Memory Performance: 16GB DDR3-1333 to DDR3-2400 on Ivy Bridge IGP with G.Skill
by Ian Cutress on October 18, 2012 12:00 PM EST- Posted in
- Memory
- G.Skill
- Ivy Bridge
- DDR3
Conversion – Xilisoft 7
Another classic example of memory bandwidth and speed is during video conversion. Data is passed between the memory and the CPU for processing – ideally faster memory here helps as well as memory that can deal with consecutive reads. Multiple threads on the CPU will also provide an additional stress, as each will ask for different data from the system. Our test uses two sets of conversions: first, a series of 160 videos have the first three minutes of each converted from various formats (480p to 1080p mkv) to AAC audio; and second is the motherboard testing, converting 32 1080p videos to iPod format. Each test is measured by the time taken to complete.
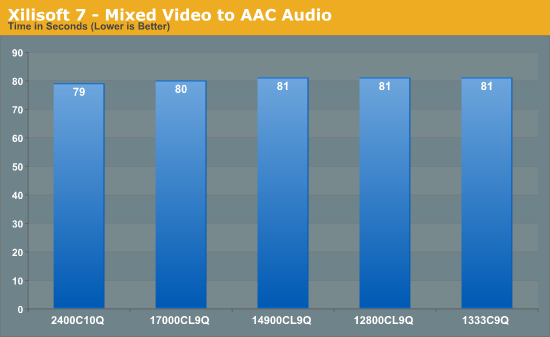
Converting to AAC seems to depend not on the memory – the movement of data from storage to memory to CPU is faster than the CPU can compute.
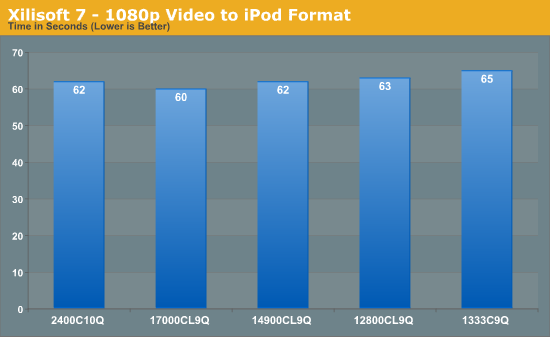
Video conversion is often one area quoted as being beneficial for memory speed, however these does not seem strictly true. As data is moved from storage to memory to the CPU, only if that memory transfer is the limiting factor does having faster memory help. In conversion to an iPod video format, that seems true moving from DDR3-1333 to DDR3-2133 just about, however it seems the limiting factor is still the CPU speed or the algorithm doing the conversion.
Folding on GPU
Memory usage is all algorithm dependent – if the calculation has a lot of small loops that do not require additional reads memory, then memory is unimportant. If the calculation requires data from other sources in those calculations, then memory can either be stressed randomly or sequentially. Using Ryan’s Folding benchmark as a platform, we are testing how much memory affects the serial calculation part of a standard F@H work unit.
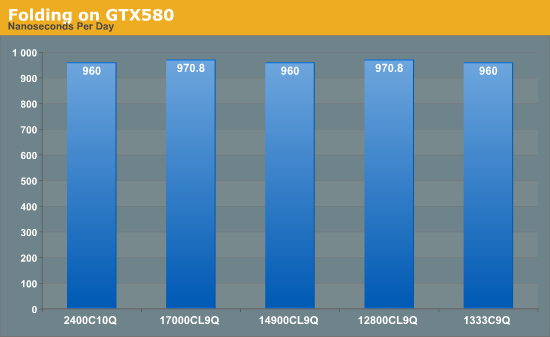
Unfortunately this test is only available to the nearest second, thus the benchmark finishes in either 89 or 90 seconds, giving appropriate ns/day. From the results, folding on GPUs is not affected by memory speed.
WinRAR x64 4.20
When compressing or converting files from one format to another, the file itself is often held in memory then passed through the CPU to be processed, then written back. If the file is larger than the available memory, then there is also loading time between the storage and the memory to consider. WinRAR is a variable multi-threaded benchmark, whereby the files it converts and compresses determines how much multi-threading takes place. When in multithreaded mode, the rate of cache misses can increase, leading to a less-than optimal scaling. Having fast memory can help with this.
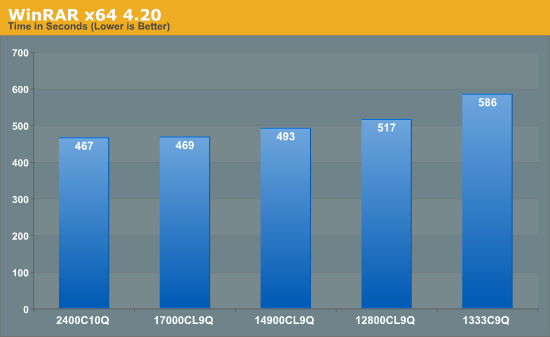
WinRAR is one of the benchmarks in our testing suite that benefits immensely from having faster memory. Moving from DDR3-1333 to DDR3-2400 speeds the process up by 20%, with the biggest gain moving from 1333 to 1600, and noticeable gains all the way up to 2133 C9.
Greysky's x264 HD 5.0.1
The x264 HD test, now version 5.0.1, tests the time to encode a 1080p video file into a high quality x264 video file. This test is standard across a range of reviews from AnandTech and other websites allowing for easy comparison. The benchmark is capable of running all cores to the maximum. Results here are reported as the average across four attempts for both the first and second passes.
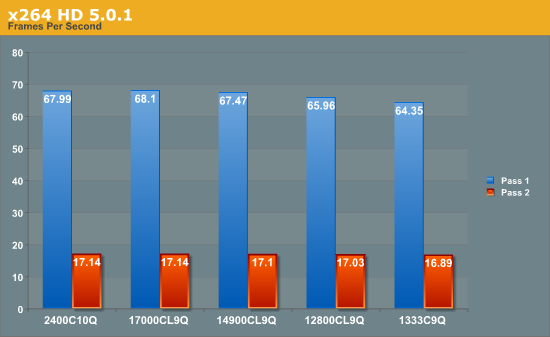
In another conversion test, we see that this benchmark gets a ~5% boost with faster memory, although Pass 1 sees a bigger boost than Pass 2. If conversion into x264 is the main purpose of the system, then the price premium of the faster memory could easily be justifiable.








114 Comments
View All Comments
jwilliams4200 - Friday, October 19, 2012 - link
You are also incorrect, as well as highly misleading to anyone who cares about practical matters regarding DRAM latencies.Reasonable people are interested in, for example, the fact that reading all the bytes on a DRAM page takes significantly less time than reading the same number of bytes from random locations distributed throughout the DRAM module.
Reasonable people can easily understand someone calling that difference sequential and random read speeds.
Your argument is equivalent to saying that no, you did not shoot the guy, the gun shot him, and you are innocent. No reasonable person cares about such specious reasoning.
hsir - Friday, October 26, 2012 - link
jwilliams4200 is absolutely right.People who care about practical memory performance worry about the inherent non-uniformity in DRAM access latencies and the factors that prevent efficient DRAM bandwidth utilization. In other words, just row-cycle time (tRC) and the pin bandwidth numbers are not even remotely sufficient to speculate how your DRAM system will perform.
DRAM access latencies are also significantly impacted by the memory controller's scheduling policy - i.e. how it prioritizes one DRAM request over another. Row-hit maximization policies, write-draining parameters and access type (if this is a cpu/gpu/dma request) will all affect latencies and DRAM bandwidth utilization. So just sweeping everything under the carpet by saying that every access to DRAM takes the same amount of time is, well, just not right.
nafhan - Friday, October 19, 2012 - link
I was specifically responding to your incorrect definition of "random access". Randomness doesn't guarantee timing; it just means you can get to it out of order.jwilliams4200 - Friday, October 19, 2012 - link
And yet, by any practical definition, you are incorrect and the author is correct.For example, if you read (from RAM) 1GiB of data in sequential order of memory addresses, it will be significantly faster than if you read 1GiB of data, one byte at a time, from randomly selected memory addresses. The latter will usually take two to four times as long (or worse).
It is not unreasonable to refer to that as the difference between sequential and random reads.
Your argument reminds me of the little boy who, chastised by his mother for pulling the cat's tail, whined, "I didn't pull the cat's tail, I just held it and the cat pulled."
jwilliams4200 - Thursday, October 18, 2012 - link
Depending on whether there is a page-hit (row needed already open), page-empty (row needed not yet open), or page-miss (row needed is not the row already open), the time to read a word can vary by a factor of 3 times (i.e., 1x latency for a page-hit, 2x latency for a page-empty, and 3x latency for a page-miss).What the author refers to as a "sequential read" probably probably refers to reading from an already open page (page-hit).
While his terminology may be ambiguous (and his computation for the "sequential read" is incorrect, it should be 4 clocks), he is nevertheless talking about a meaningful concept related to variation on latency in DRAM for different types of reads.
See here for more detail:
http://www.anandtech.com/show/3851/everything-you-...
Shadow_k - Thursday, October 18, 2012 - link
My knowledge of RAM has increased 10 fold very nice artical well donelosttsol - Thursday, October 18, 2012 - link
2133MHz "Recommended for Deeper Pockets"???Not really. DDR3 is so cheap now that high end RAM is affordable for all. I would have said you were crazy a few years ago if you told me soon I could buy 16GB of RAM for less than $150.
IanCutress - Thursday, October 18, 2012 - link
Either pay $95 for 1866 C9 or $130 for 2133 C9 - minor differences, but $35 saving. This is strictly talking about the kits used today, there could be other price differences. But I stand by my recommendation - for the vast majority of cases 1866 C9 will be fine, and there is a minor performance gain in some scenarios with 2133 C9, but at a $35 difference it is hard to justify unless you have some spare budget. Most likely that budget could be put into a bigger SSD or GPU.Ian
just4U - Friday, October 19, 2012 - link
Something has to be said about the TridentX brand I believe.. since it is getting some pretty killer feedback. It's simply the best ram out there being able to do all that any other ram can and that little bit extra. I don't see the speed increase as a selling point but the lower timings at conventional speeds that users are reporting is interesting.. I haven't tried it though.. just going on what I've read. Shame about the size of the heatsinks though.. makes it problematic in some builds.Peanutsrevenge - Friday, October 19, 2012 - link
You clearly live in some protected bubble where everyone has well paid jobs and isn't on a shoestring budget.I would so LMAO when you get mugged by someone struggling to feed themselves because you're all flash with your cash.