The ARM Diaries, Part 2: Understanding the Cortex A12
by Anand Lal Shimpi on July 17, 2013 12:30 PM EST- Posted in
- CPUs
- Arm
- SoCs
- Cortex A12
Back End Improvements
The front end of the Cortex A12 is a bit more efficient than the Cortex A9, but the bulk of the performance gains really come from improvements to the execution side of the core. Similar to the Cortex A15, ARM introduced multiple independent issue queues ahead of the functional units. It’s important to get nomenclature right here. Instructions are decoded into micro-ops, renamed instructions are dispatched into the issue queues and then micro-ops are issued from the issue queues when their operands are available. Everything up to the issue queue is handled in order, while issuing can be handled out of order in the Cortex A12 (in most cases, more on this later).
Whereas the Cortex A9 had a single issue queue ahead of all functional units, the Cortex A12 moves to three independent issue queues. The A9’s issue queue could hold 4 decoded instructions, while each issue queue in Cortex A12 is larger than that. The move to larger independent issue queues alone should help with increasing IPC.
The three issue queues are as follows: one for integer, one for FP/NEON and one for loads and stores. ARM provided bits and pieces of an architectural block diagram for the Cortex A12. I reconstructed one as best as I could below. The blue blocks indicate in-order components of the design, while the pink/salmon blocks are out-of-order. You can toggle between the A12 and A9 diagrams to see how things have changed.
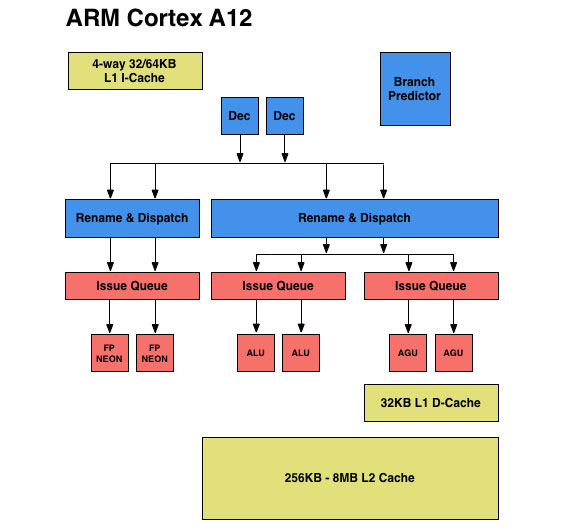
Cortex A12 retains the two integer pipelines of the Cortex A9, but adds support for integer divides (like the A7 and A15, other A-series architectures generally lacked support for hardware int divides). The rest of the integer execution capabilities are unchanged.
The FP/NEON units are vastly improved on the Cortex A12. When the Cortex A9 was first introduced, NEON code was rarely used which even lead NVIDIA to dropping NEON support altogether in Tegra 2. Times quickly changed as NEON code is widely used in Android and mobile applications.
The Cortex A12 design retains separate physical register files for integer and FP operations, but the RFs are larger than in Cortex A9.
Although Cortex A9 was considered an out-of-order microarchitecture, all FP and NEON instructions were executed in-order. With Cortex A12, ARM moves to a fully out-of-order architecture, at least as far as non-memory-ops are concerned. The FP/NEON issue queue now dual-issues into two FP/NEON pipes, both of which operate fully out-of-order. The FP/NEON pipes are also more tightly coupled, allowing for quicker data movement between FP and Integer units.
The improvements to the FP/NEON side are expected to show up quite nicely in benchmarks. ARM shared performance data using an FFMPEG workload on simulated Cortex A9 and Cortex A12 designs at the same frequency with the same number of cores (1):
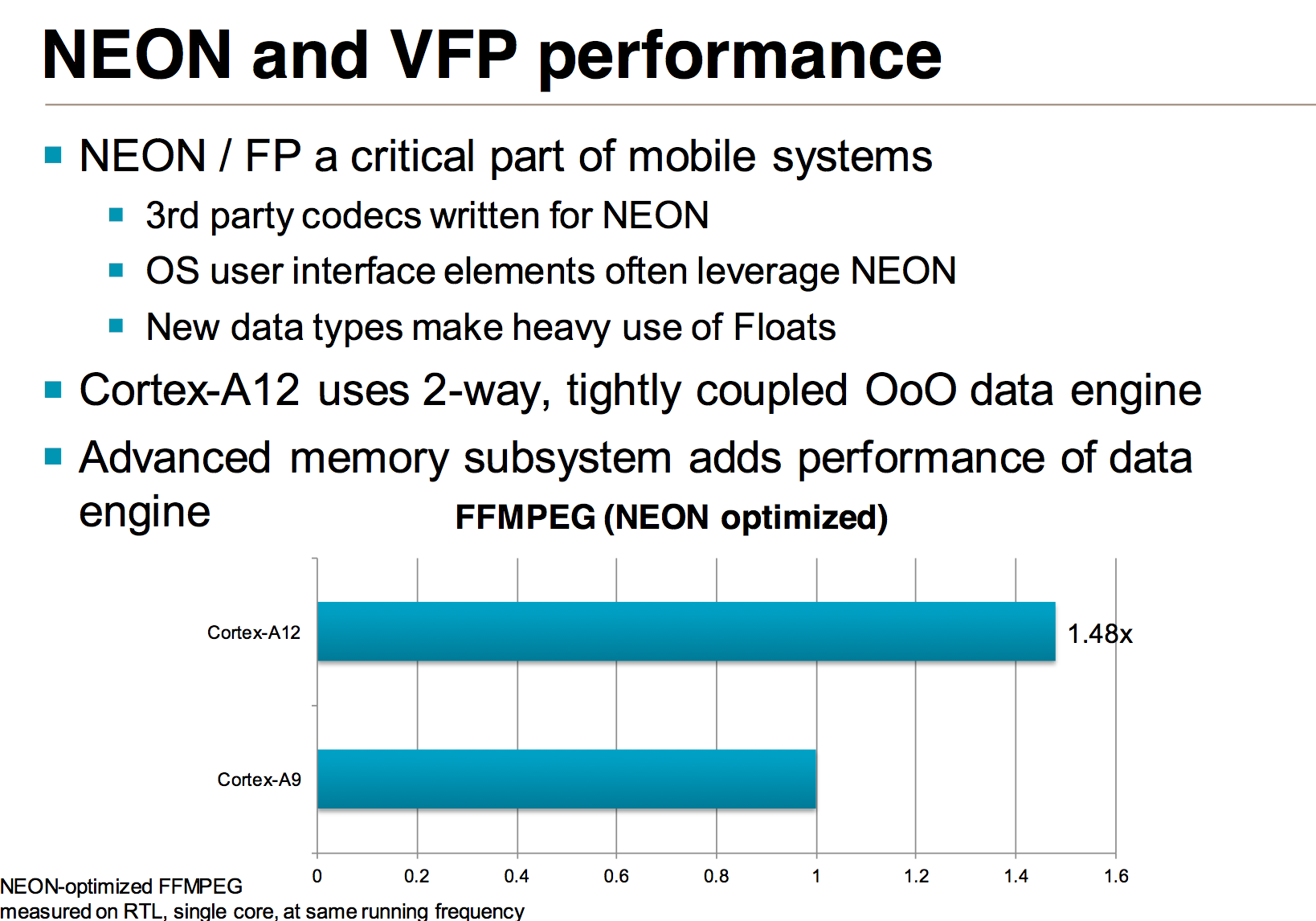
A 48% increase in NEON performance isn’t unexpected at all given the magnitude of improvements to this part of the execution engine.
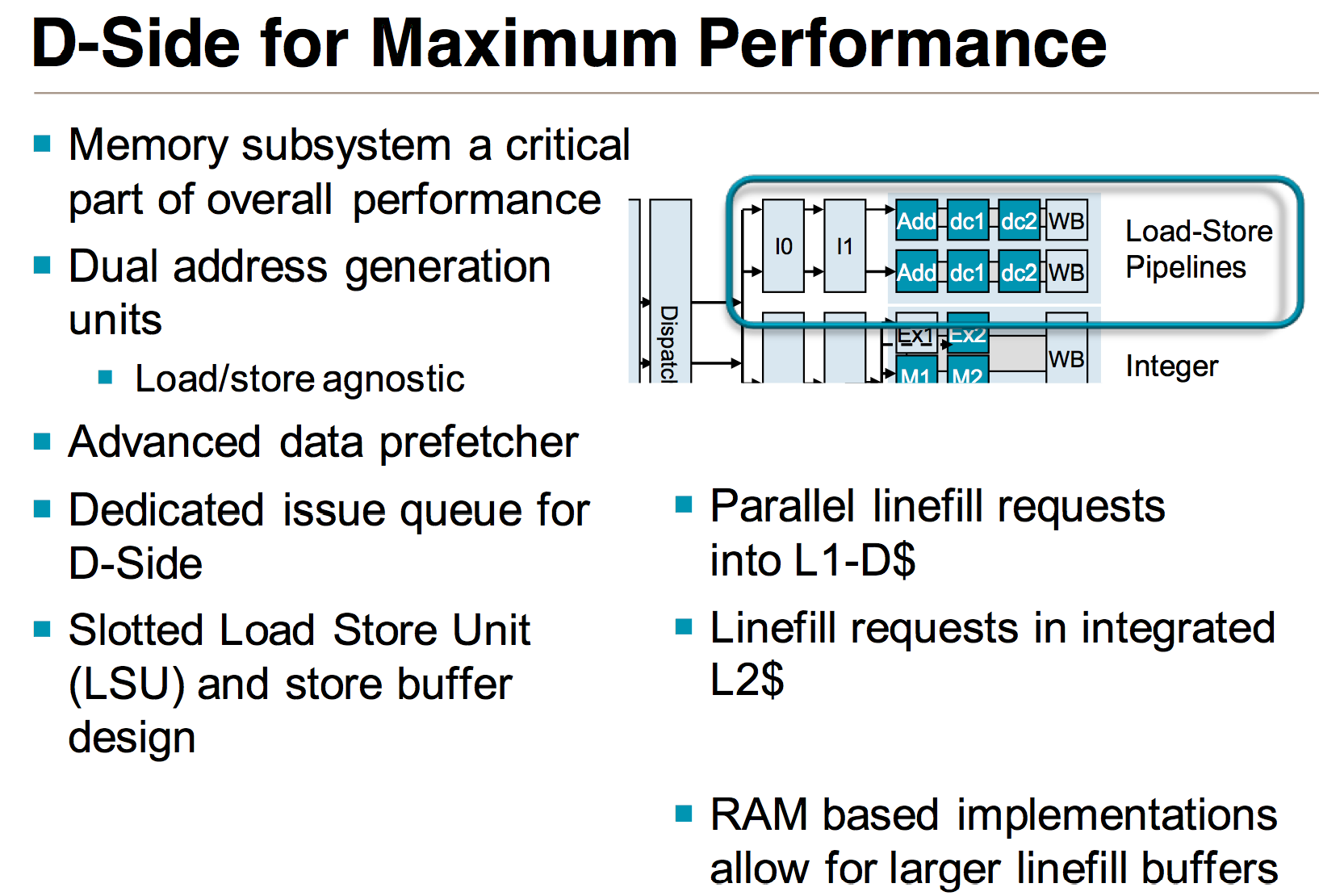
The final issue queue feeds the two load-store pipelines with two AGUs, once again a doubling from what was present in the Cortex A9 design. Each pipeline is equally capable (load/store agnostic) and mostly out-of-order (limits on what you can re-order if there are address dependencies between loads). By comparison, the load/store pipe in Cortex A9 was fully in-order.








65 Comments
View All Comments
wumpus - Friday, July 19, 2013 - link
And I didn't see anyway for 32bit ARM to access more than 3G. Maybe there is, but the PAE-style mechanism that allowed each process to access 4G of ram (well 2-3G of user space and 2-1G of OS space). It looks like each process sees 32 bit MMU tags meaning no way to access the whole RAM. Again, somewhere in there they might have an unholy kludge, but I suspect that they are more than willing to do things the [PAE] intel way [not the 286 way that Microsoft forced everyone to support a decade after it was consigned to the junkyard].wumpus - Friday, July 19, 2013 - link
So how does one process access more than 4G (3G if Linux, likely less else where)? There is a reason nobody uses 32 bit chips. If you really looked up the datasheets, the *80386* chip could access way more than 64G virtual ram (it didn't have the pins for more than 4G of memory). You could even access it fairly easily in a process, but as far as I know *nobody* ever tried that.Note: Linux 0.x and I think 1.x could both handle 3G per memory process. Maybe not, I know Linus used the 386 segmentation scheme natively on different processes, but I have no idea if the 386 MMU could handle tags that depended on the segmentation scheme (it was quite possible you could either go wild with segments, or use them traditionally and have full MMU operation. I haven't looked at this stupid idea since 1990, when I learned the disaster that is x86.
We use 64 bit chips for a reason. If we didn't need to access memory the size of an integer register, I would strongly suspect that all integer registers would be 16 bits long (note the pentium4 computed integer operations 16 bits at a time, they are notably faster). Using a 64 bit register and 64 bit addressing means that you can access an entire database of arbitrary size (2^63, whatever that is), while using 32 bit machines requires a "networking" OS call to whichever process happens to have that particular datum in memory. It is yet another unholy kludge and the reason that "the only fatal mistake a computer architecture can have is too small a word size".
Wilco1 - Friday, July 19, 2013 - link
You don't need to access more than 3GB per process on a mobile! Mobiles/tablets will have 4GB of RAM, however each process still has it's own 32-bit address space and uses only a portion of the available RAM.There is no need to be so obsessed about 64-bit, you know the the Windows world is still mostly 32-bit 10 years after the introduction of Athlon64... Even Windows 8 still has a 32-bit version. So while there are lots of 64-bit chips around, most run only 32-bit code. My Athlon64 which I retired last year never ever ran 64-bit code during its entire life!
You only really require 64-bit addressing if you have big applications that need more than 3GB per process. Such applications are rare (your database is an example) and they only run on large expensive servers, not on mobiles. So clearly the need for 64-bit is extremely small, and mobiles/tablets will simply use PAE rather than switch to 64-bit for the foreseeable future.
Calinou__ - Saturday, July 20, 2013 - link
64 bit is still a technogy of the future. Not to mention PAE can be quite buggy sometimes, especially when running eg. proprietary drivers.Wolfpup - Thursday, July 25, 2013 - link
The timing on this seems weird. Didn't they know they needed a smaller jump between A9 and A15 years ago? I HOPE it's not really needed by late 2014/2015...I mean I hope by then we're all using A15, and maybe A5x or whatever... Or AMD's low power chips and SIlvermont!