NVIDIA Tegra 4 Architecture Deep Dive, Plus Tegra 4i, Icera i500 & Phoenix Hands On
by Anand Lal Shimpi & Brian Klug on February 24, 2013 3:00 PM ESTIt basically goes without saying, but Tegra 4i, formerly Grey, is primarily a story about the modem. About halfway through 2011, NVIDIA acquired Icera, a player in the handset cellular baseband market who had managed to fit a software-defined radio into the power budget for a mobile device. NVIDIA clearly recognized the importance of being able to deliver an SoC with an integrated modem, and after the Icera acquisition, and later Grey’s appearance on the roadmap, it just became a matter of when that would happen. NVIDIA executed pretty quickly, it turns out, and the fruits of that work manifest themselves in two products — Icera’s standalone i500 and Tegra 4i which contains the same i500 IP block, minus USB interfaces and a different memory subsystem.

Icera was an interesting player in the baseband space because their architecture was that of a software defined radio on the digital baseband side. The reality is that nobody is either fully software defined or burned out to ASIC (hardware), but rather somewhere inbetween. For example, Qualcomm is a combination of software and hardware, though it’s never been entirely clear what functional blocks are ASIC and which other blocks are software, though I’ve been told this is often a matter of whatever is most advantageous for power and what gets re-used most. That said, Icera’s implementation is the furthest towards being pure software defined of anyone, with the entire digital baseband being just one big platform to run their own software atop. There’s an external transceiver which does downconversion, but after that it’s pure software. The question has always been how Icera could afford to build a power competitive platform with an entirely software designed stack, and the clue lies in their choice of 28 HPM instead of LP or HPL silicon for i500 and 4i. Icera designs to a high performance process, then turns off blocks when they’re not in use, rather than make a larger SoC that’s lower leakage. The result is that NVIDIA claims a 40% smaller die for i500 than MDM9x15.
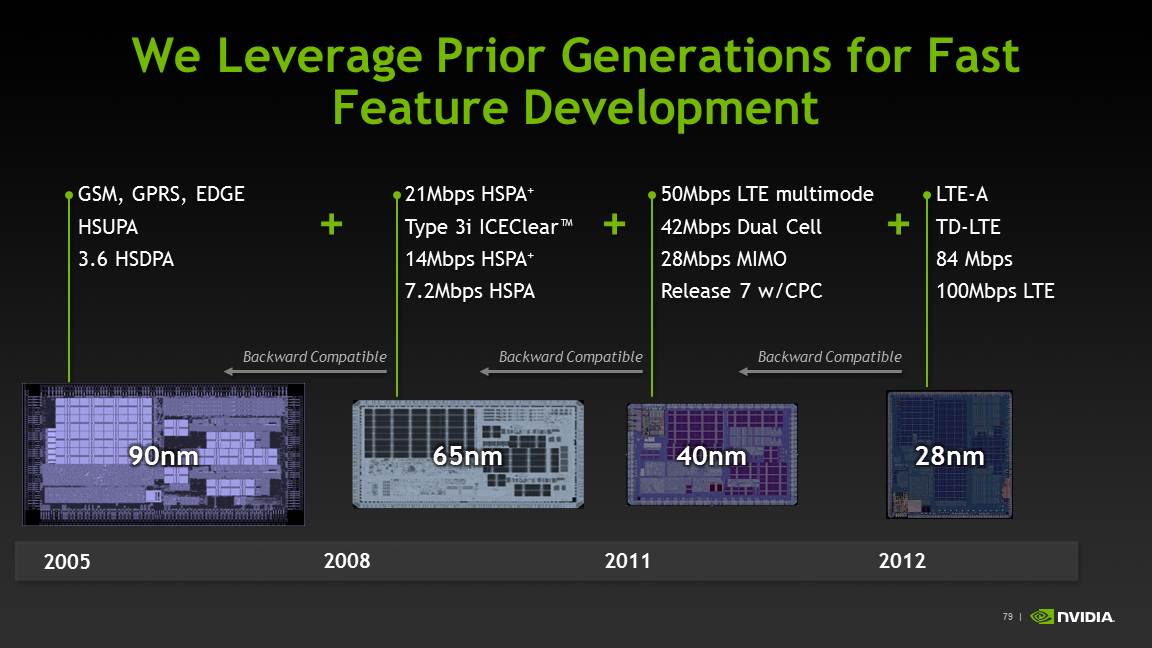
Icera has maintained the same software platform across its modem portfolio, each time taking advantage of increased processing performance afforded by faster silicon to include more air interfaces and capabilities. The result is an interesting advantage when it comes to operator certification — they can make a compelling case for each new version being close to the previous one, since they run the same PHY and protocol stack entirely in software.

In the case of i500, it runs the exact same multimode modem software as the i4xx series, just with increased DXP support for 15 and 20 MHz channel bandwidths on LTE.
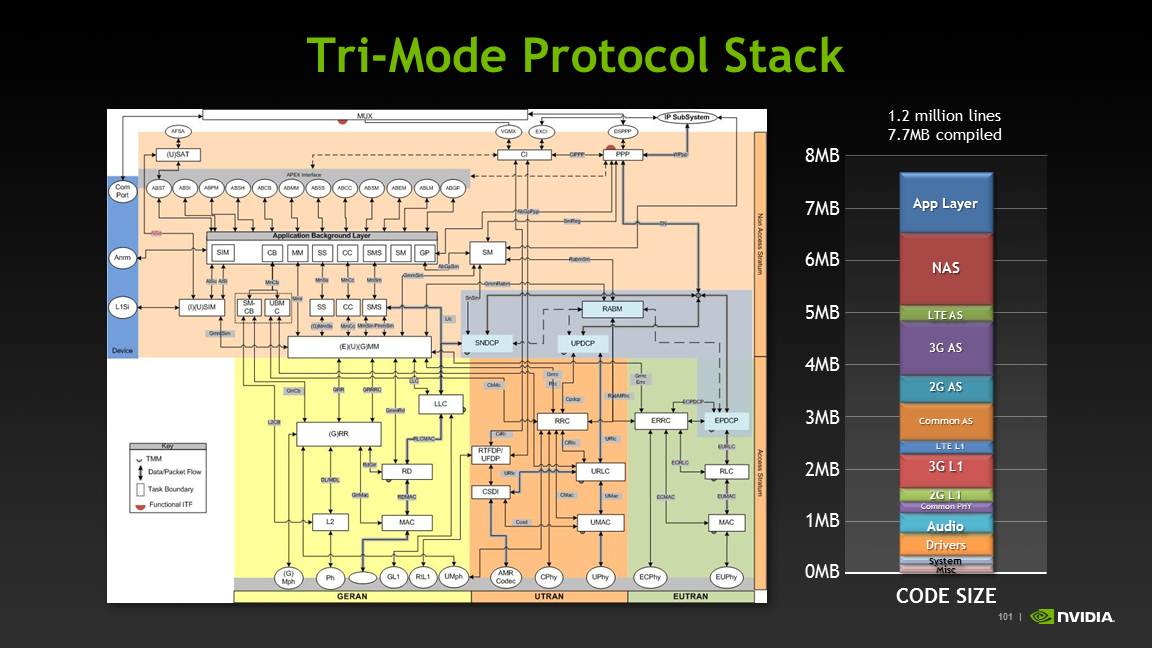
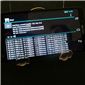
The entire stack ends up being 1.2 million lines of C and DXP code, with a total size of 7.7 MB compiled. NVIDIA gave a great breakdown of the protocol stack as well.

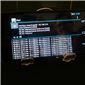
The real name for Icera i500 is ICE9045, and it is paired with a ICE9245 transceiver. ICE9045 is built on 28nm HPM as I mentioned before, and ICE9245 remains 65nm TSMC LP CMOS process which is RF friendly. ICE9045 supports basically all the 3GPP air interfaces, as mentioned in the earlier announcement piece. There’s up to Category 3 LTE on the baseband at launch, with Category 4 in the future. For WCDMA, up to Category 24 (42 Mbps) (dual carrier with 64QAM), and interestingly enough the same Category 18 16 QAM with 2x2 MIMO (28 Mbps) as earlier implemented in Icera 450, and an optional future upgrade to Category 28 64 QAM with 2x2 MIMO (84 Mbps). Of course there’s also TD-SCDMA, GSM/EDGE, full support for voice including AMR-WB and VoLTE/IMS. In addition to 2x2 MIMO the ICE9045 can also do 4x4 MIMO on LTE with a second ICE9245 transceiver.

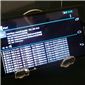
NVIDIA broke down the ICE9045 functionally, which consists of two large DXP units and one smaller DXP unit which runs the rest of the software and management stack. The two larger DXP units run at up to 1.3 GHz. The Icera instruction set consists of two different fundamental sets. Icera refers to these as the “C” and “D” side, with C being rather obvious. The C side is unsurprisingly a C-complier targeted version of the 3GPP protocol stack, and manages the higher level functions of the modem above physical interface, and is a scalar machine. In the block diagram, the C side runs on DXP1, the D side runs on the larger beefier DXP0 and DXP2 machines.

The D side is a proprietary assembly language vector instruction set that runs the physical layer of the modem, this is a combination of specific libraries that really make up the magic and give the Icera platform its reconfigurability. NVIDIA gave an excellent breakdown of the data paths inside both sides. It turns out that in an LTE configuration one core does all the inverse FFTs and MIMO matrix math, the second core does rate matching and decoding. The ultimate goal is to have each of the cores processing around the same equal workload, and since it’s software these tasks can be shuffled in-between to get the i500 running each core at the lowest possible frequency and voltage. Each of the cores can also be individually power collapsed.

On the transceiver side we have ICE9245 which is again TSMC 65nm LP CMOS. This talks over a digital interface to the baseband, and increases the number of primary RX ports from 6 to 8. All filtering and channelization is onboard the ISP. The goal is to keep all the A2D and D2A on the transceiver and away from the baseband. NVIDIA hasn’t quite given me the frequency breakdown for their low band, high band, and super high band, but you can figure it out just by looking. There’s also diversity ports for the same set of bands. All these ports are created equal and can handle 20 MHz LTE, in addition to inter-band and intra-band CA.
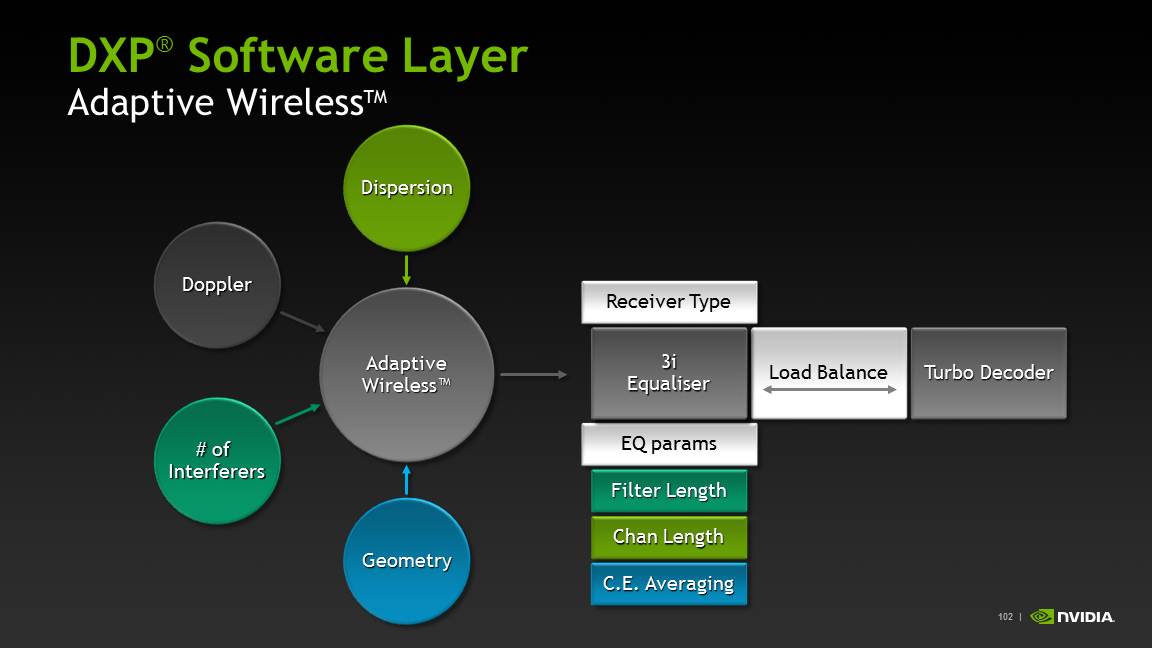
The big question is how well Icera’s i500 will stack up against the MDM9x15s and MDM9x25s of the world. Icera believes its ability to switch between four fundamentally different receiver types on the fly and dedicate processing to different functions based on the cellular geometry at the moment offers it an advantage in the long run.
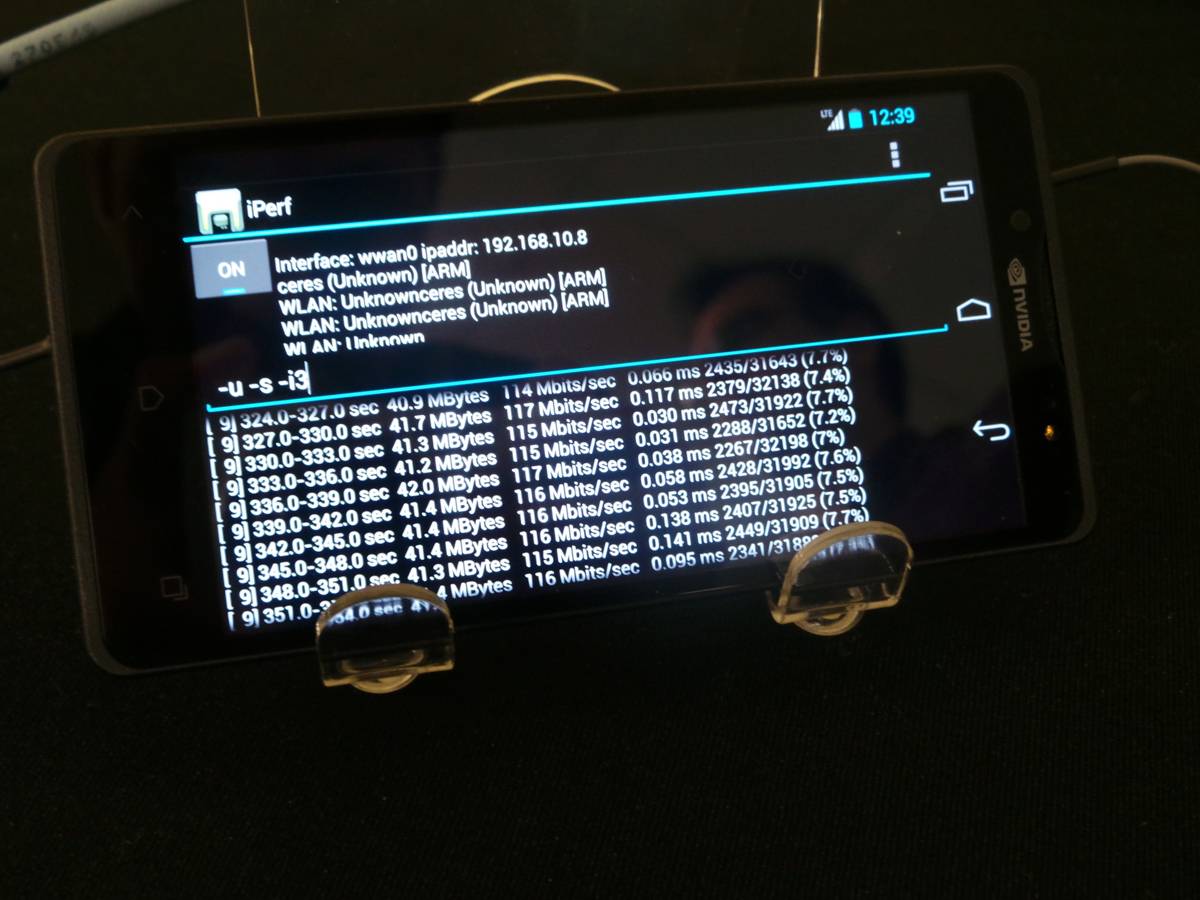
NVIDIA demonstrated a Phoenix with Tegra 4i cabled up to a base station emulator doing full Category 3 LTE at 100 Mbps nice and steady. I asked whether they could go any higher to demonstrate the headroom in the current i500 architecture for upgrading to Category 4 and was shown just short of 120 Mbps on the two week old Tegra 4i silicon.










75 Comments
View All Comments
xsacha - Saturday, March 23, 2013 - link
Tegra4i uses Cortex-A9. Krait is similar to Cortex-A15. The Krait obviously uses way more power and gives way more performance clock-for-clock. So you are comparing apples and oranges here. The 1.9GHz Krait quad-core is roughly equivalent to 2.5GHz+ in a Tegra 4i.name99 - Monday, February 25, 2013 - link
"But in favor of quad-core: software might start using cores a little more effectively w/time--Google and Apple are apparently trying to make WebKit able to do things like HTML parsing and JavaScript garbage collection in the background, and Microsoft's browser team backgrounds JavaScript compilation"It would be wise to design for the technology we have today, not the dream of technology we may one day have. As I have stated elsewhere, there is ample evidence that on the desktop, even today, multiple threads running on more than two cores at once is very rare. (More precisely
- many apps are multithreaded, but those threads tend to be mostly async IO type threads, mostly waiting
- there is a mild win to having three cores available, but it's not much advantage over two cores
- the situation has improved a little over ten years ago (when the first SMT P4s first started appearing) and when there was little advantage to two cores over one. But most of the improvement is the result of OS vendors moving as much stuff as possible of what they do (GUI, IO, etc) onto the second core.)
The only real code that utilizes multiple cores is video-encoding. In particular both games and photo processing do not use nearly as much multi-core as people imagine.
The situation for mobile is the same, only a little worse because there is less of simultaneous heavyweight apps running.
Given these facts, and the way code is actually structured today, 4 cores makes very little sense.
SMT makes sense, mainly in that its power and area footprint is very low, so it's a win on those occasions when the OS can make use of it. Beyond that, if you have excess transistors available, beefed up vectors (wider registers, and wider units) probably makes more sense. You'll notice that these recommendations parallel what Intel has done over the past few years --- they are not idiots, and desktop code is very similar to mobile code.
As for parallel web browsing, people have been publishing about it for years now; but the real world results remain unimpressive. It remains an unfortunate fact that the things that have been converted to parallel don't seem to be, for most sites, the things that are actually gating performance. A similar problem exists with PDF display (still not as snappy as I would like on an iPad3) --- the simple and obvious things you can imagine for parallelizing the rendering aren't the things that are usually the problem.
In both cases, the ideal situation would be to restart with totally redesigned file formats that are non-serial in nature; but that seems to be a "boil-the-ocean" strategy that no-one wants to commit to yet. (Though it would be nice if Apple and Adobe could get together to redefine a PDF2.0 file format that was explicitly parallel, and that seems rather easier than fixing the web.)
Krysto - Sunday, February 24, 2013 - link
It seems Nvidia really pulled off making Tegra 4's GPU 6x faster than Tegra 3, and with 5 Cortex A15 cores and 6x more GPU cores, all in the same size. Pretty impressive. But still quite disappointing for lack of OpenGL ES 3.0 and OpenCL support. I really hope they plan on supporting them in Tegra 5 along with the new 64 CPU and Maxwell-based GPU cores.Mike1111 - Sunday, February 24, 2013 - link
I would really like to see an analysis/comparison of companion core (Nvidia) vs. big.LITTLE (Samsung).lmcd - Sunday, February 24, 2013 - link
BIG.little (fixed it for ARM) isn't even in reference device stage yet is it?Krysto - Monday, February 25, 2013 - link
No need to fix it. The "opposite" style naming is intentional. It's ironic. Get it?phoenix_rizzen - Monday, February 25, 2013 - link
Exynos 5 Octa, which is A15/A7 big.LITTLE, has been demoed. Tegra 4, which is A15 plus a companion core, has been demoed.Neither are commercially available, neither are in shipping products, neither are available to consumers.
IOW, the Cortex-A15 variations for bit.LITTLE have passed the reference stage, and are in the "find companies to use them to build devices" stage. They'll be in consumers' grubby little hands before Christmas 2013.
tviceman - Sunday, February 24, 2013 - link
GPU performance ended up better than I thought it would after the subdued announcement and leaked early prototype benchmarks. Good to see.wongwarren - Monday, February 25, 2013 - link
I wonder which is faster. This or the Snapdragon 600.varad - Monday, February 25, 2013 - link
Snapdragon 600:http://www.anandtech.com/show/6792/lg-optimus-g-pr...
Tegra 4:
http://www.anandtech.com/show/6787/nvidia-tegra-4-...
So if the metric is simply raw performance [since you asked "faster"], looks like the Tegra 4 will win easily against the Snapdragon 600.
A better/fair comparison would be when we have performance numbers for Snapdragon 600 in a tablet or Tegra 4 in a phone.