Khronos @ SIGGRAPH 2013: OpenGL 4.4, OpenCL 2.0, & OpenCL 1.2 SPIR Announced
by Ryan Smith on July 22, 2013 9:00 AM ESTOpenCL 2.0: What's New
Wrapping things up, Khronos’ other OpenCL announcement for this morning is the announcement of the release of the provisional specification for OpenCL 2.0. Like OpenCL SPIR 1.2 this is a work in progress specification, with Khronos continuing to take comments and leaving the door open for further adjustments, with a goal of finalizing the standard within 6 months.
As an established and maturing standard, the key enhancements and additions slated for OpenCL 2.0 are being designed in part around the technologies and hardware Khronos and its members believe will be the most important over the next few years. Which is to say that a lot of the major functionality going into OpenCL 2.0 is focused around HSA and HSA-like devices where GPU and CPU are capable of sharing memory, pointers, cache, and more. OpenCL 1.x is already capable of running on these devices, but it lacks effective means to take advantage of the interconnected hardware, which is where OpenCL 2.0’s additions come in.

The biggest addition here is that OpenCL 2.0 introduces support for shared virtual memory, the basis of exploiting GPU/CPU integrated processors. Kernels will be able to share complex data, including memory pointers, executing and using data without the need to explicitly transfer it from host to device and vice versa. Making effective use of this ability still falls to developers, who will need to figure out what work to send to the GPU and what work to send to the CPU, but as with other, similar proposals, the performance benefits can be immense in the right situations by allowing GPUs to work on parallel code without the need to constantly make expensive swaps with the CPU to move data or get the results of serial code.
Along these lines the addition of atomics from the C11 language standard should also prove beneficial to programmers looking to exploit GPU/CPU synergy, allowing work-items to be visible across work-groups and across devices. Generic address space support is also coming in OpenCL 2.0, alleviating the need in OpenCL 1.x to write a version of a function for each named address space. Instead a single generic function can handle working with all of the named address spaces, simplifying development and cutting down on the amount of code that needs to be cached for execution.
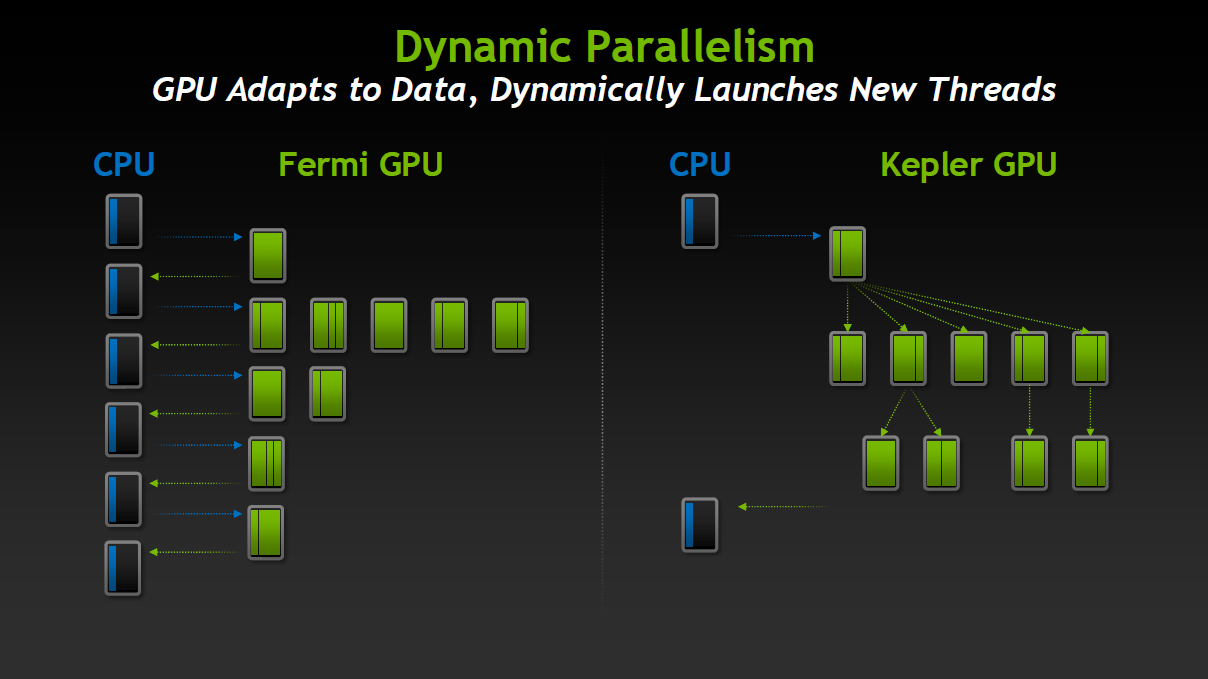
Of course while most of OpenCL 2.0’s feature additions are geared towards integrated CPU/GPU devices, there are some notable features that will be applicable to all devices. Key among these will be dynamic parallelism, which was first introduced with NVIDIA’s Tesla K20 based cards and is currently only available under CUDA. We won’t go too deep on this since we’ve covered it before, but in a nutshell dynamic parallelism allows for kernels to launch other kernels, saving both time and resources by skipping costly host interactions and thereby leaving the host CPU to work on other tasks. Dynamic parallelism is one of K20’s more potent features, so OpenCL developers should be pleased that they’re finally getting a crack at it.
Finally, on the gaming/graphics side OpenCL is getting some new image manipulation functionality that is slated to further enhance the existing OpenCL/OpenGL interoperability capabilities. OpenCL 2.0 will define the ability to work with sRGB color space images, alongside the ability for multiple kernels to read and write to the same OpenCL image. Furthermore OpenCL will now be able to generate images from multi-sampled and mi-mapped OpenGL textures, allowing OpenGL to pass work to OpenCL under more scenarios.










28 Comments
View All Comments
ltcommanderdata - Monday, July 22, 2013 - link
In DirectX 11.2 there's some thought that Tiled Resources tier 1 refers to Bindless Textures while tier 2 refers to Sparse Textures. So is there any hierarchy to these features where GPUs supporting sparse textures (GCN-based) should also support bindless textures (only Keplar officially announced)? Or are they independent?And is GK110 the only GPU currently available that supports Dynamic Parallelism and therefore the only currently shipping GPU that will be OpenCL 2.0 compatible? Hopefully Volcanic Islands and Maxwell will bring dynamic parallelism to the full product stack rather than just the top-end GPUs.
sontin - Monday, July 22, 2013 - link
GK208 (Cuda 3.5) supports Dynamic Parallelism. And with next year i guess every GPU and Tegra 5 will support at leats Cuda 3.5.TeXWiller - Monday, July 22, 2013 - link
That may be Tesla/Quadro-exlusive offering anyway. It would be nice if Nvidia would bring back the "democratization of parallelism" from the times long gone.sontin - Monday, July 22, 2013 - link
GK208 is a consumer chip. It's not limited to the Quadro or Tesla series. They even advertised cards based on the chip on their blog:http://blogs.nvidia.com/blog/2013/06/06/hey-develo...
xdrol - Monday, July 22, 2013 - link
The thing is, nVidia does not care about OpenCL, they could not even (ehm, rather, didn't want to) ship an OpenCL 1.2 driver at all.. So it's nice that the hardware supports the feature, if we cannot use it from OpenCL, that's no better than AMD's version.name99 - Tuesday, July 23, 2013 - link
You mean you won't be able to use OpenCL on Windows?I assume on OSX you'll be able to use OpenCL and it will continue to move forward --- unless nVidia thinks it would be a wise business move to ensure Apple never buys from them again.
MrSpadge - Saturday, July 27, 2013 - link
No, by "not shipping OpenCL 1.2 drivers" he means they're still at 1.1. I don't expect this to be any better on OSX.Ryan Smith - Monday, July 22, 2013 - link
To the best of knowledge this is independent. At one point last year AMD said they didn't believe they could implement bindless textures in GCN hardware in an equivalent manner to NVIDIA. And NVIDIA of course may be bindless, but they can't do sparse in hardware. I fully expect the two to come together in the next generation of hardware, with NV and AMD gaining their competitor's respective functionality.przemo_li - Thursday, July 25, 2013 - link
Nvidia support both ARB_bindless_texture and ARB_sparse_texture in their drivers:http://www.geeks3d.com/20130722/nvidia-r326-29-bet...
And "Tiers" and "feature levels" is MS speak for extensions and OpenGL versions. (Since clean DX9, DX10, DX11 do not work any more)
Both of those did NOT landed in core. Those are extensions vendors may implement in hw if they like. (Though ARB stand there for a reason, and those extensions should land in core in unchanged form if hw support will be good)
chris81 - Monday, July 22, 2013 - link
typo:Now with the competition of the new conformance tests -> completion