NVIDIA Tegra 4 Architecture Deep Dive, Plus Tegra 4i, Icera i500 & Phoenix Hands On
by Anand Lal Shimpi & Brian Klug on February 24, 2013 3:00 PM ESTThe GPU
Tegra 4 features an evolved GPU core compared to Tegra 3. The architecture retains a fixed division between pixel and vertex shader hardware, making it the only modern mobile GPU architecture not to adopt a unified shader model.


I already described a lot of what makes the Tegra 4 GPU different in our original article on the topic. The diagram below gives you an idea of how the pixel and vertex shader hardware grew over the past 3 generations:
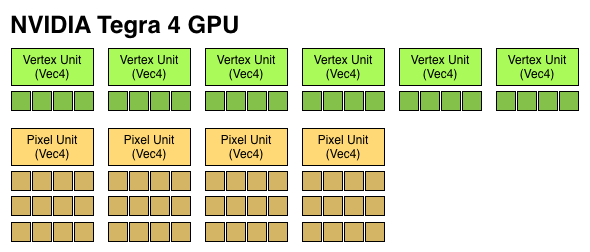
We finally have a competitive GPU architecture from NVIDIA. It’s hardly industry leading in terms of specs, but there’s a good amount of the 80mm^2 die dedicated towards pixel and vertex shading hardware. There's also a new L2 texture cache that helps improve overall bandwidth efficiency.

The big omission here is the lack of full OpenGL ES 3.0 support. NVIDIA’s pixel shader hardware remains FP24, while the ES 3.0 spec requires full FP32 support for both pixel and vertex shaders. NVIDIA also lacks ETC and FP texture support, although some features of ES 3.0 are implemented (e.g. Multiple Render Targets).
| Mobile SoC GPU Comparison | |||||||||||||||
| GeForce ULP (2012) | PowerVR SGX 543MP2 | PowerVR SGX 543MP4 | PowerVR SGX 544MP3 | PowerVR SGX 554MP4 | GeForce ULP (2013) | ||||||||||
| Used In | Tegra 3 | A5 | A5X | Exynos 5 Octa | A6X | Tegra 4 | |||||||||
| SIMD Name | core | USSE2 | USSE2 | USSE2 | USSE2 | core | |||||||||
| # of SIMDs | 3 | 8 | 16 | 12 | 32 | 18 | |||||||||
| MADs per SIMD | 4 | 4 | 4 | 4 | 4 | 4 | |||||||||
| Total MADs | 12 | 32 | 64 | 48 | 128 | 72 | |||||||||
| GFLOPS @ Shipping Frequency | 12.4 GFLOPS | 16.0 GFLOPS | 32.0 GFLOPS | 51.1 GFLOPS | 71.6 GFLOPS | 74.8 GFLOPS | |||||||||
For users today, the lack of OpenGL ES 3.0 support likely doesn’t matter - but it’ll matter more in a year or two when game developers start using OpenGL ES 3.0. NVIDIA is fully capable of building an OpenGL ES 3.0 enabled GPU, and I suspect the resistance here boils down to wanting to win performance comparisons today without making die size any larger than it needs to be. Remembering back to the earlier discussion about NVIDIA’s cost position in the market, this decision makes sense from NVIDIA’s stance although it’s not great for the industry as a whole.
Tegra 4i retains the same base GPU architecture as Tegra 4, but dramatically cuts down on hardware. NVIDIA goes from 4 down to 3 vertex units, and moves to two larger pixel shader units (increasing the ratio of compute to texture hardware in the T4i GPU). The max T4i GPU clock drops a bit down to 660MHz, but that still gives it substantially more performance than NVIDIA’s Tegra 3.
Memory Interface
The first three generations of Tegra SoCs had an embarrassingly small amount of memory bandwidth, at least compared to Apple, Samsung and Qualcomm. Admittedly, Samsung and Qualcomm were late adopters of a dual-channel memory interface, but they still got there much quicker than NVIDIA did.
With Tegra 4, complaints about memory bandwidth can finally be thrown out the window. The Tegra 4 SoC features two 32-bit LPDDR3 memory interfaces, bringing it up to par with the competition. The current max data rate supported by Tegra 4’s memory interfaces is 1866MHz, but that may go up in the future.
Tegra 4 won’t ship in a PoP (package-on-package) configuration and will have to be paired with external DRAM. This will limit Tegra 4 to larger devices, but it should still be able to fit in a phone.
Unfortunately, Tegra 4i only has a single channel LPDDR3 memory interface. Tegra 4i on the other hand will be available in PoP as well as discrete configurations. The PoP configuration may top out at LPDDR3-1600, while the discrete version can scale up to 1866MHz and beyond.








75 Comments
View All Comments
xsacha - Saturday, March 23, 2013 - link
Tegra4i uses Cortex-A9. Krait is similar to Cortex-A15. The Krait obviously uses way more power and gives way more performance clock-for-clock. So you are comparing apples and oranges here. The 1.9GHz Krait quad-core is roughly equivalent to 2.5GHz+ in a Tegra 4i.name99 - Monday, February 25, 2013 - link
"But in favor of quad-core: software might start using cores a little more effectively w/time--Google and Apple are apparently trying to make WebKit able to do things like HTML parsing and JavaScript garbage collection in the background, and Microsoft's browser team backgrounds JavaScript compilation"It would be wise to design for the technology we have today, not the dream of technology we may one day have. As I have stated elsewhere, there is ample evidence that on the desktop, even today, multiple threads running on more than two cores at once is very rare. (More precisely
- many apps are multithreaded, but those threads tend to be mostly async IO type threads, mostly waiting
- there is a mild win to having three cores available, but it's not much advantage over two cores
- the situation has improved a little over ten years ago (when the first SMT P4s first started appearing) and when there was little advantage to two cores over one. But most of the improvement is the result of OS vendors moving as much stuff as possible of what they do (GUI, IO, etc) onto the second core.)
The only real code that utilizes multiple cores is video-encoding. In particular both games and photo processing do not use nearly as much multi-core as people imagine.
The situation for mobile is the same, only a little worse because there is less of simultaneous heavyweight apps running.
Given these facts, and the way code is actually structured today, 4 cores makes very little sense.
SMT makes sense, mainly in that its power and area footprint is very low, so it's a win on those occasions when the OS can make use of it. Beyond that, if you have excess transistors available, beefed up vectors (wider registers, and wider units) probably makes more sense. You'll notice that these recommendations parallel what Intel has done over the past few years --- they are not idiots, and desktop code is very similar to mobile code.
As for parallel web browsing, people have been publishing about it for years now; but the real world results remain unimpressive. It remains an unfortunate fact that the things that have been converted to parallel don't seem to be, for most sites, the things that are actually gating performance. A similar problem exists with PDF display (still not as snappy as I would like on an iPad3) --- the simple and obvious things you can imagine for parallelizing the rendering aren't the things that are usually the problem.
In both cases, the ideal situation would be to restart with totally redesigned file formats that are non-serial in nature; but that seems to be a "boil-the-ocean" strategy that no-one wants to commit to yet. (Though it would be nice if Apple and Adobe could get together to redefine a PDF2.0 file format that was explicitly parallel, and that seems rather easier than fixing the web.)
Krysto - Sunday, February 24, 2013 - link
It seems Nvidia really pulled off making Tegra 4's GPU 6x faster than Tegra 3, and with 5 Cortex A15 cores and 6x more GPU cores, all in the same size. Pretty impressive. But still quite disappointing for lack of OpenGL ES 3.0 and OpenCL support. I really hope they plan on supporting them in Tegra 5 along with the new 64 CPU and Maxwell-based GPU cores.Mike1111 - Sunday, February 24, 2013 - link
I would really like to see an analysis/comparison of companion core (Nvidia) vs. big.LITTLE (Samsung).lmcd - Sunday, February 24, 2013 - link
BIG.little (fixed it for ARM) isn't even in reference device stage yet is it?Krysto - Monday, February 25, 2013 - link
No need to fix it. The "opposite" style naming is intentional. It's ironic. Get it?phoenix_rizzen - Monday, February 25, 2013 - link
Exynos 5 Octa, which is A15/A7 big.LITTLE, has been demoed. Tegra 4, which is A15 plus a companion core, has been demoed.Neither are commercially available, neither are in shipping products, neither are available to consumers.
IOW, the Cortex-A15 variations for bit.LITTLE have passed the reference stage, and are in the "find companies to use them to build devices" stage. They'll be in consumers' grubby little hands before Christmas 2013.
tviceman - Sunday, February 24, 2013 - link
GPU performance ended up better than I thought it would after the subdued announcement and leaked early prototype benchmarks. Good to see.wongwarren - Monday, February 25, 2013 - link
I wonder which is faster. This or the Snapdragon 600.varad - Monday, February 25, 2013 - link
Snapdragon 600:http://www.anandtech.com/show/6792/lg-optimus-g-pr...
Tegra 4:
http://www.anandtech.com/show/6787/nvidia-tegra-4-...
So if the metric is simply raw performance [since you asked "faster"], looks like the Tegra 4 will win easily against the Snapdragon 600.
A better/fair comparison would be when we have performance numbers for Snapdragon 600 in a tablet or Tegra 4 in a phone.