Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
by Anand Lal Shimpi on June 1, 2013 10:01 AM ESTCompute Performance
With Haswell, Intel enables full OpenCL 1.2 support in addition to DirectX 11.1 and OpenGL 4.0. Given the ALU-heavy GPU architecture, I was eager to find out how well Iris Pro did in our compute suite.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
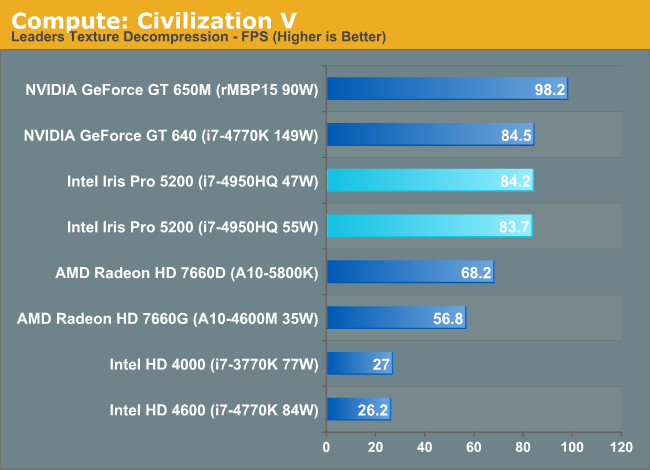
Iris Pro does very well here, tying the GT 640 but losing to the 650M. The latter holds a 16% performance advantage, which I can only assume has to do with memory bandwidth given near identical core/clock configurations between the 650M and GT 640. Crystalwell is clearly doing something though because Intel's HD 4600 is less than 1/3 the performance of Iris Pro 5200 despite having half the execution resources.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.

Moving to OpenCL, we see huge gains from Intel. Kepler wasn't NVIDIA's best compute part, but Iris Pro really puts everything else to shame here. We see near perfect scaling from Haswell GT2 to GT3. Crystalwell doesn't appear to be doing much here, it's all in the additional ALUs.
Our 3rd benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


Once again, Iris Pro does a great job here, outpacing everything else by roughly 70% in the Fluid Simulation test.
Our final compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.

Iris Pro rounds out our compute comparison with another win. In fact, all of the Intel GPU solutions do a good job here.








177 Comments
View All Comments
boe - Monday, June 3, 2013 - link
As soon as intel CPUs have video performance that exceeds NVidia and AMD flagship video cards I'll get excited. Until then I think of them as something to be disabled on workstations and to be tolerated on laptops that don't have better GPUs on board.MySchizoBuddy - Monday, June 3, 2013 - link
So Intel just took the OpenCL crown. Never thought this day would come.prophet001 - Monday, June 3, 2013 - link
I have no idea whether or not any of this article is factually accurate.However, the first page was a treat to read. Very well written.
:)
Teemo2013 - Monday, June 3, 2013 - link
Great success by Intel.4600 is near GT630 and HD4650 (much better than 6450 which sells for $15 at newegg)
5200 is better than GT640 and HD 6670 (currently sells like $50 at newegg)
Intel's intergrated used to be worthless comparing with discret cards. It slowly catches up during the past 3 years, and now 5200 is beating a $50 card. Can't wait for next year!
Hopefully this will finally push AMD and Nvidia to come up with meaningful upgrade to their low level product lines.
Cloakstar - Monday, June 3, 2013 - link
A quick check for my own sanity:Did you configure the A10-5800K with 4 sticks of RAM in bank+channel interleave mode, or did you leave it memory bandwidth starved with 2 sticks or locked in bank interleave mode?
The numbers look about right for 2 sticks, and if that is the case, it would leave Trinity at about 60% of its actual graphics performance.
I find it hard to believe that the 5800K is about a quarter the performace per watt of the 4950HQ in graphics, even with the massive, server-crushing cache.
andrerocha - Monday, June 3, 2013 - link
is this new cpu faster than the 4770k? it sure cost more?zodiacfml - Monday, June 3, 2013 - link
impressive but one has to take advantage of the compute/quick sync performance to justify the increase in price over the HD 4600ickibar1234 - Tuesday, June 4, 2013 - link
Well, my Asus G50VT laptop is officially obsolete! A Nvidia 512MB GDDR3 9800gs is completely pwned by this integrated GPU, and, the CPU is about 50-65% faster clock for clock to the last generation Core 2 Duo Penryn chips. Sure, my X9100 can overclock stably to 3.5GHZ but this one can get close even if all cores are fully taxed.Can't wait to see what the Broadwell die shrink brings, maybe a 6-core with Iris or a higher clocked 4-core?
I too see that dual core versions of mobile Haswell with this integrated GPU would be beneficial. Could go into small 4.5 pounds laptops.
AMD.....WTH are you going to do.
zodiacfml - Tuesday, June 4, 2013 - link
AMD has to create a Crystalwell of their own. I never thought Intel could beat them to it since their integrated GPUs always has needed bandwidth ever since.Spunjji - Tuesday, June 4, 2013 - link
They also need to find a way past their manufacturing process disadvantage, which may not be possible at all. We're comparing 22nm Apples to 32/28nm Pears here; it's a relevant comparison because those are the realities of the marketplace, but it's worth bearing in mind when comparing architecture efficiencies.