AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM ESTCompute Unit
Bobcat was pretty simple from a multi-core standpoint. Each Bobcat core had its own private 512KB L2 cache, and all core-to-core communication happened via a bus interface on each of the cores. The cache hierarchy was exclusive, as has been the case with all of AMD’s previous architectures.
Jaguar changes everything. AMD defines a Jaguar compute unit as up to four cores with a single, large, shared L2 cache. The L2 cache can be up to 2MB in size and is 16-way set associative. The L2 cache is also inclusive, a first in AMD’s history. In the past AMD always implemented exclusive caches as the inclusive duplicating of L1 data in L2 meant a smaller effective L2 cache. The larger shared L2 cache is responsible for up to another 5-7% increase in IPC over Bobcat (totaling ~22%).
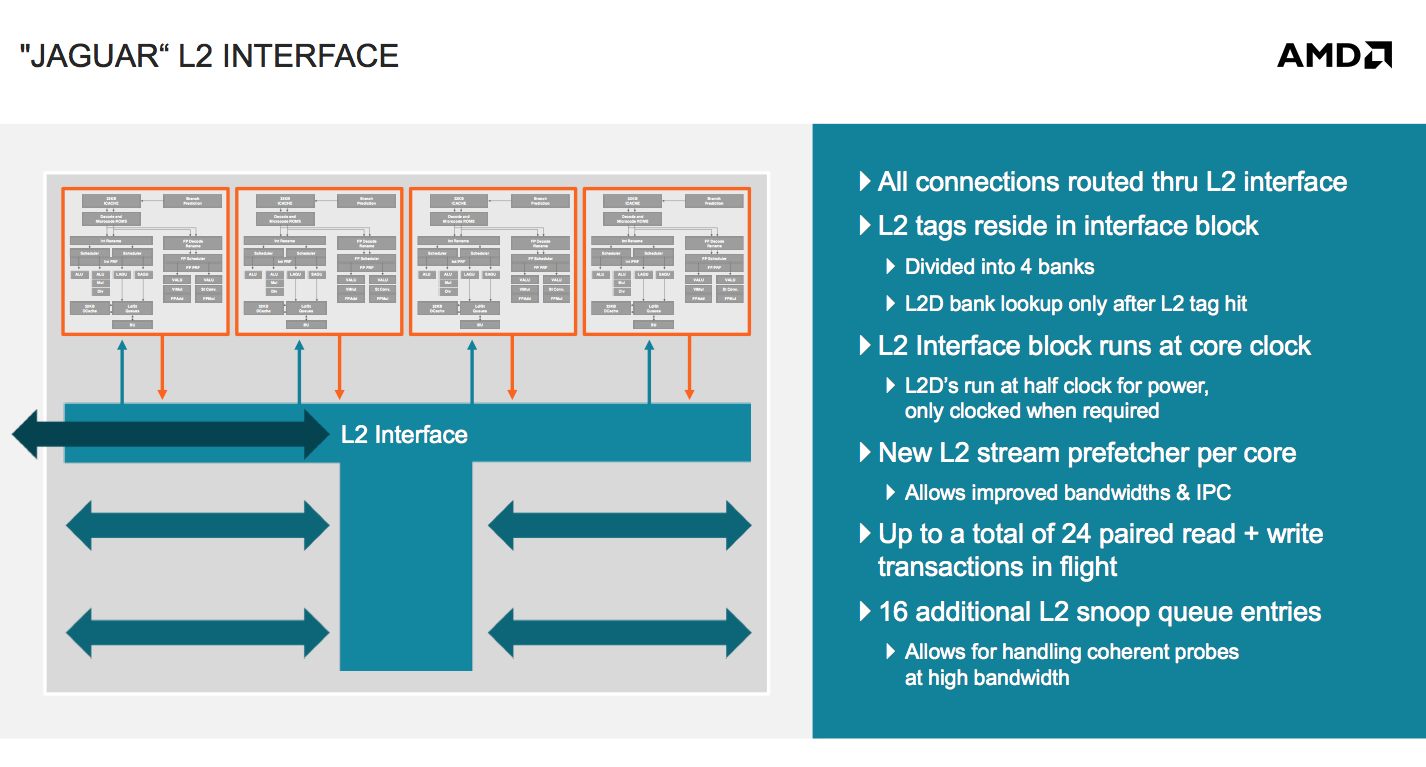
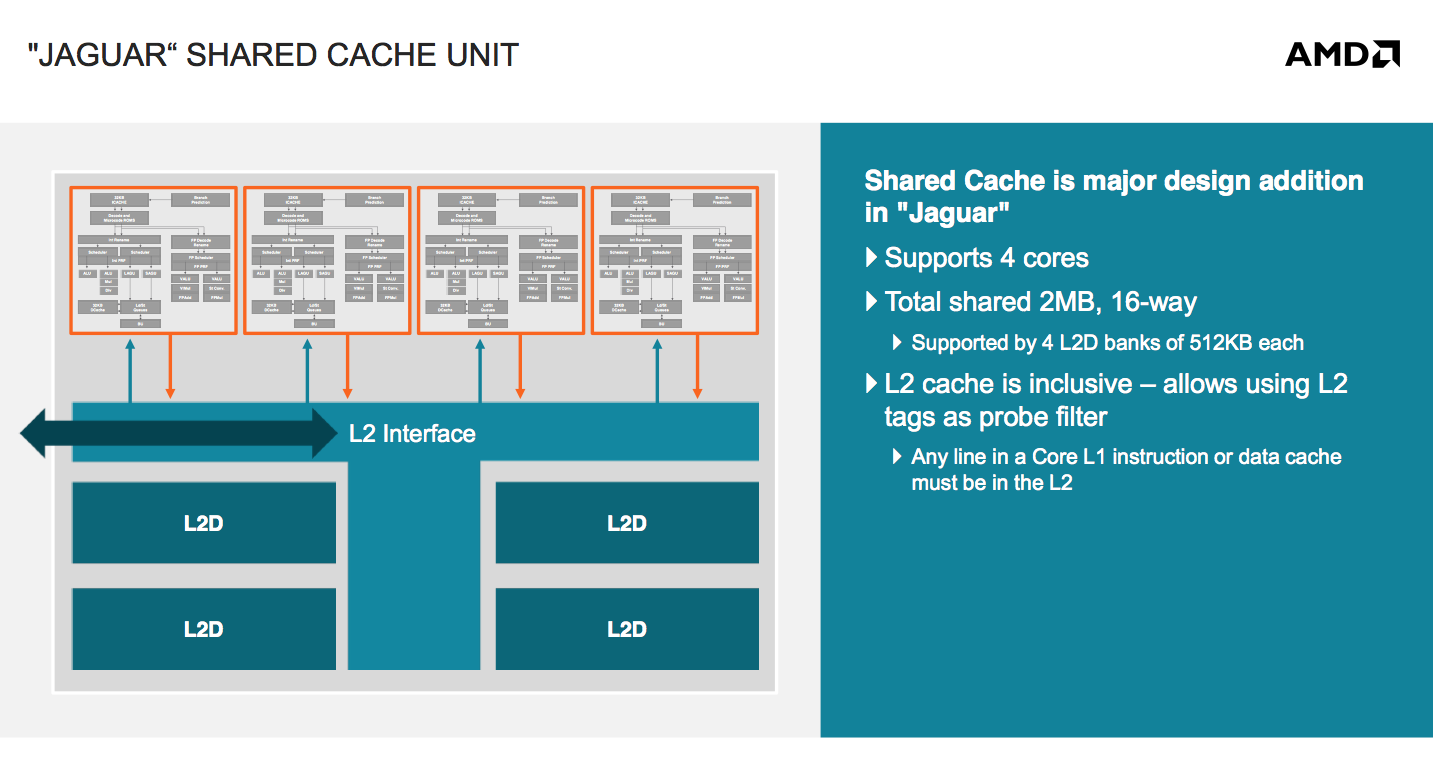
AMD’s new cache architecture and lower latency core-to-core communication within a Jaguar compute unit means an even greater performance advantage over Bobcat in multithreaded workloads:
| Multithreaded Performance Comparison | ||||||||||||||||
| # of Cores | Cinebench 11.5 (Single Threaded) | Cinebench 11.5 (Multithreaded) | ||||||||||||||
| AMD A4-5000 (1.5GHz Jaguar x 4) | 4 | 0.39 | 1.5 | |||||||||||||
| AMD E-350 (1.6GHz Bobcat x 2) | 2 | 0.32 | 0.61 | |||||||||||||
| Advantage | 100% | 21.9% | 145.9% | |||||||||||||
The L1 caches remain unchanged at 32KB/32KB (I/D cache) per core.
Physical Layout and Synthesis
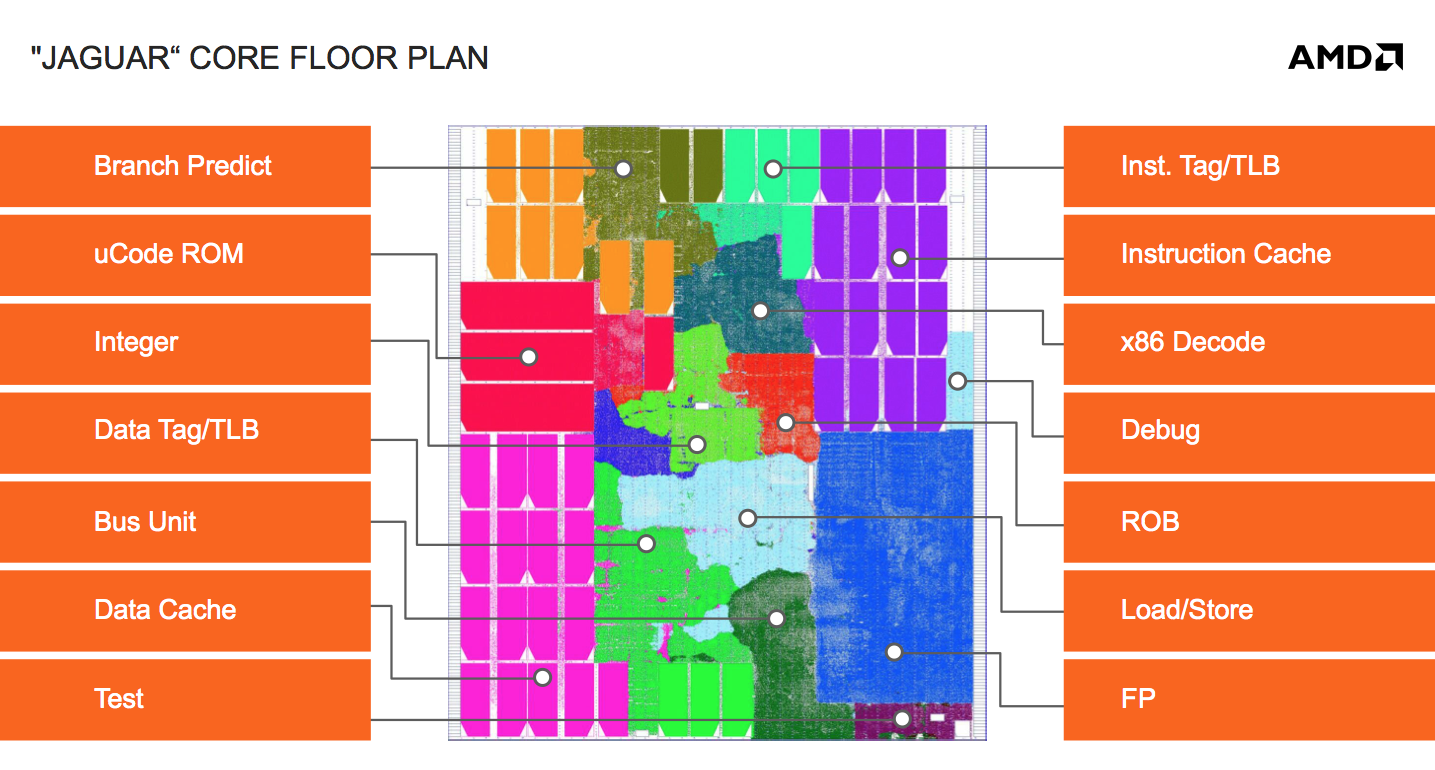
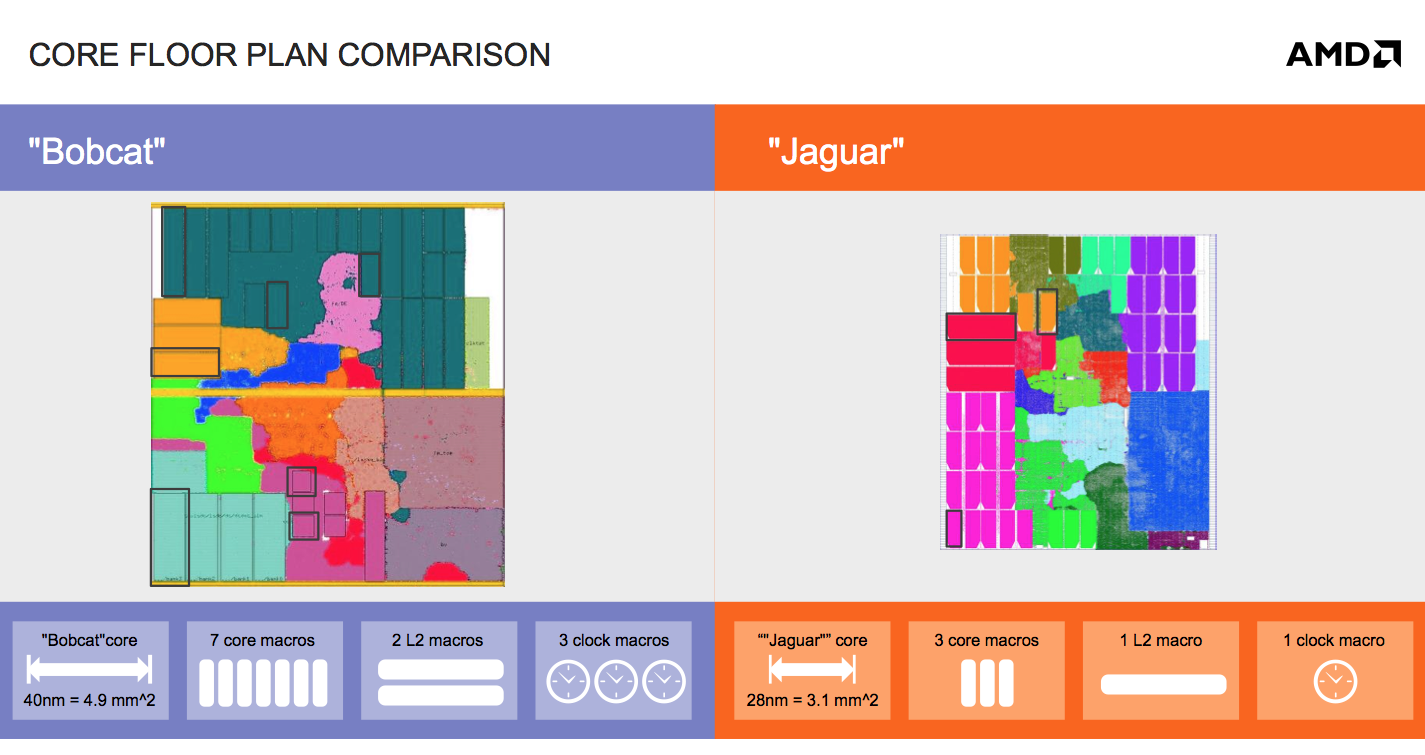
Bobcat was AMD’s first easily synthesized CPU core, it was a direct result of the ATI acquisition years before. With Jaguar, AMD made a conscious effort to further reduce the number of unique macros required by the design. The result was a great simplification, which helped AMD port Jaguar between foundries. There’s of course an area tradeoff when moving away from custom macros to more general designs but it was deemed worthwhile. Looking at the results, you really can’t argue. A single Jaguar core measures only 3.1mm^2 at 28nm compared to 4.9mm^2 for a 40nm Bobcat.








78 Comments
View All Comments
Wolfpup - Wednesday, June 12, 2013 - link
Ironically when I see an Intel sticker on a tablet (unless it's a Core i part), I avoid it like the plague. Bobcat would have been perfect for tablets, and a BIG selling point.Wolfpup - Wednesday, June 12, 2013 - link
Yeah, I really have no interest in an Atom tablet, partially even just because of the horrible video.I've got an 11.6" AMD c50 (lowest end Bobcat) based notebook, and while it's slow, it's still impressive how it runs anything, and in a pinch can even function as a main PC. AMD's got an even lower power Bobcat part with the exact same performance for tablets, but I don't know of shipping computers that used it, and it really would have been perfect. These new ones of course will be even better.
I wonder if the companies building these understand that using AMD would be a selling point... I see "Atom" and my eyes glaze over....
codedivine - Thursday, May 23, 2013 - link
4 DP FMAs per 16 cycles? Why even bother putting them in :|Tuna-Fish - Thursday, May 23, 2013 - link
Because it's expected by the spec, and some compute loads use it for very rarely used things.Exophase - Thursday, May 23, 2013 - link
"I should point out that ARM is increasingly looking like the odd-man-out here, with both Jaguar and Intel’s Silvermont retaining the dual-issue design of their predecessors."It's not just ARM, it's three different current gen ARM cores.. if you're going to pose it as ISA shouldn't it then just be ARM vs x86 and not ARM vs Silvermont and Jaguar?
Besides, MIPS is 3-way in its CPUs targeting this power budget too (proAptiv), and so is PowerPC (e600 for instance). The reason why Silvermont and Jaguar is 2-way is really undeniable: x86 decoders are substantially more expensive than those for any of these ISAs, even Thumb-2. There's some validity to the argument that x86 instructions are more powerful (after first negating where they aren't - most critically, lack of three-way addressing adds a lot of extra move instructions for non-AVX processors) but nowhere close to 50% more powerful.
lmcd - Thursday, May 23, 2013 - link
Isn't Qualcomm Krait 2-way?Exophase - Thursday, May 23, 2013 - link
Qualcomm hasn't said an awful lot about the internals of the uarch but several sources report 3-way decode and I haven't seen any say 2-way. It's possible that isn't fully symmetric or limited in some other way, we don't really know.Krysto - Friday, May 24, 2013 - link
Pretty sure it's 3-way.tiquio - Thursday, May 23, 2013 - link
I don't really understand the point about unique macros. What are macros in reference to CPU architecture.quasi_accurate - Thursday, May 23, 2013 - link
Don't worry, I had no idea either until I started working in the industry :) It just means custom circuits that are hand crafted by a human. This is as opposed to "synthesis", in which the RTL code (written in a hardware description language such as Verilog) are "synthesized" by design software into circuits.