfire At 4K: Still Dropping Frames
For GCN 1.1 and Hawaii in particular, AMD has chosen to solve this problem by continuing to use the PCIe bus, but by doing so with hardware dedicated to the task. Dubbed the XDMA engine, the purpose of this hardware is to allow CPU-free DMA based frame transfers between the GPUs, thereby allowing AMD to transfer frames over the PCIe bus without the ugliness and performance costs of doing so on pre-GCN 1.1 cards.
With that in mind, the specific role of the XDMA engine is relatively simple. Located within the display controller block (the final destination for all completed frames) the XDMA engine allows the display controllers within each Hawaii GPU to directly talk to each other and their associated memory ranges, bypassing the CPU and large chunks of the GPU entirely. Within that context the purpose of the XDMA engine is to be a dedicated DMA engine for the display controllers and nothing more. Frame transfers and frame presentations are still directed by the display controllers as before – which in turn are directed by the algorithms loaded up by AMD’s drivers – so the XDMA engine is not strictly speaking a standalone device, nor is it a hardware frame pacing device (which is something of a misnomer anyhow). Meanwhile this setup also allows AMD to implement their existing Crossfire frame pacing algorithms on the new hardware rather than starting from scratch, and of course to continue iterating on those algorithms as time goes on.
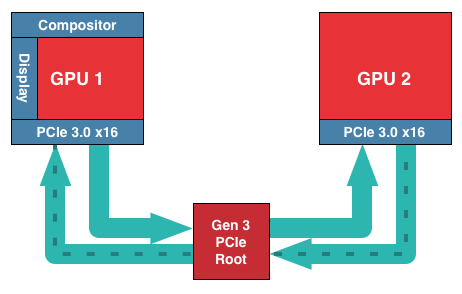
Of course by relying solely on the PCIe bus to transfer frames there are tradeoffs to be made, both for the better and for the worse. The benefits are of course the vast increase in memory bandwidth (PCIe 3.0 x16 has 16GB/sec available versus .9GB/sec for CFBI) not to mention allowing Crossfire to be implemented without those pesky Crossfire bridges. The downside to relying on the PCIe bus is that it’s not a dedicated, point-to-point connection between GPUs, and for that reason there will bandwidth contention, and the latency for using the PCIe bus will be higher than the CFBI. How much worse depends on the configuration; PCIe bridge chips for example can both improve and worsen latency depending on where in the chain the bridges and the GPUs are located, not to mention the generation and width of the PCIe link. But, as AMD tells us, any latency can be overcome by measuring it and thereby planning frame transfers around it to take the impact of latency into account.
Ultimately AMD’s goal with the XDMA engine is to make PCIe based Crossfire just as efficient, performant, and compatible as CFBI based Crossfire, and despite the initial concerns we had over the use of the PCIe bus, based on our test results AMD appears to have delivered on their promises.
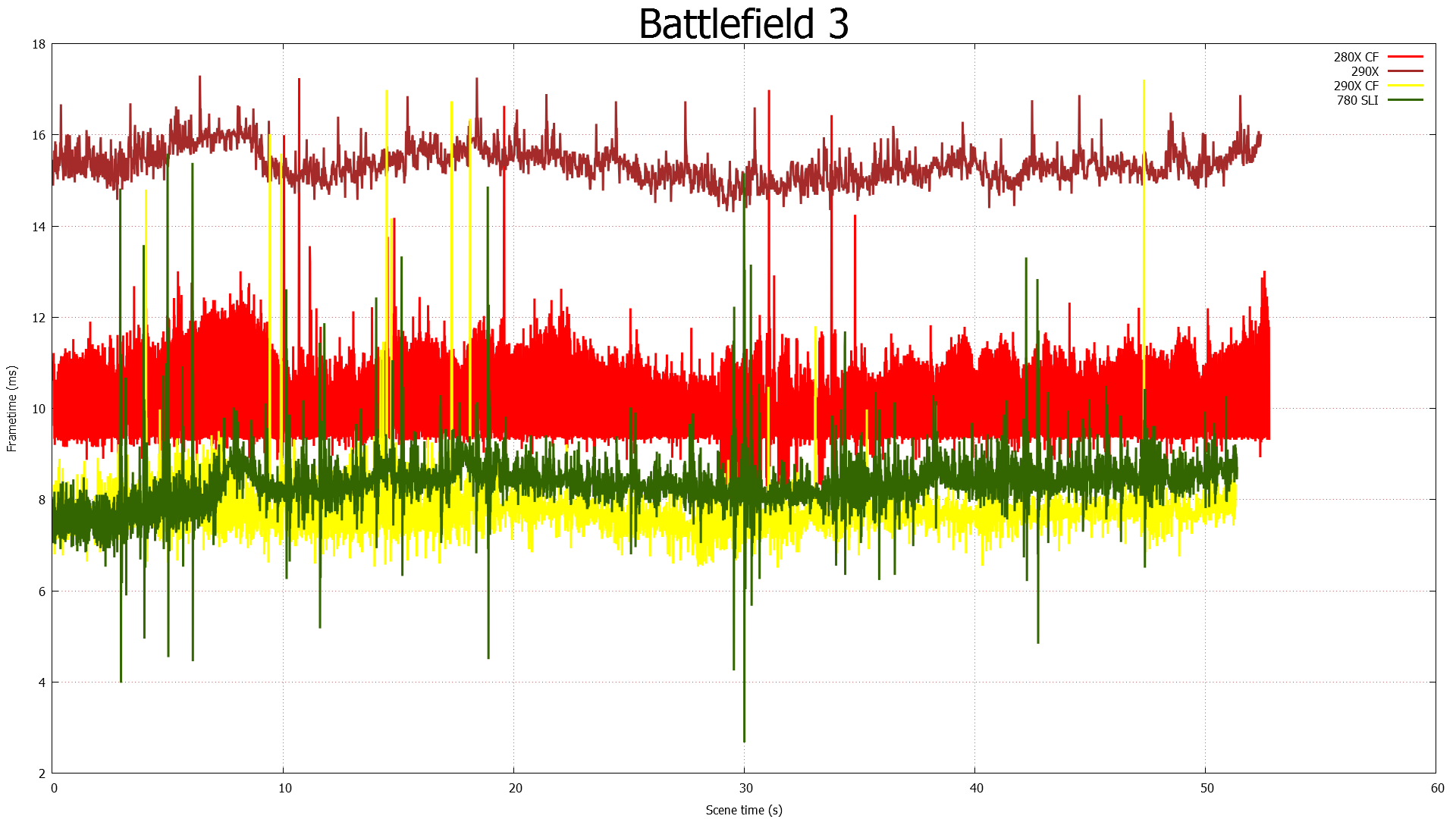

The XDMA engine alone can’t eliminate the variation in frame times, but in its first implementation it’s already as good as CFBI in single monitor setups, and being free of the Eyefinity/4K frame pacing issues that still plague CFBI, is nothing short of a massive improvement over CFBI in those scenarios. True to their promises, AMD has delivered a PCie based Crossfire implementation that incurs no performance penalty versus CFBI, and on the whole fully and sufficiently resolves AMD’s outstanding frame pacing issues. The downside of course is that XDMA won’t help the 280X or other pre-GCN 1.1 cards, but at the very least going forward AMD finally has demonstrated that they have frame pacing fully under control.
On a side note, looking at our results it’s interesting to see that despite the general reuse of frame pacing algorithms, the XDMA Crossfire implementation doesn’t exhibit any of the distinct frame time plateaus that the CFBI implementation does. The plateaus were more an interesting artifact than a problem, but it does mean that AMD’s XDMA Crossfire implementation is much more “organic” like NVIDIA’s, rather than strictly enforcing a minimum frame time as appeared to be the case with CFBI.








396 Comments
View All Comments
Pontius - Tuesday, October 29, 2013 - link
Some good points Jian, I would like to see side by side comparisons as well. However, I've seen some studies that implement the same algorithm in both OpenCL and CUDA and the results are mostly the same if properly implemented. I've been doing GPU computing development in my spare time over the last year and OpenCL does have one advantage over CUDA that is the reason I use it: run-time compilation. If at run-time you are working with various data sets that involve checking many conditionals, you can compile a kernel with the conditionals stripped out and get a good performance increase since GPUs aren't good at conditionals like CPUs are. But in the end, I agree, more apples to apples comparisons are needed.azixtgo - Thursday, October 24, 2013 - link
the titan is irrelevant. I can't figure why the hell people think a $1000 GPU is even worth mentioning. It's not for sane people to buy and definitely not a genuine effort by nvidia. They saw an opportunity and went for itBloodcalibur - Thursday, October 24, 2013 - link
It's $350 more because of it's compute performance ugh. It benchmarks 5-6x more than the 780 on DGEMM. This is why the card is priced a whopping $350 more than their own 780 which is only a few FPS lower on most games and setups. The only people that should've bought a Titan were people who both GAME and do a little bit of computing.To compare it to the 290x are what retarded ignorant people are doing. Compare it to the 780 which it does beat out. Now we have to wait for nvidia's response.
Cellar Door - Thursday, October 24, 2013 - link
Read the review before trolling. It's $549azixtgo - Thursday, October 24, 2013 - link
technically it's a good value. I think. I despise the higher prices as well but who really knows the value of the product. Comparing a GPU to a lot of things (like a ps4 that has a million other components or a complete PC ), maybe not. but comparing this to nvidia... well...Pounds - Thursday, October 24, 2013 - link
Did the nvidia fanboy get his feelings hurt?superflex - Thursday, October 24, 2013 - link
Yes, and his wallet got shredded.Validation is a bitch.
piroroadkill - Thursday, October 24, 2013 - link
Huh? You can go over to Newegg right now and buy one for $580.Wreckage - Thursday, October 24, 2013 - link
He did not say "Mantle" 7 times so he might not be from their PR department.Either way the 290 is hot, loud, power hungry and nothing new in the performance department. It's cheap but that won't last. Looks like we will have to wait form Maxwell for something truly new.
chrnochime - Thursday, October 24, 2013 - link
You OTOH look like you can't RTFA.