Samsung SSD 840 EVO Review: 120GB, 250GB, 500GB, 750GB & 1TB Models Tested
by Anand Lal Shimpi on July 25, 2013 1:53 PM EST- Posted in
- Storage
- SSDs
- Samsung
- TLC
- Samsung SSD 840
TurboWrite: MLC Performance on a TLC Drive
All NAND trends towards lower performance as we move down to smaller process geometries. Clever architectural tricks are what keep overall SSD performance increasing each generation, but if you look at Crucial's M500 you'll see that it's not always possible to do. Historically, whenever a level of the memory hierarchy got too slow, the industry would more or less agree to insert another level above it to help hide latency. The problem is exascerbated once you start talking about TLC NAND. Samsung's mitigation to the problem is to dedicate a small portion of each TLC NAND die as an SLC write buffer. The feature is called TurboWrite. Initial writes hit the TurboWrite buffer at very low latency and are quickly written back to the rest of the TLC NAND array.
Since the amount of spare area available on the EVO varies depending on capacity, TurboWrite buffer size varies with capacity. The smallest size is around 3GB while the largest is 12GB on the 1TB EVO:
| Samsung SSD 840 EVO TurboWrite Buffer Size vs. Capacity | |||||||
| 120GB | 250GB | 500GB | 750GB | 1TB | |||
| TurboWrite Buffer Size | 3GB | 3GB | 6GB | 9GB | 12GB | ||
I spent some time poking at the TurboWrite buffer and it pretty much works the way you'd expect it to. Initial writes hit the buffer first, and as long as they don't exceed the size of the buffer the performance you get is quite good. If your writes stop before exceeding the buffer size, the buffer will write itself out to the TLC NAND array. You need a little bit of idle time for this copy to happen, but it tends to go pretty quickly as it's just a sequential move of data internally (we're talking about a matter of 15 - 30 seconds). Even before the TurboWrite buffer is completely emptied, you can stream new writes into the buffer. It all works surprisingly well. For most light use cases I can see TurboWrite being a great way to deliver more of an MLC experience but on a TLC drive.
TurboWrite's impact is best felt on the lower capacity drives that don't have as many NAND die to stripe requests across (thus further hiding long program latencies). The chart below shows sequential write performance vs. time for all of the EVO capacities. The sharp drop in performance on each curve is when the TurboWrite buffer is exceeded and sequential writes start streaming to the TLC NAND array instead:
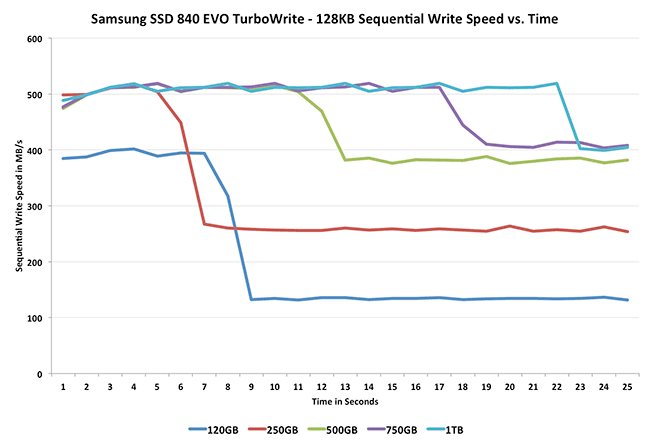
On the 120GB drive the delta between TurboWrite and standard performance is huge. On the larger drives the drop isn't as big and the TurboWrite buffer is also larger, the combination of the two is why the impact isn't felt as muchon those drives. It's this TurboWrite buffer that gives the EVO its improvement in max sequential write speed over last year's vanilla SSD 840.








137 Comments
View All Comments
ervinshiznit - Thursday, July 25, 2013 - link
Typo? On the Turbowrite page you say "For most light use cases I can see TurboWrite being a great way to deliver more of an MLC experience but on a TLC drive."It should be deliver more of a SLC experience but on a TLC drive.
ciri - Sunday, July 28, 2013 - link
SLC>MLC>TLCGuspaz - Thursday, July 25, 2013 - link
The fact that RAPID sees any performance improvement at all illustrates to me a failure of the operating system's disk caching subsystem. That's all that RAPID really is, after all, a replacement for the Windows disk cache.I'd be curious to see the performance results of RAPID compared to the disk caching subsystems on other platforms, such as Linux and ZFS (which even on Linux has it's own cache called the "ARC"). Are the large improvements because Windows disk caching is particularly bad, or because RAPID is a better implementation than anybody else?
themelon - Thursday, July 25, 2013 - link
Windows is absolutely horrible at filesystem caching and I don't think it does any sort of block caching. It seems to use more of a FIFO algorithm that has no sequential write bypass no matter what you do. ZFS and the 2 block device caches that recently integrated into the linux kernel, bcache and dm-cache, use more of an LRU method. All of them have at least basic sequential bypass detection as well. bcache in particular is tuneable to your load in almost all aspects of performance. Of course these are only block side caching and currently have no filesystem specific knowledge.There is some interesting work going on to track hot spots that will eventually allow for preemptive cache warming and/or hot relocation. Right now it is BTRFS specific but it is being integrated below the filesystem layer so any filesystem will eventually be able to take advantage of it.
ZFS on Linux is a waste of time in my opinion. ZFS's L2ARC and SLOG are great but limited by some of what I feel are architectural flaws in zfs itself. I used to love zfs but the Linux kernel block stack has caught up to it in features and still offers all of the flexibility that it always has.
aicom - Friday, July 26, 2013 - link
Windows' cache system is better than you give it credit for. It does support sequential bypass (see FILE_FLAG_SEQUENTIAL_SCAN flag). It works with filesystem drivers with the Cc* APIs in the kernel. It also supports caching files over a network, even with other clients modifying the files. It does standard read-ahead and write-behind and is supplemented by an adaptive prefetcher (SuperFetch).The reason we're seeing such huge gains is because the programs being tested explicitly ask NOT to be cached. The whole point is to test the drive, so they pass FILE_FLAG_NO_BUFFERING to disable caching on the files being accessed.
MrSpadge - Saturday, July 27, 2013 - link
Excellent post!Timur Born - Sunday, July 28, 2013 - link
Question still arises why the Anand Storage Bench is affected beneficial by RAPID?! Is it because ASB also asks the Windows cache to be bypassed, is it because of the Windows cache flushing parts of its pages every second or does RAPID communicate with the drive (firmware) at a more fundamental level that allows further optimizations?watersb - Friday, July 26, 2013 - link
Excellent points. I stick with ZFS because I trust it (after many hardware failures but no data loss) and because it is cross-platform.Mac HFS does "hot relocation", I believe. And NTFS has always tried to keep hot files in the middle of the disk in order to reduce hard disk seek times. So maybe I don't understand what is meant by hot relocation.
piroroadkill - Thursday, July 25, 2013 - link
I agree. I'm pretty sure Windows' own disk caching is terrible. It's pretty poor even on the server side. They really need to work on that shit.tincmulc - Thursday, July 25, 2013 - link
How is rapid any better from SuperCache or FancyCache? Not only do they do the same thing, but can also be configured to use more ram or use os invisble memory (32 bit os with more than 3GB of ram) and they work for any drive, even HDDs.