Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTHaswell's Wide Execution Engine
Conroe introduced the six execution ports that we've seen used all the way up to Ivy Bridge. Sandy Bridge saw significant changes to the execution engine to enable 256-bit AVX operations but without increasing the back end width. Haswell does a lot here.
Just as before, I put together a few diagrams that highlight the major differences throughout the past three generations for the execution engine.
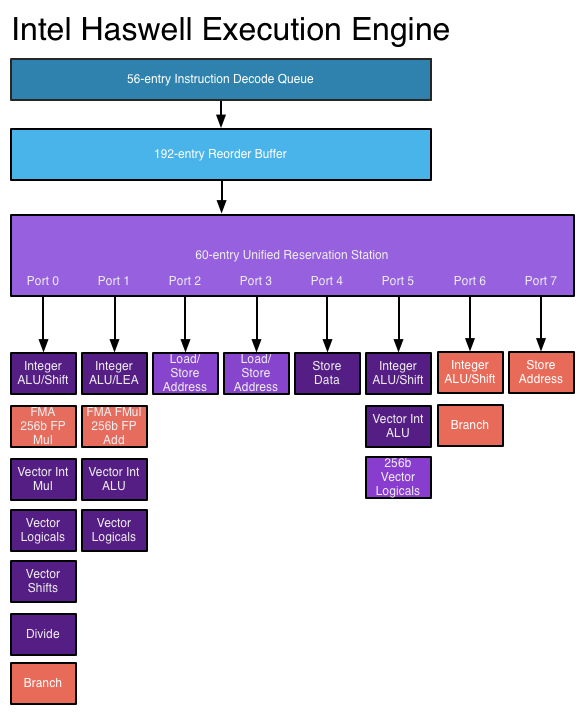
The reorder buffer is one giant tracking structure for all of the micro-ops that are in various stages of execution. The size of this buffer is directly impacted by the accuracy of the branch predictor as that will determine how many instructions can be kept in flight at a given time.
The reservation station holds micro-ops as they wait for the data they need to begin execution. Both of these structures grow by low double-digit percentages in Haswell.
Simply being able to pick from more instructions to execute in parallel is one thing, we haven't seen an increase in the number of parallel execution ports since Conroe. Haswell changes that.
From Conroe to Ivy Bridge, Intel's Core micro-architecture has supported the execution of up to six micro-ops in parallel. While there are more than six execution units in the system, there are only six ports to stacks of execution units. Three ports are used for memory operations (loads/stores) while three are on math duty. Over the years Intel has added additional types and widths of execution units (e.g. Sandy Bridge added 256-bit AVX operations) but it hasn't strayed from the 6 port architecture.
Haswell finally adds two more execution ports, one for integer math and branches (port 6) and one for store address calculation (port 7). Including both additional compute and memory hardware is a balanced decision on Intel's part.
The extra ALU and port does one of two things: either improve performance for integer heavy code, or allow integer work to continue while FP math occupies ports 0 and 1. Remember that Haswell, like its predecessors, is an SMT design meaning each core will see instructions from up to two threads at the same time. Although a single app is unlikely to mix heavy vector FP and integer code, it's quite possible that two applications running at the same time may produce such varied instructions. Having more integer ALUs is never a bad thing.
Also using port 6 is another unit that can handle x86 branch instructions. Branch heavy code can now enjoy two independent branch units, or if port 0 is occupied with other math the machine can still execute branches on port 6. Haswell moved the original Core branch unit from port 5 over to port 0, the most capable port in the system, so a branch unit on a lightly populated port makes helps ensure there's no performance regression as a result of the change.
Sandy Bridge made ports 2 & 3 equal class citizens, with both capable of being used for load or store address calculation. In the past you could only do loads on port 2 and store addresses on port 3. Sandy Bridge's flexibility did a lot for load heavy code, which is quite common. Haswell's dedicated store address port should help in mixed workloads with lots of loads and stores.
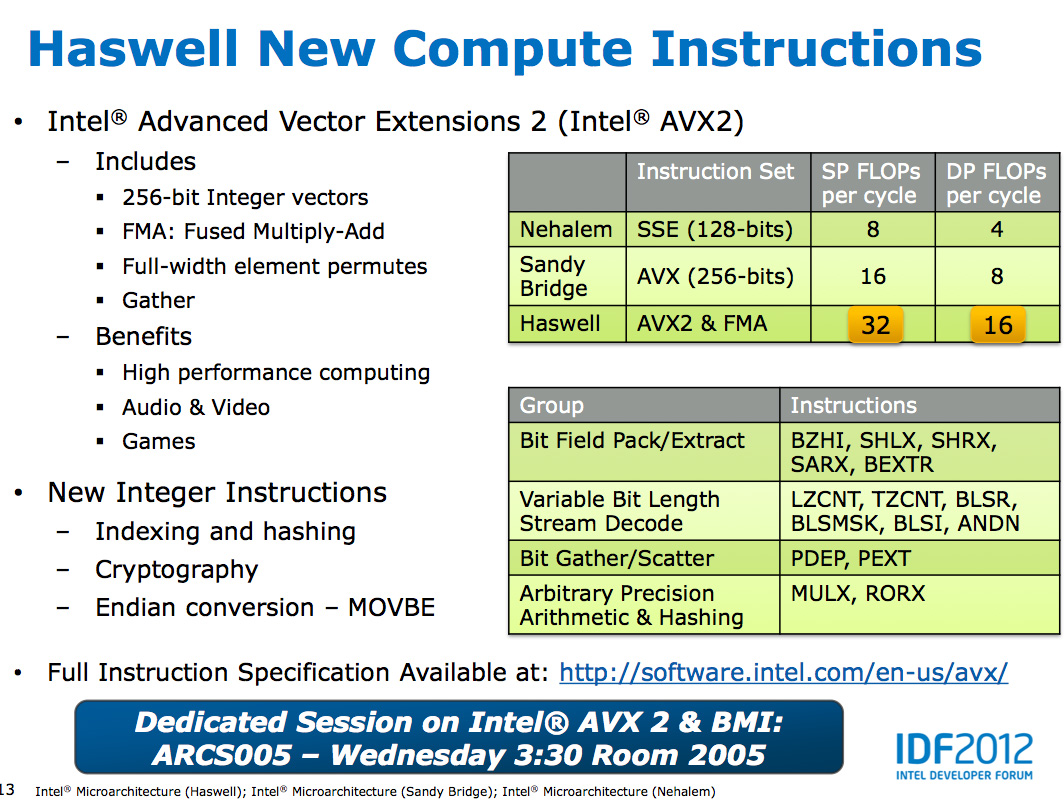
The other major addition to the execution engine is support for Intel's AVX2 instructions, including FMA (Fused Multiply-Add). Ports 0 & 1 now include newly designed 256-bit FMA units. As each FMA operation is effectively two floating point operations, these two units double the peak floating point throughput of Haswell compared to Sandy/Ivy Bridge. A side effect of the FMA units is that you now get two ports worth of FP multiply units, which can be a big boon to legacy FP code.
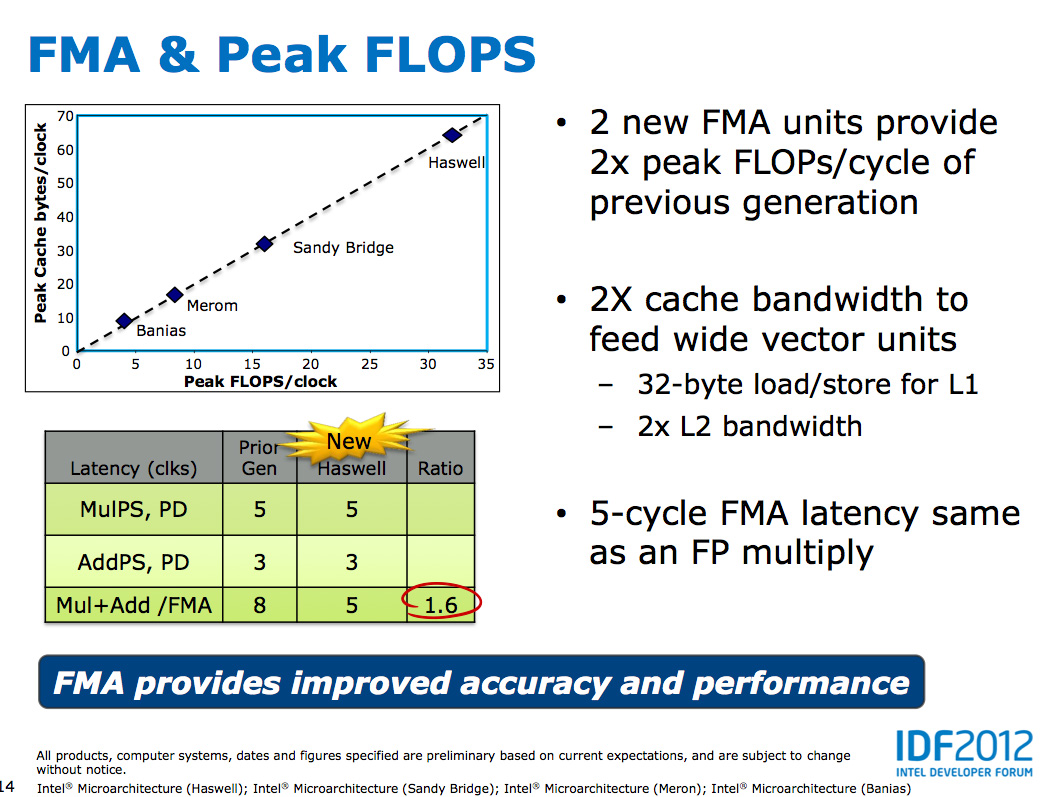
Fused Multiply-Add operations are incredibly handy in all sorts of media processing and 3D work. Rather than having to independently multiply and add values, being able to execute both in tandem via a single execution port increases the effective execution width of the machine. Note that a single FMA operation takes 5 cycles in Haswell, which is the same latency as a FP multiply from Sandy/Ivy Bridge. In the previous generation a floating point multiply+add took 8 cycles, so there's a good latency improvement here as well as the throughput boost from having two FMA units.
Intel focused a lot on adding more execution horsepower in Haswell without creating a power burden for legacy use cases. All of the new units can be shut off when not in use. Furthermore, Intel went in and ensured that this applied to the older execution units as well: in Haswell if you're not doing work, you're not consuming power.








245 Comments
View All Comments
TeXWiller - Friday, October 5, 2012 - link
Perhaps they also try to reach lower usable clock frequencies through performance upgrades and this way gain some additional voltage scaling, or what is left of it.vegemeister - Saturday, October 6, 2012 - link
>think loop counters which store an INT for loop iteration then perform some FP calcsIf updating the loop counter us taking a substantial fraction of the CPU time, doesn't that mean the compiler should have unrolled more?
Anand Lal Shimpi - Friday, October 5, 2012 - link
The high end desktop space was abandoned quite a while ago. The LGA-2011/Extreme platform remains as a way to somewhat address the market, but I think in reality many of those users simply shifted their sights downward with regards to TDPs. A good friend of mine actually opted for an S-series Ivy Bridge part when building his gaming mini-ITX PC because he wanted a cooler running system in addition to great performance.To specifically answer your question though - the common thread since Conroe/Merom was this belief that designing for power efficiency actually means designing for performance. All architectures since Merom have really been mobile focused, with versions built for the desktop. I like to think that desktop performance has continued to progress at a reasonable rate despite that, pretty much for the reason I just outlined.
Take care,
Anand
csroc - Friday, October 5, 2012 - link
Sandy Bridge E just seems to price itself out of being reasonable for a lot of people. The boards in particular are rather steep as well.dishayu - Friday, October 5, 2012 - link
Well, LGA2011 is bit of a halo product with no real substance. An ivy bridge 3770K will stand up to a quad core LGA2011 part nicely, not to mention it supports PCI e gen3, so even though it has lesser lanes, it doesn't have a bandwidth disadvantage. Moreover LGA2011 is still stuck at sandy based architecture, so that again isn't quite on the bleeding edge and as far as i understand, Haswell will come out before IB-E does, so it's 2 full cycles behind.Kevin G - Friday, October 5, 2012 - link
For a single discrete GPU, Ivy Bridge would be able to match the bandwidth of Sandy Bridge-E: a single 16 lane PCI-E 3.0 connection. Things get interesting when you scale the number of GPU's. There is a small but clear advantage to Sandy Bridge-E in a four GPU configuration. Ivy Bridge having fewer lanes does make a difference in such high end scenarios.For its target market (mobile, low end desktop), Ivy Bridge is 'good enough'.
vegemeister - Saturday, October 6, 2012 - link
Quad core LGA2011 is kind of a waste though. If you're already paying extra for the socket, my philosophy is go hexcore and 8 DIMMs or go home.Peanutsrevenge - Friday, October 5, 2012 - link
Given that desktop software's not really been pushing for better CPU performance, the direction intel has taken is not a bad one IMO either.It's now possible to build a mighty gaming rig in an mITX case (Bit Fenix Prodigy), think 3770K and GTX 690 gfx and watercooled.
A rig like that will likely last 3 years before settings have to be tweaked to keep 60+ fps.
What's really needed is for software to take advantage of GPUs more, (which would play into AMDs hands), but I fear many of the best coders have switched from windows to Android/iOS development, With windows 8 shipping shortly, that number will increase further.
j_newbie - Saturday, October 6, 2012 - link
I think that is quite sad.I for one always need more FLOPS, MCAD work and simulation work depends on two things memory bandwidth+size and flops, surprisingly AMD still offers a better vfm deal in this space thanks to avx instructions not being widely adopted into most FEA/CFD code yet and the additional ram slots you get with cheaper boards.
Server components are always overpriced as we dont need a system to last very long.
my 3930k setup is about 1.5 times faster than the x6 setup at 3 times the cost... :(
Peanutsrevenge - Saturday, October 6, 2012 - link
You're talking more of a workstation than a desktop. Hence my use of the word 'desktop'.