Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTHaswell's GPU
Although Intel provided a good amount of detail on the CPU enhancements to Haswell, the graphics discussion at IDF was fairly limited. That being said, there's still some to talk about here.
Haswell builds on the same fundamental GPU architecture we saw in Ivy Bridge. We won't see a dramatic redesign/re-plumbing of the graphics hardware until Broadwell in 2014 (that one is going to be a big one).
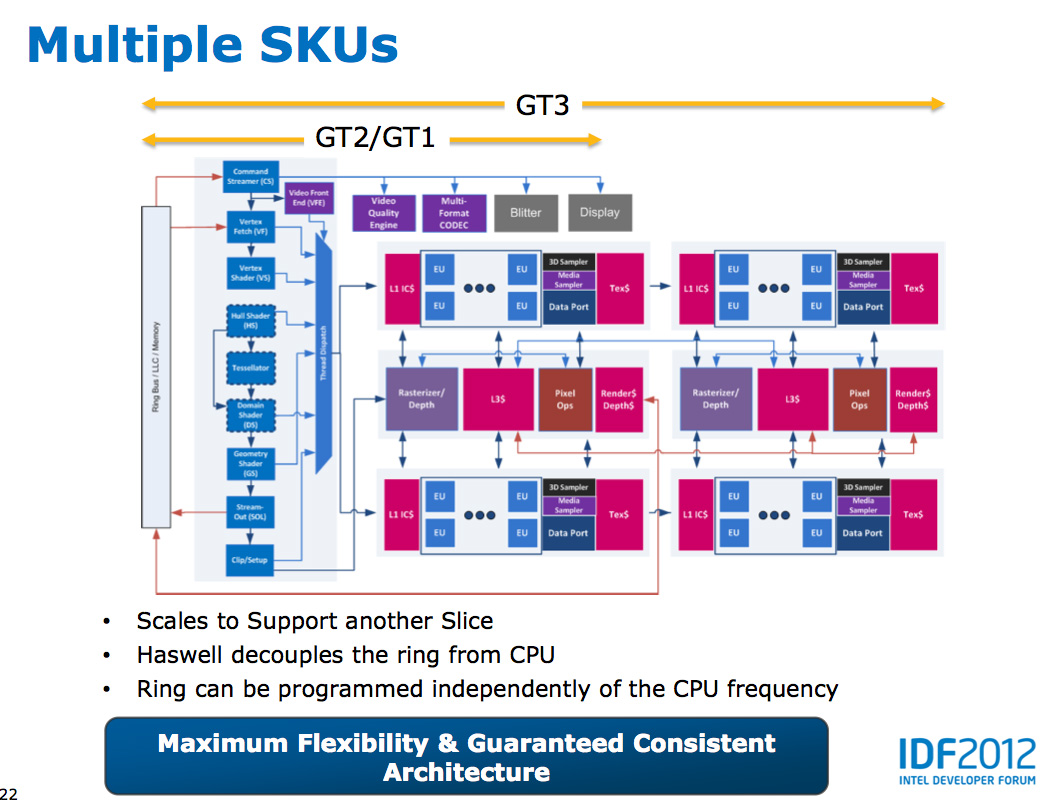
Haswell's GPU will be available in three physical configurations: GT1, GT2 and GT3. Although Intel mentioned that the Haswell GT3 config would have twice the shader count of Haswell GT2, it was careful not to disclose the total number of EUs in any of the versions. Based on the information we have at this point, GT3 should be a 40 EU configuration while GT2 should feature 20 EUs. Intel will also be including up to one redundant EU to deal with the case where there's a defect in an EU in the array. This isn't an uncommon practice, but it does indicate just how much of the die will be dedicated to graphics in Haswell. The larger of an area the GPU covers, the greater the likelihood that you'll see unrecoverable defects in the GPU. Redundancy at the EU level is one way of mitigating that problem.
Haswell's processor graphics extends API support to DirectX 11.1, OpenCL 1.2 and OpenGL 4.0.
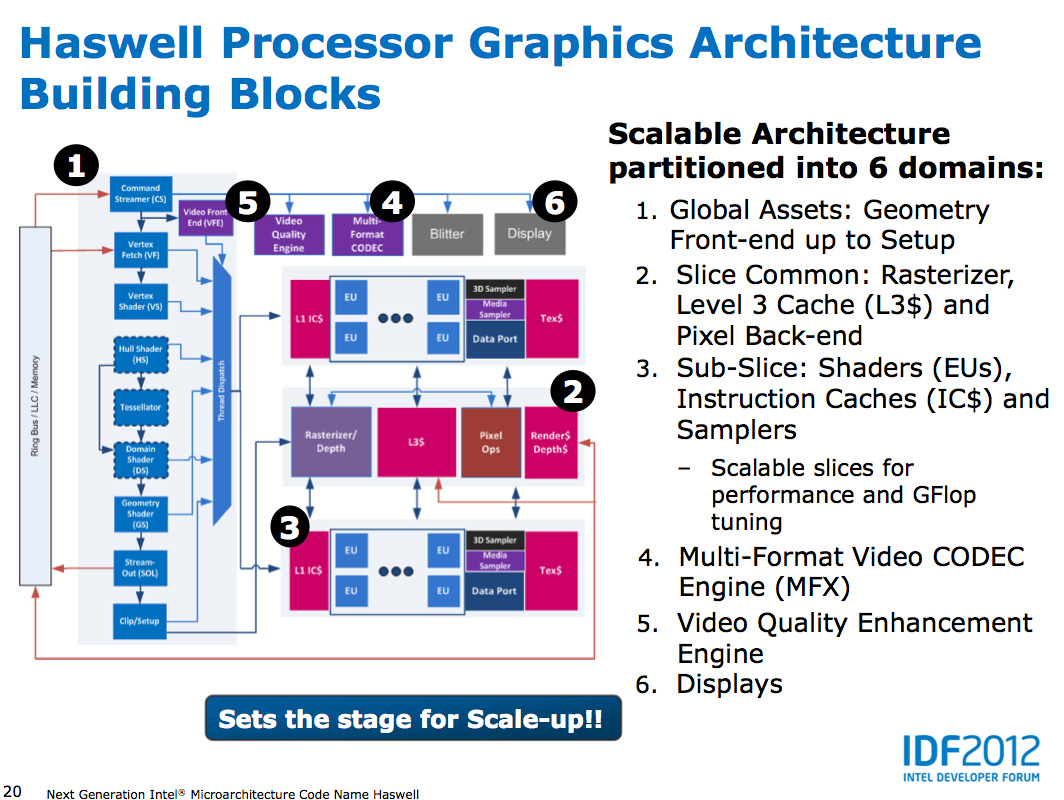
At the front of the graphics pipeline is a new resource streamer. The RS offloads some driver work that the CPU would normally handle and moves it to GPU hardware instead. Both AMD and NVIDIA have significant command processors so this doesn't appear to be an Intel advantage although the devil is in the (unshared) details. The point from Intel's perspective is that any amount of processing it can shift away from general purpose CPU hardware and onto the GPU can save power (CPU cores go to sleep while the RS/CS do their job).
Beyond the resource streamer, most of the fixed function graphics hardware sees a doubling of performance in Haswell.
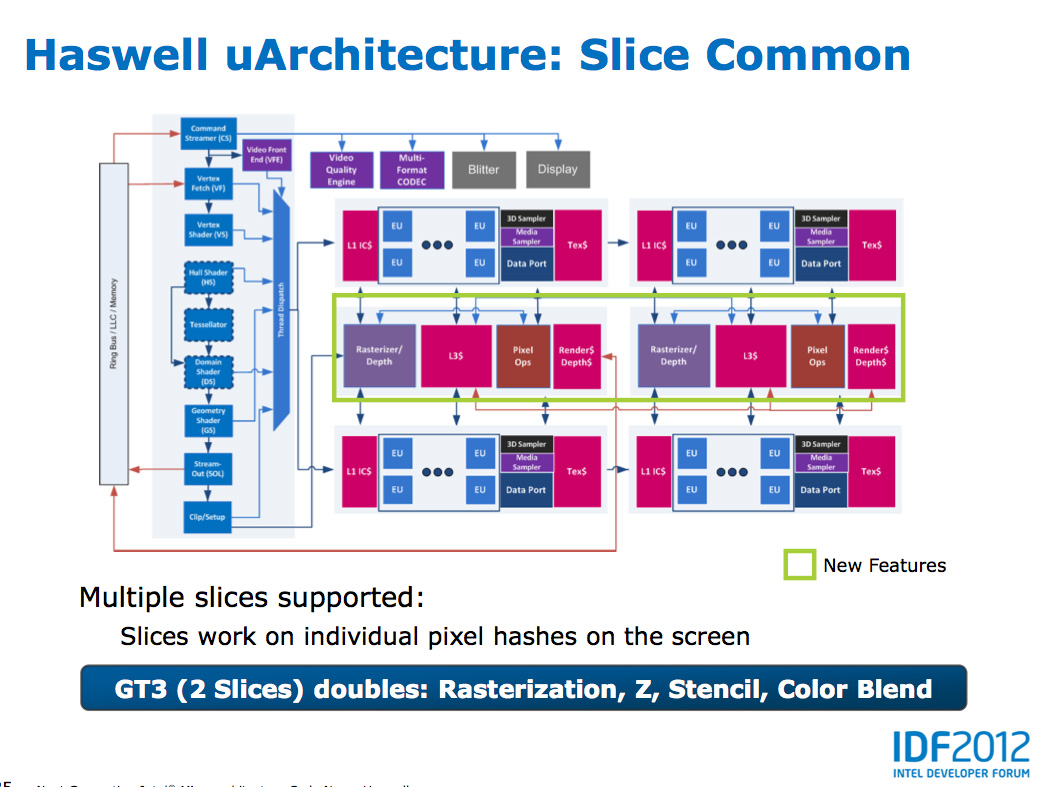
At the shader core level, Intel separates the GPU design into two sections: slice common and sub-slice. Slice common includes the rasterizer, pixel back end and GPU L3 cache. The sub-slice includes all of the EUs, instruction caches and EUs.
In Haswell GT1 and GT2 there's a single slice common, while GT3 sees a doubling of slice common. GT3 similarly has two sub-slices, although once again Intel isn't talking specifics about EU counts or clock speeds between GT1/2/3.
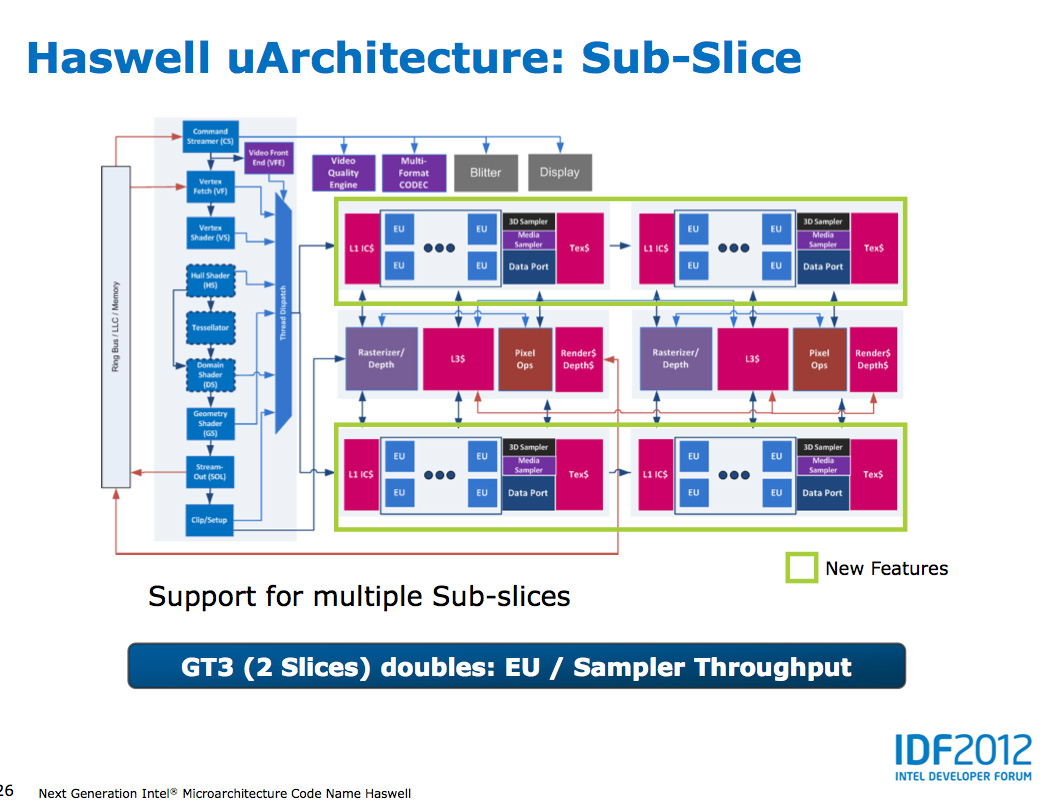
The final bit of detail Intel gave out about Haswell's GPU is the texture sampler sees up to a 4x improvement in throughput over Ivy Bridge in some modes.
Now to the things that Intel didn't let loose at IDF. Although originally an option for Ivy Bridge (but higher ups at Intel killed plans for it) was a GT3 part with some form of embedded DRAM. Rumor has it that Apple was the only customer who really demanded it at the time, and Intel wasn't willing to build a SKU just for Apple.
Haswell will do what Ivy Bridge didn't. You'll see a version of Haswell with up to 128MB of embedded DRAM, with a lot of bandwidth available between it and the core. Both the CPU and GPU will be able to access this embedded DRAM, although there are obvious implications for graphics.
Overall performance gains should be about 2x for GT3 (presumably with eDRAM) over HD 4000 in a high TDP part. In Ultrabooks those gains will be limited to around 30% max given the strict power limits.
As for why Intel isn't talking about embedded DRAM on Haswell, your guess is as good as mine. The likely release timeframe for Haswell is close to June 2013, there's still tons of time between now and then. It looks like Intel still has a desire to remain quiet on some fronts.








245 Comments
View All Comments
TeXWiller - Friday, October 5, 2012 - link
Perhaps they also try to reach lower usable clock frequencies through performance upgrades and this way gain some additional voltage scaling, or what is left of it.vegemeister - Saturday, October 6, 2012 - link
>think loop counters which store an INT for loop iteration then perform some FP calcsIf updating the loop counter us taking a substantial fraction of the CPU time, doesn't that mean the compiler should have unrolled more?
Anand Lal Shimpi - Friday, October 5, 2012 - link
The high end desktop space was abandoned quite a while ago. The LGA-2011/Extreme platform remains as a way to somewhat address the market, but I think in reality many of those users simply shifted their sights downward with regards to TDPs. A good friend of mine actually opted for an S-series Ivy Bridge part when building his gaming mini-ITX PC because he wanted a cooler running system in addition to great performance.To specifically answer your question though - the common thread since Conroe/Merom was this belief that designing for power efficiency actually means designing for performance. All architectures since Merom have really been mobile focused, with versions built for the desktop. I like to think that desktop performance has continued to progress at a reasonable rate despite that, pretty much for the reason I just outlined.
Take care,
Anand
csroc - Friday, October 5, 2012 - link
Sandy Bridge E just seems to price itself out of being reasonable for a lot of people. The boards in particular are rather steep as well.dishayu - Friday, October 5, 2012 - link
Well, LGA2011 is bit of a halo product with no real substance. An ivy bridge 3770K will stand up to a quad core LGA2011 part nicely, not to mention it supports PCI e gen3, so even though it has lesser lanes, it doesn't have a bandwidth disadvantage. Moreover LGA2011 is still stuck at sandy based architecture, so that again isn't quite on the bleeding edge and as far as i understand, Haswell will come out before IB-E does, so it's 2 full cycles behind.Kevin G - Friday, October 5, 2012 - link
For a single discrete GPU, Ivy Bridge would be able to match the bandwidth of Sandy Bridge-E: a single 16 lane PCI-E 3.0 connection. Things get interesting when you scale the number of GPU's. There is a small but clear advantage to Sandy Bridge-E in a four GPU configuration. Ivy Bridge having fewer lanes does make a difference in such high end scenarios.For its target market (mobile, low end desktop), Ivy Bridge is 'good enough'.
vegemeister - Saturday, October 6, 2012 - link
Quad core LGA2011 is kind of a waste though. If you're already paying extra for the socket, my philosophy is go hexcore and 8 DIMMs or go home.Peanutsrevenge - Friday, October 5, 2012 - link
Given that desktop software's not really been pushing for better CPU performance, the direction intel has taken is not a bad one IMO either.It's now possible to build a mighty gaming rig in an mITX case (Bit Fenix Prodigy), think 3770K and GTX 690 gfx and watercooled.
A rig like that will likely last 3 years before settings have to be tweaked to keep 60+ fps.
What's really needed is for software to take advantage of GPUs more, (which would play into AMDs hands), but I fear many of the best coders have switched from windows to Android/iOS development, With windows 8 shipping shortly, that number will increase further.
j_newbie - Saturday, October 6, 2012 - link
I think that is quite sad.I for one always need more FLOPS, MCAD work and simulation work depends on two things memory bandwidth+size and flops, surprisingly AMD still offers a better vfm deal in this space thanks to avx instructions not being widely adopted into most FEA/CFD code yet and the additional ram slots you get with cheaper boards.
Server components are always overpriced as we dont need a system to last very long.
my 3930k setup is about 1.5 times faster than the x6 setup at 3 times the cost... :(
Peanutsrevenge - Saturday, October 6, 2012 - link
You're talking more of a workstation than a desktop. Hence my use of the word 'desktop'.