Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Brownian Motion
Part of my regular motherboard review testing is to tackle the Brownian motion of particles. This considers one of two physical scenarios - either gas in a vacuum or a dissolved substance in a fluid, where those particles that are free to move can do so. These particles can collide with the medium they are in, each other or the boundaries – in general the system can bypass all these by using the diffusion coefficient (average speed of a particle in a medium). However, the simulation should be probing at least one of them – with the first two situations requiring greater computational complexity than dealing with interactions on a surface.
The movement of these particles is the main computational element of this type of simulation – dealing with either free motion (mean free path in a random direction) or directed motion (applied force on top of free motion). Motion should start with a method to calculate which direction the particle is to travel in, and then any applied force simulated on top – the initial method is at the whim of random number generators and the choice of algorithm. In my original article I go through several methods of generating random motion described in the literature, as well as choosing an appropriate random number generator (too many published methods use basic C++ generators that repeat themselves after a few thousand calls). For simulating, we have various methods:
- If the simulation has a fixed number of time steps, calculate the random numbers before the simulation and use memory calls in the movement algorithm
- Calculate the random numbers on the fly during the algorithm if the time steps for each particle can vary (i.e. no need to track a particle after it collides with a surface)
In our Brownian motion benchmark (3D Particle Movement), we test the six different algorithms used in the literature for random direction movement in both single thread and multithreaded mode. The simulation generates a number of particles, each with its own thread. The thread iterates the particle through a fixed number of steps, and discards the particle. When all the threads have finished, the simulation checks the time to see if 10 seconds have passed - if the 10 seconds are not up, it goes through another loop. Results are then expressed in the form of million particle movements per second for each algorithm, and the total score is the sum of all the algorithms.
This benchmark is wholly memory independent – by generating random numbers on the fly, each thread can keep the position of the particle and the random number values in local cache.
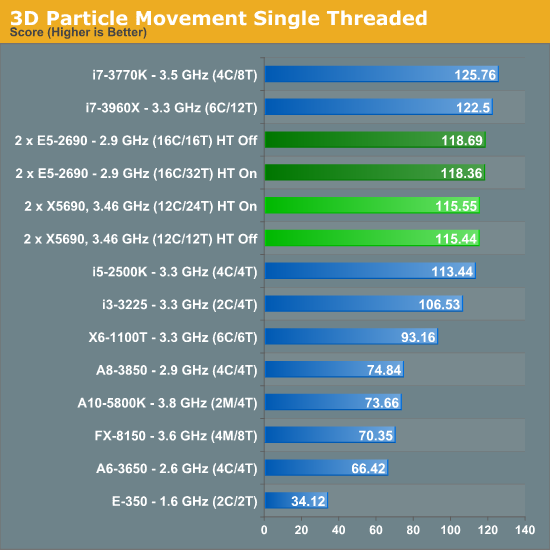
The difference in architectures is most plain to see in our single thread test – both the X5690 and E5-2690 will be applying maximum turbo (3.73 GHz and 3.8 GHz respectively) to similar clocks, meaning the IPC improvements of Sandy Bridge-E give it a 2.5% increase overall despite a mild (1.8%) clock increase.
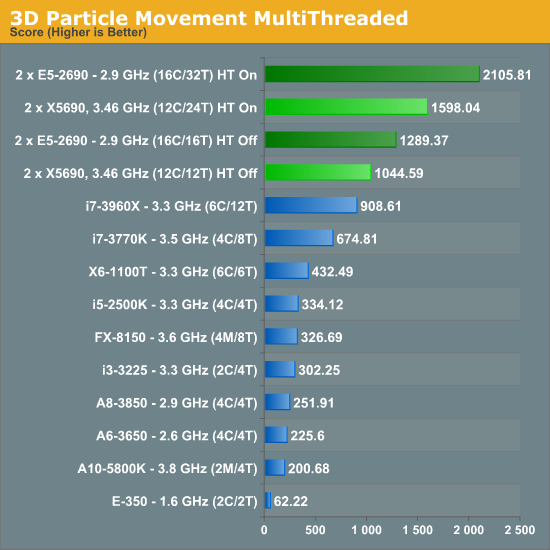
The advantages of more cores for this sort of simulation are plain to see, with the E5-2690 (despite a clock speed difference at full load of 2.9 GHz compared to 3.46 GHz) giving a 32% better result than the X5690.
n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

As the n-body example deals with GFLOPs as a result, the numbers were only ever going to be in favor of the E5-2690s, with a 37% increase over the X5690s. Core count, IPC and memory speed play a role with large O(n2) simulations like these. Oddly enough, while HT Off was preferable on the E5-2690s, HT On gives a better result for X5690s.








44 Comments
View All Comments
nadana23 - Sunday, March 10, 2013 - link
It's a pity you didn't read my reply to the previous article...http://www.anandtech.com/comments/6533/gigabyte-ga...
Your memory setup is the constraining factor here.
Add another 8pcs DIMM to your setup next time - you're bandwidth starving the E5-26xx memory controller!
IanCutress - Tuesday, March 12, 2013 - link
How so? Each channel on both processors is populated by one DIMM. Moving to two DIMMs per channel won't make a difference, they're still fed by the same channel.sking.tech - Tuesday, March 12, 2013 - link
The comments about people berating the Titan GPU - the titan is slower in overall performance than the GTX 690 yet they are at the same price point. That's kind of ridiculous. Why would someone pay more for less?ipheegrl - Thursday, May 23, 2013 - link
I would upgrade from Westmere-EP if it weren't for the fact that it was the last line of Xeons that could overclock. Granted, some people want guaranteed stability so overclocking isn't an option, but for budget users who want performance at the price of decreased stability it's a viable solution.