ARM's Cortex A57 and Cortex A53: The First 64-bit ARMv8 CPU Cores
by Anand Lal Shimpi on October 30, 2012 11:58 AM EST- Posted in
- CPUs
- IT Computing
- Arm
- Cloud Computing
- SoCs
Yesterday AMD revealed that in 2014 it would begin production of its first ARMv8 based 64-bit Opteron CPUs. At the time we didn't know what core AMD would use, however today ARM helped fill in that blank for us with two new 64-bit core announcements: the ARM Cortex-A57 and Cortex-A53.
You may have heard of ARM's Cortex-A57 under the codename Atlas, while A53 was referred to internally as Apollo. The two are 64-bit successors to the Cortex A15 and A7, respectively. Similar to their 32-bit counterparts, the A57 and A53 can be used independently or in a big.LITTLE configuration. As a recap, big.LITTLE uses a combination of big (read: power hungry, high performance) and little (read: low power, lower performance) ARM cores on a single SoC.

By ensuring that both the big and little cores support the same ISA, the OS can dynamically swap the cores in and out of the scheduling pool depending on the workload. For example, when playing a game or browsing the web on a smartphone, a pair of A57s could be active, delivering great performance at a high power penalty. On the other hand, while just navigating through your phone's UI or checking email a pair of A53s could deliver adequate performance while saving a lot of power. A hypothetical SoC with two Cortex A57s and two Cortex A53s would still only appear to the OS as a dual-core system, but it would alternate between performance levels depending on workload.
 ARM's Cortex A57
ARM's Cortex A57
Architecturally, the Cortex A57 is much like a tweaked Cortex A15 with 64-bit support. The CPU is still a 3-wide/3-issue machine with a 15+ stage pipeline. ARM has increased the width of NEON execution units in the Cortex A57 (128-bits wide now?) as well as enabled support for IEEE-754 DP FP. There have been some other minor pipeline enhancements as well. The end result is up to a 20 - 30% increase in performance over the Cortex A15 while running 32-bit code. Running 64-bit code you'll see an additional performance advantage as the 64-bit register file is far simplified compared to the 32-bit RF.
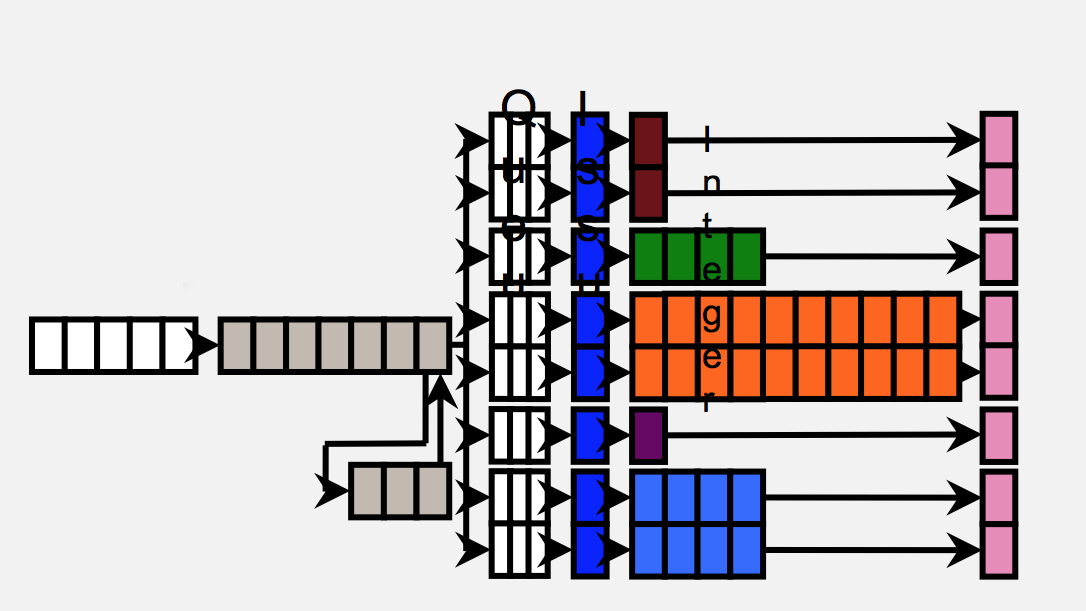
The Cortex A57 will support configurations of up to (and beyond) 16 cores for use in server environments. Based on ARM's presentation it looks like groups of four A57 cores will share a single L2 cache.
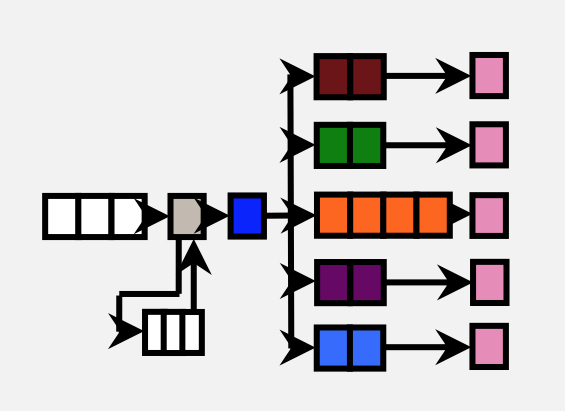
ARM's Cortex A53
Similarly, the Cortex A53 is a tweaked version of the Cortex A7 with 64-bit support. ARM didn't provide as many details here other than to confirm that we're still looking at a simple, in-order architecture with an 8 stage pipeline. The A53 can be used in server environments as well since it's ISA compatible with the A57.

ARM claims that on the same process node (32nm) the Cortex A53 is able to deliver the same performance as a Cortex A9 but at roughly 60% of the die area. The performance claims apply to both integer and floating point workloads. ARM tells me that it simply reduced a lot of the buffering and data structure size, while more efficiently improving performance. From looking at Apple's Swift it's very obvious that a lot can be done simply by improving the memory interface of ARM's Cortex A9. It's possible that ARM addressed that shortcoming while balancing out the gains by removing other performance enhancing elements of the core.

Both CPU cores are able to run 32-bit and 64-bit ARM code, as well as a mix of both so long as the OS is 64-bit.
Completed Cortex A57 and A53 core designs will be delivered to partners (including AMD and Samsung) by the middle of next year. Silicon based on these cores should be ready by late 2013/early 2014, with production following 6 - 12 months after that. AMD claimed it would have an ARMv8 based Opteron in production in 2014, which seems possible (although aggressive) based on what ARM told me.
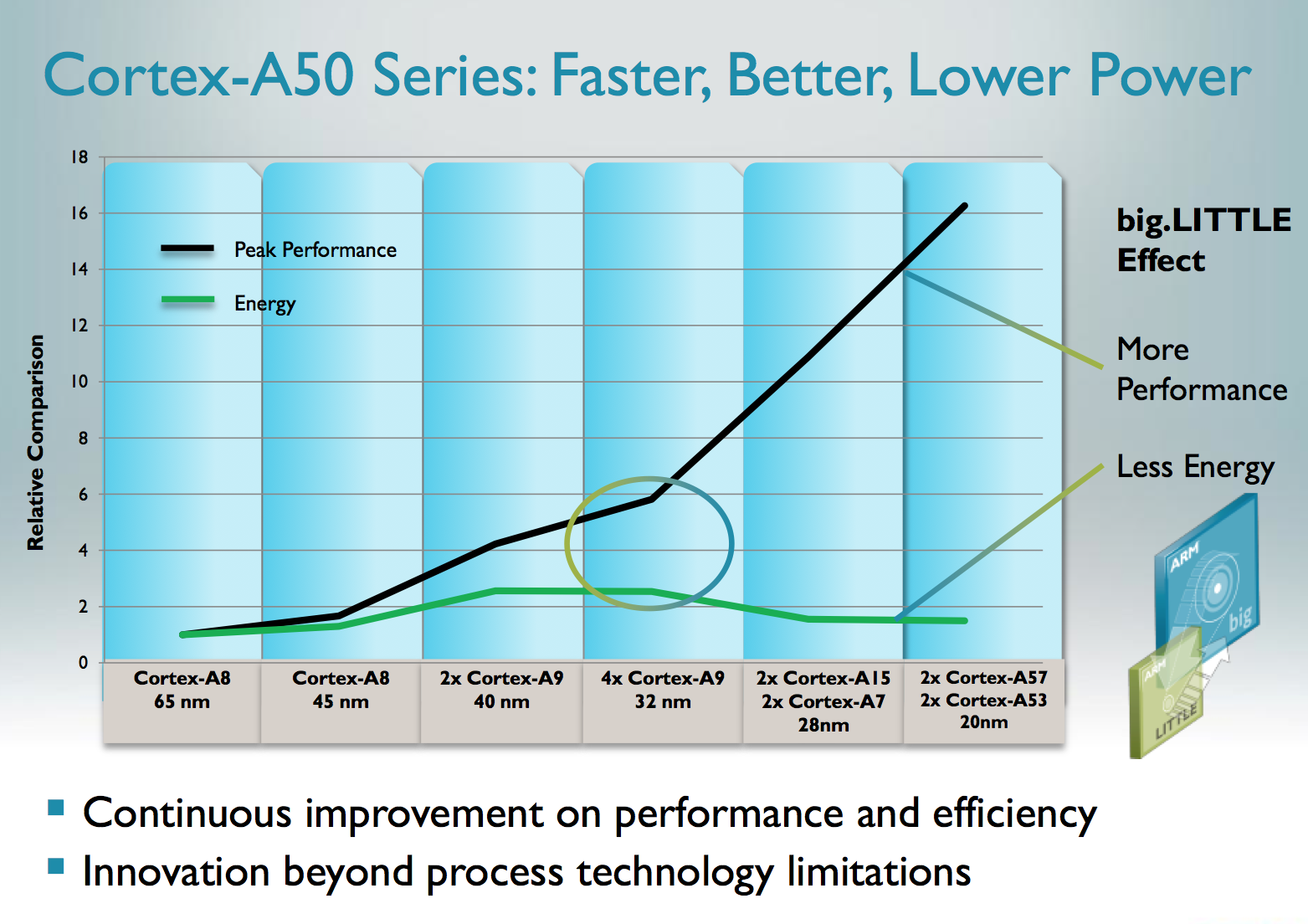
ARM expects the first designs to appear at 28nm and 20nm. There's an obvious path to 14nm as well.
It's interesting to note ARM's commitment to big.LITTLE as a strategy for pushing mobile SoC performance forward. I'm curious to see how the first A15/A7 designs work out. It's also good to see ARM not letting up on pushing its architectures forward.









117 Comments
View All Comments
Khato - Tuesday, October 30, 2012 - link
We're so close to at last having another piece of the puzzle, just a few more days/weeks before we'll get some good performance indications of the A15. I fully expect that it'll beat out the current Atom while being decimated by anything in the Core line... But the real question is just how far behind Atom will be, 'cause Atoms upcoming Silvermont core architecture could easily see a 2x performance gain.Krysto - Tuesday, October 30, 2012 - link
It's not "decimated" by the Core line. Exynos 5 Dual seems to be getting about 3-4x lower performance than my quad core Sandy Bridge laptop, in several browser tests. Considering it only uses 1-2W of power, that's pretty impressive. A57/A53 set-up should be good for just about any casual user, for much lower prices.Khato - Tuesday, October 30, 2012 - link
Eh, according to that review you linked in another comment it's 2x slower than a dual core SNB based celeron running at 1.3 GHz. Even that can qualify as being 'decimated' in terms of performance. Power is indeed an important metric, which is why I'm quite saddened to not yet see any figures in that respect from the chromebook reviews available as of yet.Wilco1 - Tuesday, October 30, 2012 - link
The simple fact that an A15 is now just 2x slower than Sandy Bridge at the same frequency is simply amazing and proof of how fast ARM CPUs are advancing on Intel! If anything, the SandyBridge is being decimated here by being around a factor 10 worse on power and cost.Shadowmaster625 - Tuesday, October 30, 2012 - link
You're not even comparing apples to apples. When comparing a sandy bridge celeron to an Exynos 5 SoC, you have to isolate how much power is being used by the memory bus, the storage, the display, the I/O controller... and compare each one separately.In most cases, features dont scale linearly at all... such as with SATA. If you want SATA you have to pay a steep power penalty.
In some cases the features scale somewhat linearly, such as with memory bandwidth and latency. Compare sandy bridge memory bandwidth and latency with the Exynos 5.
Then you have to look at price. What is the price of a sandy bridge mobile celeron, its chipset, and 4GB of DDR? And how much is an Exynos 5 and 2 GB of LPDDR? I wouldnt be surprised if the Exynos parts actually costed more. Dont forget that these phones are highly subsidized. Theyre actually quite expensive, far more than a $300 celeron notebook.
Wilco1 - Tuesday, October 30, 2012 - link
I'm not sure what you are getting at, but an Exynos 5 SoC contains far more on-chip than the Celeron which needs exxtra support chips which add cost and consumer more power.It's true the Sandy Bridge memory speed is a bit lower than the Exynos (10.6GB/s vs 12.8), but I don't think this affects power that much.
Price? Well we know that the Celeron Chromebook sells for $449 while the Exynos 5 one costs just $249. Since the specs are fairly similar, much of that extra cost is due to the expensive Intel CPU and chipset. The Celeron 867 costs a whopping $134 vs around $20 for Exynos.
lowlymarine - Tuesday, October 30, 2012 - link
SunSpider is an awful benchmark of modern processor performance. Certain browsers are "optimized" specifically for it to an absurd degree, it's single-threaded, fits almost entirely in processor cache, and cares about basically nothing but clock speed.Try something like LINPACK or software decode of HD content and tell me quad-core Sandy Bridge is "only 3-4x" faster than current ARM chips.
dagamer34 - Tuesday, October 30, 2012 - link
The fact that there's such a huge gulf between the Sunspider score on the HTC 8X and HTC One X should disqualify it as a performance benchmark. You can't use the OS as a variable in one comparison (Android v. Windows Phone), then change the CPU and parts of the kernel in another comparison (Android v Android). It's inconsistent.Symmetry81 - Tuesday, October 30, 2012 - link
I'd be really surprised if an A15 couldn't beat one of the old Core Solos form '06, even single threaded. Even the dual core Snapdragon S4 in a Galaxy S III comes pretty close if you check out the scores on Geekbench, and the Krait cores in those are about halfway between an A9 and an A15.Kurge - Thursday, November 1, 2012 - link
Not even close, the core solo would kill it in real work like video decoding. The more CPU constrained the task the more the Core would spank it.