The Haswell Review: Intel Core i7-4770K & i5-4670K Tested
by Anand Lal Shimpi on June 1, 2013 10:00 AM EST
This is a very volatile time for Intel. In an ARM-less vacuum, Intel’s Haswell architecture would likely be the most amazing thing to happen to the tech industry in years. In mobile Haswell is slated to bring about the single largest improvement in battery life in Intel history. In graphics, Haswell completely redefines the expectations for processor graphics. There are even some versions that come with an on-package 128MB L4 cache. And on the desktop, Haswell is the epitome of polish and evolution of the Core microprocessor architecture. Everything is better, faster and more efficient.
There’s very little to complain about with Haswell. Sure, the days of insane overclocks without touching voltage knobs are long gone. With any mobile-first, power optimized architecture, any excess frequency at default voltages is viewed as wasted power. So Haswell won’t overclock any better than Ivy Bridge, at least without exotic cooling.
You could also complain that, for a tock, the CPU performance gains aren’t large enough. Intel promised 5 - 15% gains over Ivy Bridge at the same frequencies, and most of my tests agree with that. It’s still forward progress, without substantial increases in power consumption, but it’s not revolutionary. We compare the rest of the industry to Intel’s excellent single threaded performance and generally come away disappointed. The downside to being on the top is that virtually all improvements appear incremental.
The fact of the matter is that the most exciting implementations of Haswell exist outside of the desktop parts. Big gains in battery life, power consumption and even a broadening of the types of form factors the Core family of processors will fit into all apply elsewhere. Over the coming weeks and months we’ll be seeing lots of that, but today, at least in this article, the focus is on the desktop.






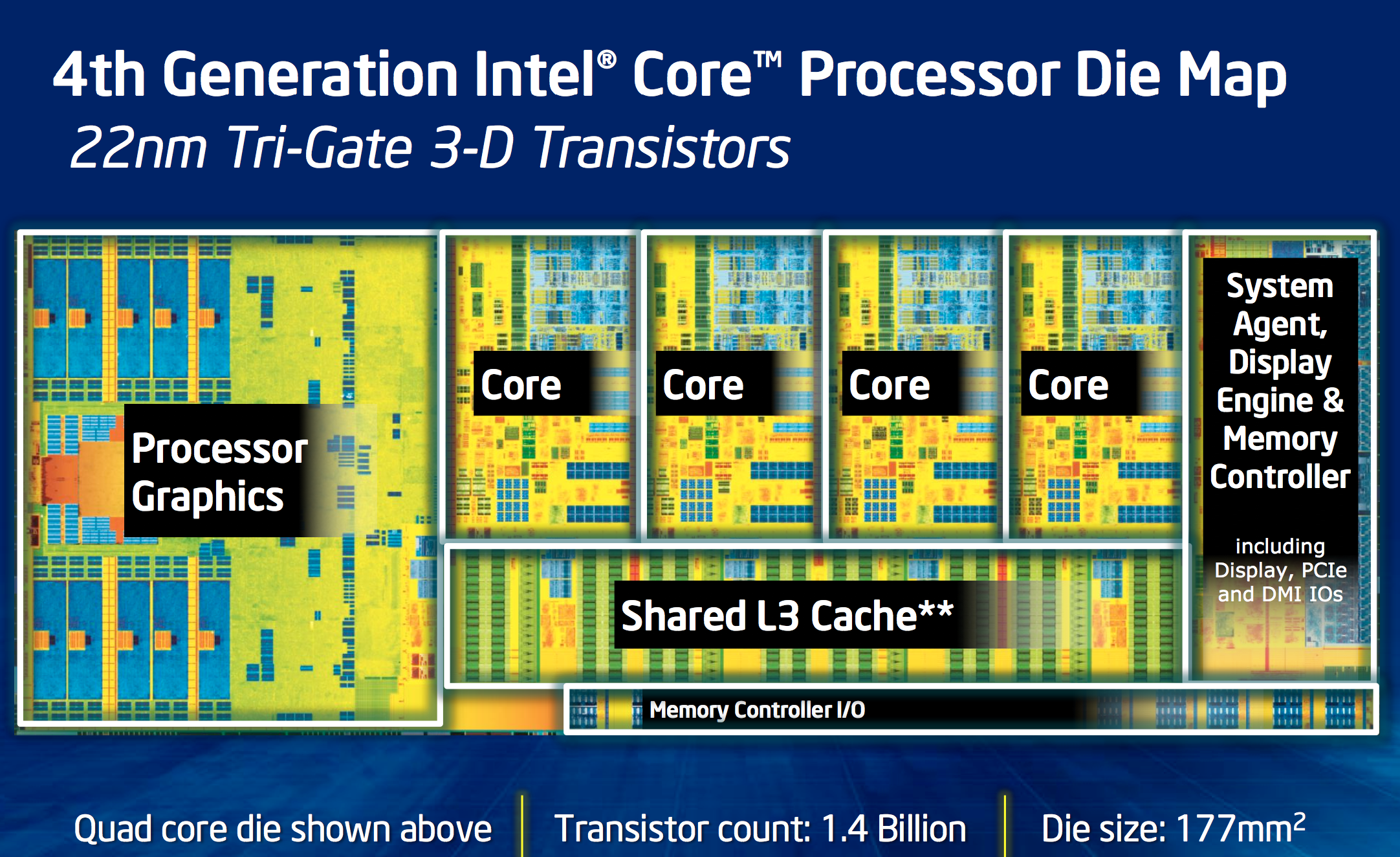
Haswell CPU Architecture Recap
Haswell is Intel’s second 22nm microprocessor architecture, a tock in Intel’s nomenclature. I went through a deep dive on Haswell’s Architecture late last year after IDF, but I’ll offer a brief summary here.
At the front end of the pipeline, Haswell improved branch prediction. It’s the execution engine where Intel spent most of its time however. Intel significantly increased the sizes of buffers and datastructures within the CPU core. The out-of-order window grew, to feed an even more parallel set of execution resources.
Intel added two new execution ports (8 vs 6), a first since the introduction of the Core microarchitecture back in 2006.
On the ISA side, Intel added support for AVX2, which includes an FMA operation that considerably increases FP throughput of the machine. With a doubling of peak FP throughput, Intel doubled L1 cache bandwidth to feed the beast. Intel also added support for transactional memory instructions (TSX) on some Haswell SKUs.
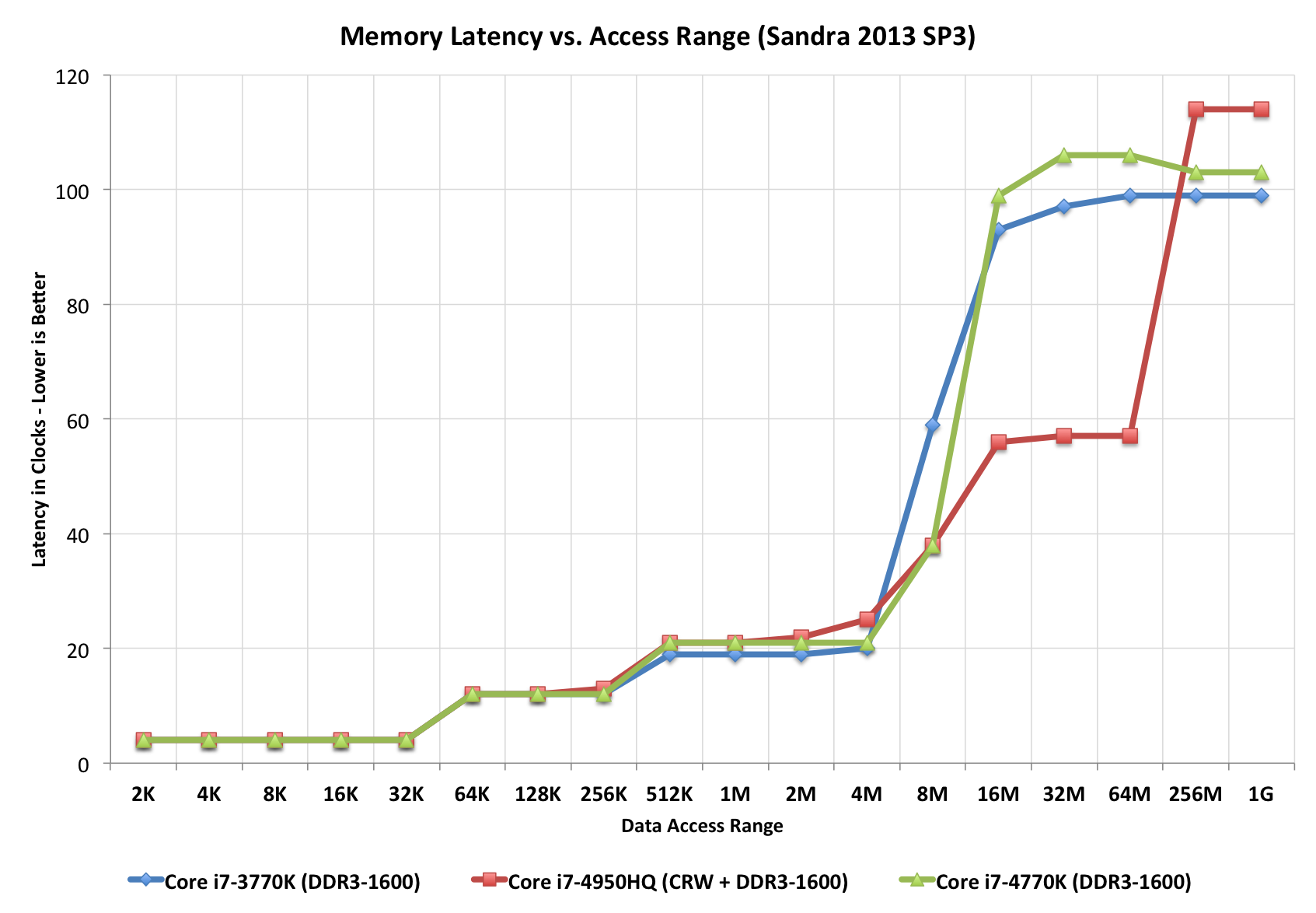
The L3 cache is now back on its own power/frequency plane, although most of the time it seems to run in lockstep with the CPU cores. There appears to be a 2 - 3 cycle access penalty as a result of decoupling the L3 cache.








210 Comments
View All Comments
Amaranthus - Monday, June 3, 2013 - link
One of the main (and already implemented) uses of TSX is hardware lock elision. I'd guess the hypothesis is that physics code takes locks defensively but rarely actually have contention because they're working on different parts of the world. In this scenario more fine grained locks on sections of the world would let you scale better but that is a lot of work and HLE gives you the same benefit for free.Jaybus - Monday, June 3, 2013 - link
No. HLE (XACQUIRE and XRELEASE) do nothing by themselves. They reuse REPNE/REPE prefixes and on CPUs that do not support TSX are ignored on instructions that would be valid for XACQUIRE/XRELEASE if TSX were available. It is a backward compatibility method. Since all of those instructions may have a LOCK prefix, without TSX capability, a normal lock is used, NOT the optimistic locking provided by TSX that allows other threads to see the lock as already free.Without TSX the code is still (software) lock-free, but there is no possibility of multiple threads accessing the same memory simultaneously (as there is with TSX), so one or more threads will see a pipeline stall due to the LOCK prefix.
bji - Monday, June 3, 2013 - link
I can't imagine that lock elision is that beneficial to very many applications. Lock contention is almost never a significant performance bottleneck; yeah there are poorly designed applications where lock contention can have a more significant effect, but proper multithreaded coding has the contended sections of code reduced to the smallest number of instructions possible, at which point the effects of lock contention are minimized.In order to take advantage of transactional memory and get the full benefits of TSX you have to write such radically different algorithms that I doubt that it's worth it except in the most unusual and specific cases. OK so you can use TSX instructions to make a hashtable or other container class suffer slightly less from lock contention, but that is oh so very rarely a significant aspect to the performance of any program.
klmccaughey - Monday, June 3, 2013 - link
As a programmer, I disagree. This is a very useful feature set that, if it was more widely adopted, would prove very useful for many workaday tasks that the CPU performs.bji - Monday, June 3, 2013 - link
As a programmer, I am pretty sure that the benefits of TSX are limited to a very unusual and uncommon set of problems the performance increase of which will mean very very little to 99.99% of users 99.99% of the time. Also fully transactional memory algorithms require significant rework from their non-transactional counterparts meaning that taking full advantage of TSX takes developer effort which will not be worth it except in very rare circumstances.The HLE instructions may have some very minor benefit because they can be used with algorithms that don't need to be reworked at all (you just get a little bit more parallelism for free), but even then you're going to be avoiding some lock contention; even if you completely eliminated lock contention from most algorithms they would only be fractionally faster in real world usage. Lock contention just isn't that big of a deal in normal circumstances.
klmccaughey - Monday, June 3, 2013 - link
Exactly. It would be the ubiquity of these features that would cause them to be useful - splitting them into segments defeats the adoption and use of said features. Intel are pushing segmentation too hard (too greedily?)bill5 - Saturday, June 1, 2013 - link
kind if a weird, scattered review.loved the q6600 though, since i still have one. and the 8350, since i have my eye on it.
be interesting if this pushed 8350 prices down enough to be more attractive (it's currently only 180 on newegg). if not i'll probably go with i5 4670 (even though i'm getting tired of these faux msrp's, bet money that chip will be 229 on newegg forget 213)
ps, my bill4 account was apparently banned (it kept saying i was posting spam wouldn't allow me to post) i post controversial things that probably get downvoted, but they arent spam. please stop doing that.
bill5 - Saturday, June 1, 2013 - link
this really shows where the 8350 fails, single thread.it looks like clock for clock it's ipc may be similar to my q6600. it only gains in single thread due to the gaudy 4.0 clock speed.
otoh go to multithread and it holds it's own against the other ~200 intel chips.
Nexus-7 - Saturday, June 1, 2013 - link
In for one 4770k --I'm coming from an i5-750 running at 4GHz. I'm thinking this will be a sufficiently large leap forward although I'm tempted to wait for Ivy Bridge-E's 6c12t monsters.
chizow - Saturday, June 1, 2013 - link
Similar boat, but I told myself I wouldn't wait for Intel's E platform anymore. X58 may be the last great E platform, mainly because it actually preceded the rest of the mainstream performance parts. Intel seems to sit on these E platforms for so long now that they almost become irrelevant by the time they launch.