NVIDIA Tegra 4 Architecture Deep Dive, Plus Tegra 4i, Icera i500 & Phoenix Hands On
by Anand Lal Shimpi & Brian Klug on February 24, 2013 3:00 PM ESTNVIDIA has upped its ISP game with Tegra 4, and includes the same ISP in both Tegra 4 and 4i, which they’ve dubbed Chimera. This new ISP includes a number of features which were already demonstrated at CES, but NVIDIA went into greater detail.

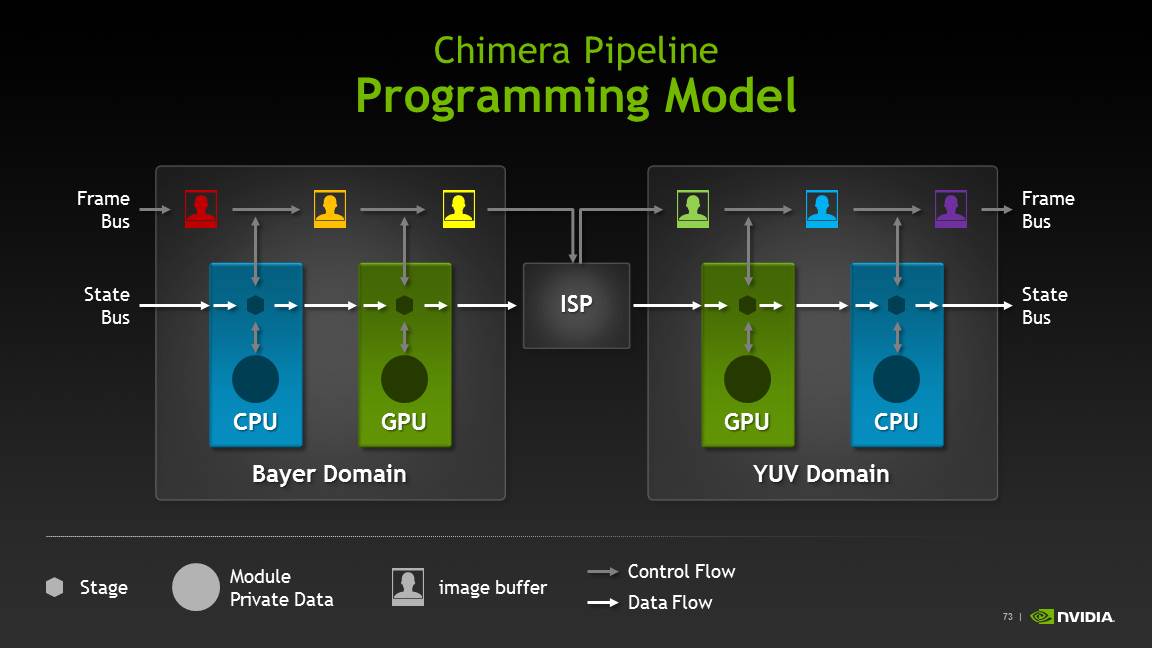
NVIDIA’s major new feature with Tegra 4 is inclusion of new APIs which leverage the GPU to enable computational camera features In addition to the traditional ISP pipeline. To begin, NVIDIA has made their own enhancements in the imaging chain which leverage this GPU-assisted architecture that sits atop the normal ISP. They’ve outlined a few features which work atop this — HDR panorama, HDR stills, and real time object tracking. The end result is that Chimera is one part programming model and APIs for future development efforts by third parties, another part first party software that NVIDIA will distribute for integration in OEM cameras which includes the HDR features and object tracking.

Chimera allows developers to build blocks around the traditional ISP data flow and get to manipulate either bayer image data or YUV space image data on the CPU or GPU using their own framework. There are still a lot of details to come about the programming model and how this will be exploited, but there clearly is space here for NVIDIA to try and make a case for their GPU being useful for image processing. At the same time, the elephant in the room is OpenCL (and its current absence on Tegra 4) and what direction the industry will take that to leverage GPU compute for some computational photography processing.
The novel new feature of note is something I was skeptical about upon seeing at CES — single frame HDR video. The traditional route for HDR video capture is to capture at twice the framerate of the intended output video, for example for 720p30 video with a two-frame HDR, that would mean capture at 720p60 with two different exposures. What NVIDIA does is a bit different. Instead of capturing two exposures and combining them after capture, NVIDIA has found a way to drive selected CMOS sensors (both IMX135 from Sony and AR0833 from Aptina have been called out specifically, but there are more) in some special fashion, and recombine interleaved high and low exposure images (the +1 stop, –1 stop) image into one equivalent frame. This is all done on the GPU using the same Chimera pipeline blocks, but with NVIDIA’s own algorithm. The results are actually pretty impressive, NVIDIA claims 3 stops of dynamic range (~24 dB), and no recombination artifacts.

Previous demonstrations of HDR video capture on a few other platform have had halos around moving elements because of the issues associated with taking two temporally different frames and recombining them. With NVIDIA’s HDR video capture I saw no halos even on very fast moving objects, with the same quality of HDR.

NVIDIA also demonstrated their panorama capture which includes HDR as well, using a GigaPan Epic 100. Admittedly a better demo might be hand held to demonstrate how well the ISP is able to compensate for change in perspective from the tablet moving around in the hand, the resulting image was the same quality of HDR as the still however. I also saw object tracking which essentially is face tracking (and thus AE / AF assist to that subject) but taken to arbitrary subjects. Paint a box around the object you want to track, and the camera will perform feature extraction and machine learn a model around the object. Rotating around complex geometries seemed to work decently well — the model learns slowly so slow movements can be accommodated, faster moving subjects might not be object tracked.

I also got a chance to tour NVIDIA’s camera tuning labs, where they characterize smartphone CMOSes for handset markers, and work with them on tuning their ISP and imaging experience. I saw one calibration room with many different scenes, and then another room with large test charts, and two sets of standard test scenes in lightboxes. The ever-familiar GMB color checker card and ISO12233 charts were everywhere as well.








75 Comments
View All Comments
xsacha - Saturday, March 23, 2013 - link
Tegra4i uses Cortex-A9. Krait is similar to Cortex-A15. The Krait obviously uses way more power and gives way more performance clock-for-clock. So you are comparing apples and oranges here. The 1.9GHz Krait quad-core is roughly equivalent to 2.5GHz+ in a Tegra 4i.name99 - Monday, February 25, 2013 - link
"But in favor of quad-core: software might start using cores a little more effectively w/time--Google and Apple are apparently trying to make WebKit able to do things like HTML parsing and JavaScript garbage collection in the background, and Microsoft's browser team backgrounds JavaScript compilation"It would be wise to design for the technology we have today, not the dream of technology we may one day have. As I have stated elsewhere, there is ample evidence that on the desktop, even today, multiple threads running on more than two cores at once is very rare. (More precisely
- many apps are multithreaded, but those threads tend to be mostly async IO type threads, mostly waiting
- there is a mild win to having three cores available, but it's not much advantage over two cores
- the situation has improved a little over ten years ago (when the first SMT P4s first started appearing) and when there was little advantage to two cores over one. But most of the improvement is the result of OS vendors moving as much stuff as possible of what they do (GUI, IO, etc) onto the second core.)
The only real code that utilizes multiple cores is video-encoding. In particular both games and photo processing do not use nearly as much multi-core as people imagine.
The situation for mobile is the same, only a little worse because there is less of simultaneous heavyweight apps running.
Given these facts, and the way code is actually structured today, 4 cores makes very little sense.
SMT makes sense, mainly in that its power and area footprint is very low, so it's a win on those occasions when the OS can make use of it. Beyond that, if you have excess transistors available, beefed up vectors (wider registers, and wider units) probably makes more sense. You'll notice that these recommendations parallel what Intel has done over the past few years --- they are not idiots, and desktop code is very similar to mobile code.
As for parallel web browsing, people have been publishing about it for years now; but the real world results remain unimpressive. It remains an unfortunate fact that the things that have been converted to parallel don't seem to be, for most sites, the things that are actually gating performance. A similar problem exists with PDF display (still not as snappy as I would like on an iPad3) --- the simple and obvious things you can imagine for parallelizing the rendering aren't the things that are usually the problem.
In both cases, the ideal situation would be to restart with totally redesigned file formats that are non-serial in nature; but that seems to be a "boil-the-ocean" strategy that no-one wants to commit to yet. (Though it would be nice if Apple and Adobe could get together to redefine a PDF2.0 file format that was explicitly parallel, and that seems rather easier than fixing the web.)
Krysto - Sunday, February 24, 2013 - link
It seems Nvidia really pulled off making Tegra 4's GPU 6x faster than Tegra 3, and with 5 Cortex A15 cores and 6x more GPU cores, all in the same size. Pretty impressive. But still quite disappointing for lack of OpenGL ES 3.0 and OpenCL support. I really hope they plan on supporting them in Tegra 5 along with the new 64 CPU and Maxwell-based GPU cores.Mike1111 - Sunday, February 24, 2013 - link
I would really like to see an analysis/comparison of companion core (Nvidia) vs. big.LITTLE (Samsung).lmcd - Sunday, February 24, 2013 - link
BIG.little (fixed it for ARM) isn't even in reference device stage yet is it?Krysto - Monday, February 25, 2013 - link
No need to fix it. The "opposite" style naming is intentional. It's ironic. Get it?phoenix_rizzen - Monday, February 25, 2013 - link
Exynos 5 Octa, which is A15/A7 big.LITTLE, has been demoed. Tegra 4, which is A15 plus a companion core, has been demoed.Neither are commercially available, neither are in shipping products, neither are available to consumers.
IOW, the Cortex-A15 variations for bit.LITTLE have passed the reference stage, and are in the "find companies to use them to build devices" stage. They'll be in consumers' grubby little hands before Christmas 2013.
tviceman - Sunday, February 24, 2013 - link
GPU performance ended up better than I thought it would after the subdued announcement and leaked early prototype benchmarks. Good to see.wongwarren - Monday, February 25, 2013 - link
I wonder which is faster. This or the Snapdragon 600.varad - Monday, February 25, 2013 - link
Snapdragon 600:http://www.anandtech.com/show/6792/lg-optimus-g-pr...
Tegra 4:
http://www.anandtech.com/show/6787/nvidia-tegra-4-...
So if the metric is simply raw performance [since you asked "faster"], looks like the Tegra 4 will win easily against the Snapdragon 600.
A better/fair comparison would be when we have performance numbers for Snapdragon 600 in a tablet or Tegra 4 in a phone.