Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
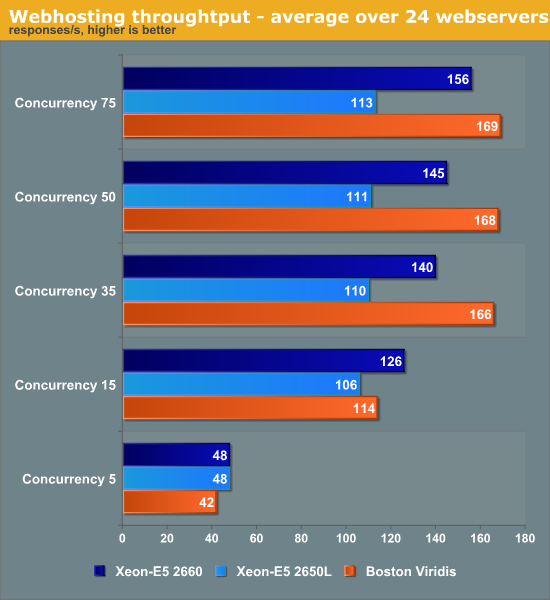
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
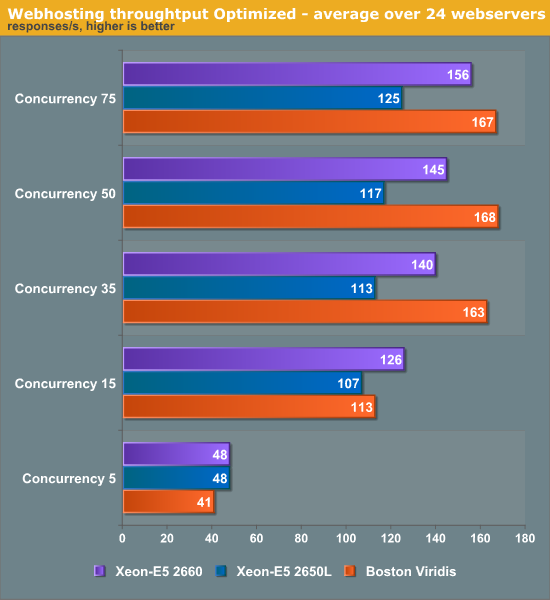
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
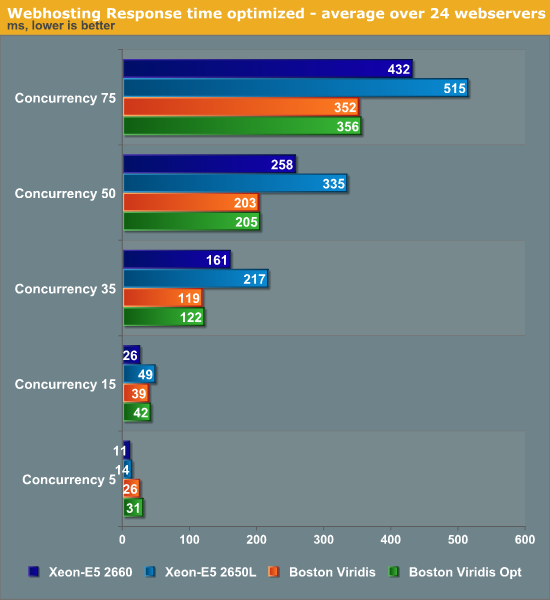
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.








99 Comments
View All Comments
JohanAnandtech - Wednesday, March 13, 2013 - link
Hmmm ... There is almost no info on how that hypervisor works. It is hard to imagine that kind of system would scale very well. How does it keep Cache coherent? Do you have info on that?timbuktu - Wednesday, March 13, 2013 - link
I can't speak directly to ScaleMP, but it looks similar to NUMALink.http://en.wikipedia.org/wiki/NUMAlink
Reading through this article about Calxedas, great job BTW, I couldn't help but think about the old SGI hardware that seemed pretty similar with MIPs (and later Itanium) processors connected through a switch with NUMALink. I haven't played with NUMALink directly in almost a decade, but back then cheaper Altix slabs were ring topology while higher end hardware was switched. In the end though, you could put together a bunch of 1U racks together and have a single system image. Like you mentioned though, cache coherency was exceptionally important. Since we have a uv here, I can point you to the documentation for that box.
http://techpubs.sgi.com/library/tpl/cgi-bin/getdoc...
Everything old is new again, I suppose. Well, except NUMAlink never went away. =D
Tunrip - Wednesday, March 13, 2013 - link
I'd be interested in knowing how the Xeon compared if you did the same test without the virtual machines.JohanAnandtech - Wednesday, March 13, 2013 - link
The website won't scale to 32 logical cores I am afraid... but we can try to see how far we can getColin1497 - Wednesday, March 13, 2013 - link
A better question might be "is 24 VM's a logical number to use?" Would more or fewer VM's work better? The appearance is that you have 24VM's because you have 24 ARM nodes?duploxxx - Wednesday, March 13, 2013 - link
very interesting, loved reading it. But although early in the ball game I do think there are other way better solutions in the pipe-line from the big OEM:HP Moonshot
http://h17007.www1.hp.com/us/en/iss/110111.aspx
JohanAnandtech - Wednesday, March 13, 2013 - link
Isn't remarkable how PR people manage to fill so many pages with "extreme" and "the future" without telling anything. Frustation became even higher when I clicked "get the facts" page. That is more like "You are not getting any facts at all".DuckieHo - Wednesday, March 13, 2013 - link
Since these are set up as webservers, what's the power consumption at say 20-40% load? Usually there is some load instead of completely idle.JohanAnandtech - Wednesday, March 13, 2013 - link
Good suggestion... you'll like to see a step by step power measurement like SpecPower right? Let me try that.DanNeely - Wednesday, March 13, 2013 - link
I'd be interested in seeing where, and what happens when you start pushing single chips to and slightly beyond their limits. Calxeda's hardware's proved competitive on a very friendly workload (which I didn't really expect would happen until their A15 product); but in the real world a set of small websites are unlikely to all have equal load levels. Virtual servers on larger CPUs should give more headroom for load spikes; so knowing what the limits on Calxeda's hardware are strikes me as fairly important.