Plextor M5M (256GB) mSATA Review
by Kristian Vättö on April 17, 2013 10:20 AM ESTPerformance Consistency
In our Intel SSD DC S3700 review Anand introduced a new method of characterizing performance: looking at the latency of individual operations over time. The S3700 promised a level of performance consistency that was unmatched in the industry, and as a result needed some additional testing to show that. The reason we don't have consistent IO latency with SSDs is because inevitably all controllers have to do some amount of defragmentation or garbage collection in order to continue operating at high speeds. When and how an SSD decides to run its defrag and cleanup routines directly impacts the user experience. Frequent (borderline aggressive) cleanup generally results in more stable performance, while delaying that can result in higher peak performance at the expense of much lower worst case performance. The graphs below tell us a lot about the architecture of these SSDs and how they handle internal defragmentation.
To generate the data below I took a freshly secure erased SSD and filled it with sequential data. This ensures that all user accessible LBAs have data associated with them. Next I kicked off a 4KB random write workload across all LBAs at a queue depth of 32 using incompressible data. I ran the test for just over half an hour, no where near what we run our steady state tests for but enough to give me a good look at drive behavior once all spare area filled up.
I recorded instantaneous IOPS every second for the duration of the test. I then plotted IOPS vs. time and generated the scatter plots below. Each set of graphs features the same scale. The first two sets use a log scale for easy comparison, while the last set of graphs uses a linear scale that tops out at 40K IOPS for better visualization of differences between drives.
The high level testing methodology remains unchanged from our S3700 review. Unlike in previous reviews however, I did vary the percentage of the drive that I filled/tested depending on the amount of spare area I was trying to simulate. The buttons are labeled with the advertised user capacity had the SSD vendor decided to use that specific amount of spare area. If you want to replicate this on your own all you need to do is create a partition smaller than the total capacity of the drive and leave the remaining space unused to simulate a larger amount of spare area. The partitioning step isn't absolutely necessary in every case but it's an easy way to make sure you never exceed your allocated spare area. It's a good idea to do this from the start (e.g. secure erase, partition, then install Windows), but if you are working backwards you can always create the spare area partition, format it to TRIM it, then delete the partition. Finally, this method of creating spare area works on the drives we've tested here but not all controllers may behave the same way.
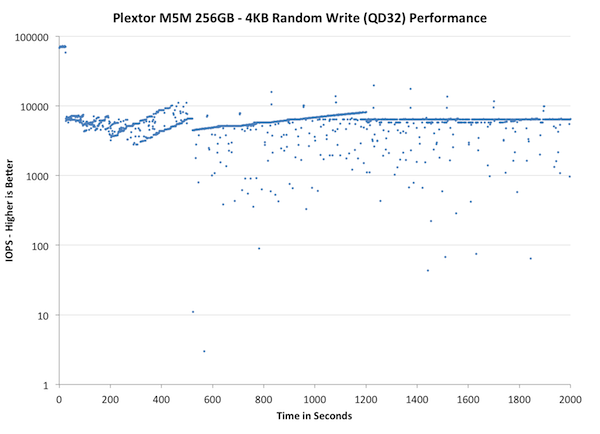
The first set of graphs shows the performance data over the entire 2000 second test period. In these charts you'll notice an early period of very high performance followed by a sharp dropoff. What you're seeing in that case is the drive alllocating new blocks from its spare area, then eventually using up all free blocks and having to perform a read-modify-write for all subsequent writes (write amplification goes up, performance goes down).
The second set of graphs zooms in to the beginning of steady state operation for the drive (t=1400s). The third set also looks at the beginning of steady state operation but on a linear performance scale. Click the buttons below each graph to switch source data.
| Impact of Spare Area | ||||||||
| Plextor M5M 256GB | Plextor M5 Pro 256GB | Intel SSD 525 240GB | Corsair Neutron 240GB | OCZ Vector 256GB | Samsung SSD 840 Pro 256GB | |||
| Default | ||||||||
| 25% Spare Area | - | |||||||
The M5M does a lot better than the M5 Pro but its consistency is still slightly behind OCZ Vector and Samsung SSD 840 Pro. I believe the reason why M5M's graph looks so different is Plextor's garbage collection method. Vector and SSD 840 are doing a lot more active garbage collection, which means they are constantly cleaning blocks and rearranging data. That's why their performance is constantly varying: At one second you're pushing data at 20K IOPS, the next at 5K IOPS and on the third you're back to 20K IOPS.
Plextor's approach is different, their garbage collection isn't triggered until it's an absolute must (or the drive is idling). In this case, after 500 seconds of 4KB random writes, there are no empty blocks left and the firmware must do garbage collection before it can process the next write request. The result? Performance drops to below 100 IOPS. This is the problem with the "clean up later" approach. As you'll soon see in the steady state graphs below, the drive completely stops (zero IOPS) every now and then. The drive is simply in such a dirty state that it must spend possibly seconds doing garbage collection before it can process the next IO. Sure, the IO may then transfer at 10K IOPS but you've already noticed the hiccup when the drive was doing GC.
This can actually be applied to real world very easily. Imagine that you're doing the dishes the old fashioned way (i.e. by hand). If you do the dishes after every meal, you'll have to do the dishes more often but you'll only spend a little time doing them at a time. If you do the dishes once a day, it will take you a longer time to get them all done. The total time spend doing dishes will most likely be around the same, but doing them all at once will stop you from doing other activities for a longer period of time. If a friend calls and asks you out, you can't go because you have a pile of dishes to do, or you may be able to go but it will take you a while. Had you done the dishes after every meal, you would have been free to go. In this analogy, doing the dishes is obviously garbage collection and going out is a write request from the host.
There's no clear ruling about which is better, active or idle garbage collection, but we have always preferred the active (though not too aggressive) method. The peak performance may be lower but consistency is a lot higher because you won't have sudden drops in the IOPS.
One quick note about the M5 Pro before we go forward. I asked Plextor about the IO consistency in the M5 Pro after our review of the new 1.02 firmware went live. A few weeks ago Plextor got back to me and told that the 1.02 firmware has a bug that causes the consistency to be as horrible as it is. However, this is only in the old M5 Pro (not in the new Xtreme with slightly different PCB and NAND) and they are working on a new firmware to fix the issue. I should have the new Xtreme here in the next few days so I can test and see if the issue only exists in the old M5 Pro. The M5M definitely doesn't suffer from this issue, although its IO consistency has room for improvement.
Lets move on to steady state performance, shall we?
| Impact of Spare Area | ||||||||
| Plextor M5M 256GB | Plextor M5 Pro 256GB | Intel SSD 525 240GB | Corsair Neutron 240GB | OCZ Vector 256GB | Samsung SSD 840 Pro 256GB | |||
| Default | ||||||||
| 25% Spare Area | - | |||||||
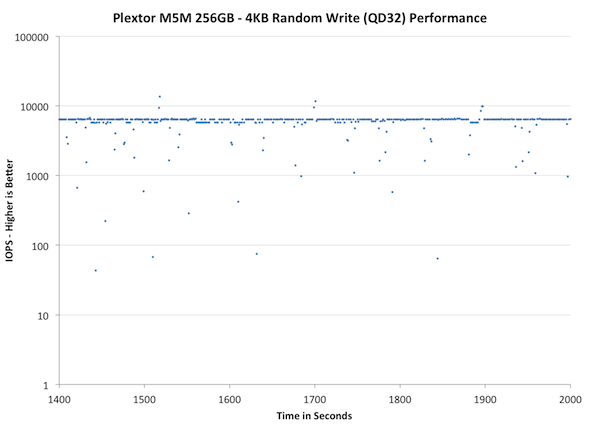
The impact of "clean up later" is even easier to see during steady state. Most of the other SSDs vary between 1K and 10K IOPS but the M5M dips below 100 IOPS every now and then. The majority of IOs are transferring at about 7K IOPS, which is pretty good, but the drops will still affect the performance. The non-logarithmic graph below will do an even better job at showing this:
| Impact of Spare Area | ||||||||
| Plextor M5M 256GB | Plextor M5 Pro 256GB | Intel SSD 525 240GB | Corsair Neutron 240GB | OCZ Vector 256GB | Samsung SSD 840 Pro 256GB | |||
| Default | ||||||||
| 25% Spare Area | - | |||||||
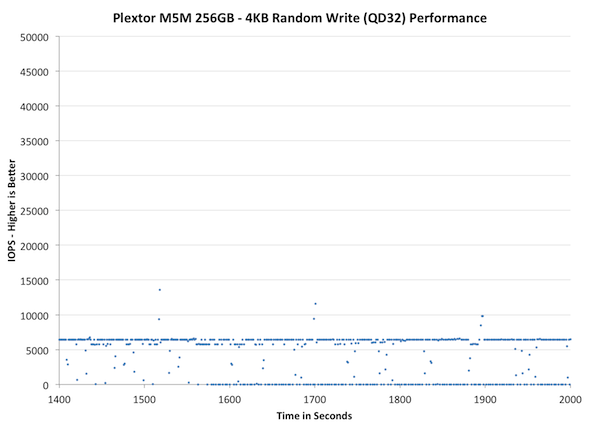
Now, what you're seeing are two main lines: One at ~7K IOPS and the other at 0 IOPS. This really shows how bad the situation can be if you don't clean up the mess from early on. About every third second the M5M completely stops to do garbage collection. It's unlikely for consumers to put the SSDs in a state similar to ours but we still shouldn't see SSDs completely stopping anymore. It was an issue a few years ago and back then it was somewhat acceptable given the immaturity of consumer SSDs; today it should not exist.
Fortunately, giving the M5M 25% over-provisioning helps a lot. It's still not as good as for example OCZ Vector or Corsair Neutron GTX, but the minimum IOPS is now over 20K (no more sudden 0 IOPS drops). You can still see the impact of the "clean up later" approach but the drop is only 5K IOPS, which shouldn't be very noticeable. I strongly recommend having at least 25% free space with the M5M. The more you fill the drive, the more likely it is that you'll face inconsistent performance.








36 Comments
View All Comments
JPForums - Thursday, April 18, 2013 - link
Sorry, I wasn't trying to bait you. The posts just came off as a little hostile. Probably a result of the my morning meetings.If I'm understanding you correctly, your biggest issue is with the method of consistency. I read in another of your posts that this method is similar to the tests that several large enterprises use. You seem to be familiar with these methods. Is there an alternate (better) method in use that Anandtech could be using? Alternately do you have a superior method in mind that isn't currently in use? I'm guessing (for starters) you'd be happier with a method that measures individual operation latencies (I would too), but I'm unaware any tools that could accomplish this.
JellyRoll - Thursday, April 18, 2013 - link
The consistency testing and all trace based testing used by this site are tested without partitions or filesystems, and no TRIM functionality. This has been disclosed by the staff in the comment sections of previous reviews.If you are testing consumer hardware, the first order of the day is to use methods that accurately reflect real workloads. Removing the must crucial component required for performance consistency (TRIM), then testing 'consistency' anyway, is ridiculous. Would you test a vehicle without fuel?
Kristian Vättö - Thursday, April 18, 2013 - link
TRIM does not affect performance consistency of a continuous write workload. TRIM will only tell the controller which LBAs are no longer in use - the actual LBAs still need to be erased before new data can be written. When you're constantly writing to the drive, it doesn't have time to erase the blocks as fast as new write requests come in, which causes the performance to sink.If you know methods that "accurately reflect real workloads" then please share them. Pointing out flaws is easy but unhelpful unless you can provide a method that's better.
JellyRoll - Thursday, April 18, 2013 - link
Pasted from the Wiki:"The TRIM command is designed to enable the operating system to notify the SSD which pages no longer contain valid data due to erases either by the user or operating system itself. During a delete operation, the OS will both mark the sectors as free for new data and send a TRIM command to the SSD to be marked as no longer valid. After that the SSD knows not to relocate data from the affected LBAs during garbage collection."
During a pure write workload there is no need for the SSD's internal garbage collection functions to read-write-modify in order to write new data. That is the purpose of TRIM. Without TRIM writes require read-write-modify activity, with TRIM they do not. Very easy to see how it boosts performance.
Kristian Vättö - Thursday, April 18, 2013 - link
You still have to erase the blocks, which is the time consuming part. Again, there's no time for normal idle garbage collection to kick in. Yes, the drive will know what LBAs are no longer in use but it still has to erase the blocks containing those LBAs. If you let the drive idle, then it will have time to reorganize the data so that there'll be enough empty blocks to maintain good performance but that is not the case in a continuous write workload.JellyRoll - Thursday, April 18, 2013 - link
It is removing the 'write' from the read-write-modify cycle. Writing a page smaller than the block requires the SSD to relocate the other data in the block first, adding work for the SSD. Remember, they erase at block level. If it isn't aware that the rest of the block is also invalid (the point of TRIM) it must first move the other data.Kristian Vättö - Thursday, April 18, 2013 - link
It's read-modify-write cycle (read the block to cache, modify the data, write the modified data) so the write operation is still there, otherwise the drive wouldn't complete the write request in the first place. You also seem to be assuming that the rest of the pages in the block are invalid, which is unlikely the case unless we're dealing with an empty drive. Hence it's exactly the same cycle with TRIM as you still have to read at least some of the data and then rewrite it. You may have to read/write less data as some of it will be invalid, but remember that garbage collection (with TRIM off) will also mark pages as invalid on its own. That's the reason why performance will stay high even if TRIM is not supported (e.g. OS X), assuming that the garbage collection is effective (there's at least 7% OP so there is always invalid pages).JellyRoll - Thursday, April 18, 2013 - link
I am not assuming the data is still valid, the SSD does. It has to move the data if it considers it valid. TRIM removes the need to move this 'other' data, thus speeding the drive.Kristian Vättö - Monday, April 22, 2013 - link
Here are some tests I did with Plextor M5 Pro XtremeRAW (no partition): https://dl.dropboxusercontent.com/u/128928769/Cons...
NTFS (default cluster size): https://dl.dropboxusercontent.com/u/128928769/Cons...
As you can see, there's no major difference. In fact, there's a bigger slowdown with NTFS versus raw drive.
JPForums - Thursday, April 18, 2013 - link
1) I was not aware that another website created this method of characterizing performance, but I'll give you the benefit of the doubt. Nonetheless, the statement that Anand introduced it to the standard test suite here at Anandtech in the Intel SSD DC S3700 review is a true statement. Given the context of the original statement, this is more likely the intended interpretation. Out of curiosity, which site did create the method?2) I'm not sure whether or not the test measures individual operation latencies or not as IOPS is basically the inverse of an average of the those latencies over time. It is kind of like the difference between FPS and Frame latencies. That said, the representation on the graphs is more the inverse of a one second sliding window average. Saying as much is kind of a mouthful, though. How would you phrase it?