The ARM Diaries, Part 2: Understanding the Cortex A12
by Anand Lal Shimpi on July 17, 2013 12:30 PM EST- Posted in
- CPUs
- Arm
- SoCs
- Cortex A12
Back End Improvements
The front end of the Cortex A12 is a bit more efficient than the Cortex A9, but the bulk of the performance gains really come from improvements to the execution side of the core. Similar to the Cortex A15, ARM introduced multiple independent issue queues ahead of the functional units. It’s important to get nomenclature right here. Instructions are decoded into micro-ops, renamed instructions are dispatched into the issue queues and then micro-ops are issued from the issue queues when their operands are available. Everything up to the issue queue is handled in order, while issuing can be handled out of order in the Cortex A12 (in most cases, more on this later).
Whereas the Cortex A9 had a single issue queue ahead of all functional units, the Cortex A12 moves to three independent issue queues. The A9’s issue queue could hold 4 decoded instructions, while each issue queue in Cortex A12 is larger than that. The move to larger independent issue queues alone should help with increasing IPC.
The three issue queues are as follows: one for integer, one for FP/NEON and one for loads and stores. ARM provided bits and pieces of an architectural block diagram for the Cortex A12. I reconstructed one as best as I could below. The blue blocks indicate in-order components of the design, while the pink/salmon blocks are out-of-order. You can toggle between the A12 and A9 diagrams to see how things have changed.
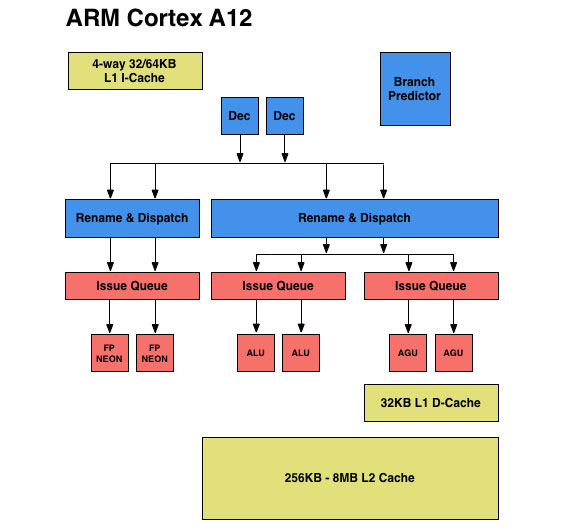
Cortex A12 retains the two integer pipelines of the Cortex A9, but adds support for integer divides (like the A7 and A15, other A-series architectures generally lacked support for hardware int divides). The rest of the integer execution capabilities are unchanged.
The FP/NEON units are vastly improved on the Cortex A12. When the Cortex A9 was first introduced, NEON code was rarely used which even lead NVIDIA to dropping NEON support altogether in Tegra 2. Times quickly changed as NEON code is widely used in Android and mobile applications.
The Cortex A12 design retains separate physical register files for integer and FP operations, but the RFs are larger than in Cortex A9.
Although Cortex A9 was considered an out-of-order microarchitecture, all FP and NEON instructions were executed in-order. With Cortex A12, ARM moves to a fully out-of-order architecture, at least as far as non-memory-ops are concerned. The FP/NEON issue queue now dual-issues into two FP/NEON pipes, both of which operate fully out-of-order. The FP/NEON pipes are also more tightly coupled, allowing for quicker data movement between FP and Integer units.
The improvements to the FP/NEON side are expected to show up quite nicely in benchmarks. ARM shared performance data using an FFMPEG workload on simulated Cortex A9 and Cortex A12 designs at the same frequency with the same number of cores (1):
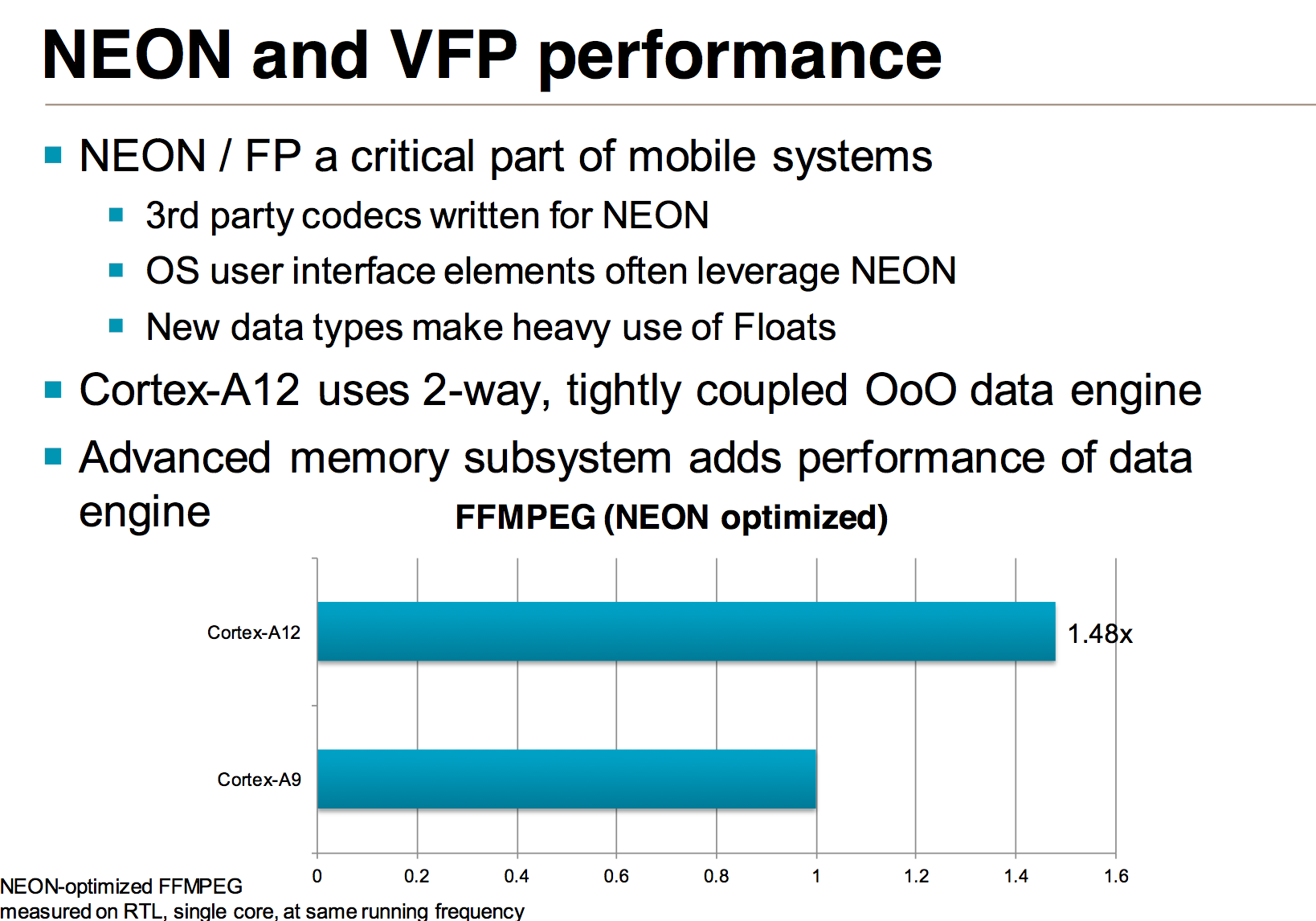
A 48% increase in NEON performance isn’t unexpected at all given the magnitude of improvements to this part of the execution engine.
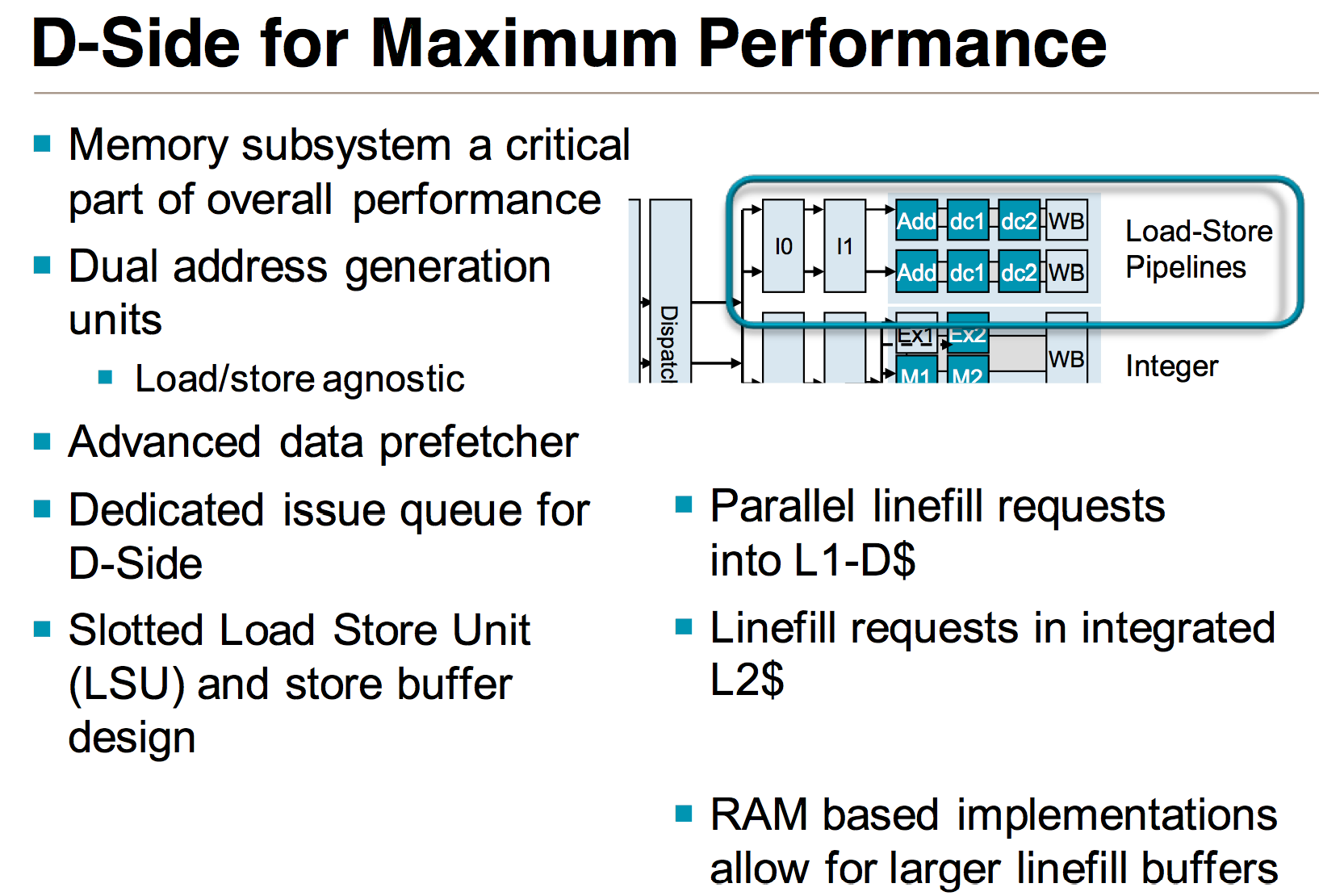
The final issue queue feeds the two load-store pipelines with two AGUs, once again a doubling from what was present in the Cortex A9 design. Each pipeline is equally capable (load/store agnostic) and mostly out-of-order (limits on what you can re-order if there are address dependencies between loads). By comparison, the load/store pipe in Cortex A9 was fully in-order.








65 Comments
View All Comments
haukionkannel - Wednesday, July 17, 2013 - link
I am interested in how this A12 compares to A53 in speed wise... A53 has wider registers (64 bit) but A12 run in higher freguensis and has more cores?Wilco1 - Wednesday, July 17, 2013 - link
A12 will beat A53 by about 40%: A53 delivers performance comparable to A9 and A12 is 40% faster than A9. Note that 64-bit is not relevant and certainly doesn't provide a big speedup - even on x86 almost all software is still 32-bit as there is little to gain from going to 64-bit.jwcalla - Wednesday, July 17, 2013 - link
Well this isn't entirely accurate as some of us are running almost completely pure 64-bit systems. And it does appear that video encoding and decoding are common operations that can benefit from 64-bit software from some of the benchmarks I've seen, but that might actually have been from compiler options so maybe not. But otherwise yes, the 64-bit ARM chips are only really important for server type workloads where people already have 64-bit software that they don't want to rework.Wilco1 - Wednesday, July 17, 2013 - link
64-bit has pros and cons. x64 provides more registers so some applications run faster when built for 64-bit - that may well the video codecs you mention. However there are downsides as well, as all your pointers double in size, which slows down pointer heavy code. On 64-bit ARM things will be similar.Note the main reason for 64-bit is allowing more than 4GB of memory. The latest 32-bit ARMs already support this, so for mobiles/tablets etc there is no need to change to 64-bit.
wumpus - Thursday, July 18, 2013 - link
Er, no. Just no.From what I can tell, 32 bit ARM chips use (from a developer's view) the exact same mechanism as x86 and PAE. This might use 4G of RAM efficiently (and for those OSs that like to leave all apps in RAM, it might work well for a bit more).
Trying to address more memory than an integer register can map to is always going to be an unholy kludge (although I would personally recommend all computer architects design such a system into the architecture because it *will* happen if the architecture succeeds at all). Since ARM chips tend to go into machines that rarely allow memory to be upgraded, no vendor really should be selling machines with >4G RAM and 32 bit accessing. The size/power/cost tradeoff isn't worth it
google "Support for ARM LPAE". All my links go straight to the pdfs and I wind up with all the google code inbedded in my links.
Calinou__ - Thursday, July 18, 2013 - link
PAE doesn't allow for more than 3 GB per process. ;)Wilco1 - Thursday, July 18, 2013 - link
A15 based servers will have 8-32GB. So yes it does go well over 4GB, that's the whole point of PAE. Mobiles will end up with 4GB RAM soon and because of PAE there is no need to use 64-bit CPUs (which would be way overkill for a mobile).Yes I know about ARM LPAE and that it is supported in Linux.
fteoath64 - Friday, July 19, 2013 - link
"PAE there is no need to use 64-bit CPUs". Agreed. More effort to be spend on optimizing for speed and power efficiency.jensend - Friday, July 19, 2013 - link
"Cortex A12 retains the two integer pipelines of the Cortex A9, but adds support for integer divides (like the A7 and A15, other A-series architectures generally lacked support for hardware int divides)"The parenthetical material is very unclear. It sounds like it's saying "The A12 has hardware divides, the A15 and A7 don't, and other A-series archs likewise don't." A simple edit makes the sentence much more clear and slightly more concise:
"Cortex A12 retains the two integer pipelines of the Cortex A9; however, like the A7 and A15, it adds support for hardware integer divides (which previous A-series architectures generally lacked)."
phoenix_rizzen - Friday, July 19, 2013 - link
An even simpler edit is to just change the parenthetical comma into a semi-colon:"Cortex A12 retains the two integer pipelines of the Cortex A9, but adds support for integer divides (like the A7 and A15; other A-series architectures generally lacked support for hardware int divides)"