Samsung SSD 840 (250GB) Review
by Kristian Vättö on October 8, 2012 12:14 PM EST- Posted in
- Storage
- SSDs
- Samsung
- TLC
- Samsung SSD 840
Lower Endurance—Why?
Below we have a diagram of a MOSFET (Metal Oxide Semiconductor Field Effect Transistor). When programming a cell, voltage is placed on the control gate, which forms an electric field that allows electrons to tunnel through the silicon oxide barrier to the floating gate. Once the tunneling process is complete, voltage to the control gate is dropped back to 0V and the silicon oxide acts as an insulator. Erasing a cell is done in a similar way but this time the voltage is placed on the silicon substrate (P-well in the picture), which again creates an electric field that allows the electrons to tunnel through the silicon oxide.
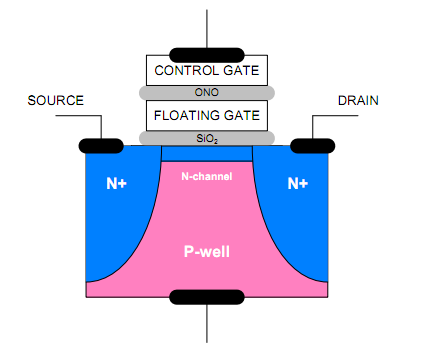
While the MOSFET is exactly the same for SLC, MLC and TLC, the difference lies in how the cell is programmed. With SLC, the cell is either programmed or it's not because it can only be "0" or "1". As MLC stores two bits in one cell, its value can either be "00", "01", "10" or "11", which means there are four different voltage states. TLC ups the voltage states to eight as there are eight different combinations of "0" and "1" when grouped in groups of three bits. Below are diagrams showing the graphical version of the voltage states:
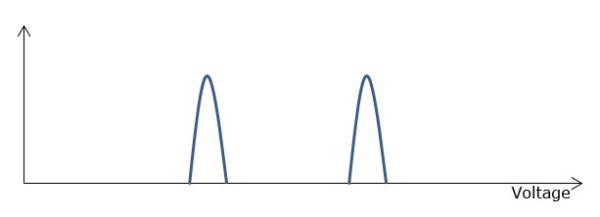
SLC
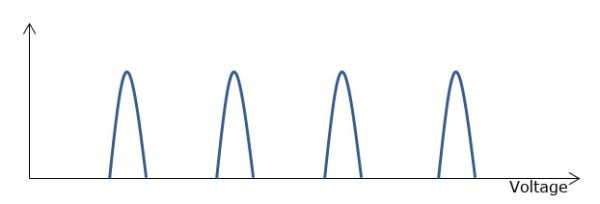
MLC
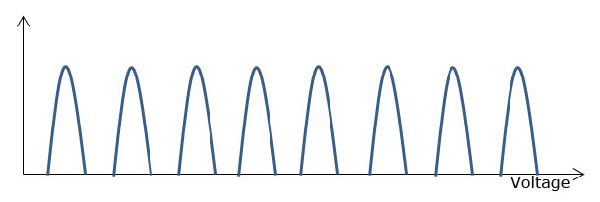
TLC
The above diagrams show the voltages for brand new NAND—everything looks nice and neat and the only difference is that TLC has more states. However, the tunneling process that happens every time the cell is programmed or erased wears the silicon oxide out. The actual oxide is only about 10nm thick and it gets thinner every time a smaller process node is introduced, which is why endurance gets worse as we move to smaller nodes. When the silicon dioxide wears out, atomic bonds break and some electrons may get trapped inside the oxide during the tunneling process. That builds up negative charge in the silicon oxide, which in turn negates some of the control gate voltage when the cell is programmed.
The wear results in longer erase times because higher voltages need to be applied for longer times before the right voltage is found. Remember, the controller can't adjust to changes in program and erase voltages (well, some can; more on this on the next page) that come from the trapped electrons, cell leakage, and other sources. If the voltage that's supposed to work doesn't, the controller has to basically go on guess basis and simply try different voltages before the right one is found. That takes time and causes even more stress on the silicon oxide.
The difference between SLC, MLC, and TLC is pretty simple: SLC has the fewest voltage states and hence it can tolerate bigger changes in voltages. With TLC, there are eight different states and hence a lot less voltage room to play with. While the exact voltages used are unknown, you basically have to divide the same voltage into eight sections instead of four or two like the graphs above show, which means the voltages don't have room to change as much. The reason why a NAND block has to be retired is that erasing it starts to take too long, which impacts performance (and eventually a NAND block simply becomes nonfunctional, e.g. the voltage states for 010 and 011 begin to overlap).
There is also more and more ECC needed as the NAND wears out because the possibility for errors is greater. With TLC, that's once again a bigger problem because there are three bits to correct instead of one or two. While today's ECC engines are fairly powerful, at some point it will be easier to just retire the block than to keep correcting errors.








86 Comments
View All Comments
travbrad - Wednesday, October 10, 2012 - link
I had a 80GB WD that lasted 8 years without failing. I eventually had to stop using it simply because it was too slow. I also had a 250GB WD drive that I used for 5 years (then switched to all SATA). Now I have a 640GB drive that I've been using for almost 4 years. My brother has a couple 500GB drives in his system that have been running for 4-5 years as well.Maybe I've just been really lucky, but the only drive I've personally had fail in the last decade was a Hitachi drive (obviously selected for cost not quality) in my HP laptop.
Now at work it's a different story. Those pre-built machines cut every corner they can to bring costs down so they end up with low quality components (especially PSUs). Even in that situation there is a fairly low number of hard drive failures though (considering how old most of the machines are)
mapesdhs - Friday, October 12, 2012 - link
I have SCSI disks that are more than 20 years old which still work fine. :D
Ian.
MarkLuvsCS - Monday, October 8, 2012 - link
Considering Write Amplification has been significantly reduced compared to the initial SSD tech, I don't believe it's going to be a problem for the consumer market. Google xtremesystems Write Endurance to see a Samsung 830 256gb with 3000 P/E still running at 4.77 PETABYTES.That page also shows you other brands and how they fare. I would trust Samsung wouldn't put this tech to use without truly understanding how it would pan out.That is why the worry of the 1000 P/E 840 vs 3000 P/E 830 is overblown. Either way you have little to worry about with Samsung's controllers causing any fuss unlike Other CompanieZ.
Kjella - Monday, October 8, 2012 - link
Not giving one fsck about wearing out the SSD I burned through a 10k-rated SSD in 1.5 years. Now with fairly normal SSD usage - a standard Win7 desktop with torrents etc. on other drives - I'm down to 57% health and looking at 3 years 10 months on a 5K-rated drive. I don't know exactly what is eating it but I'm guessing every log file, every time MSN or IRC logs a line of chat, every time something is cached or whatever it burns write cycles. I feel the official numbers are vastly *overstating* the actual lifespan, not understating it. TLC with 1K writes? Not in my machine, no sir.madmilk - Monday, October 8, 2012 - link
There's no way MSN/IRC can burn through an SSD in 1.5 years since they're all text. You must be doing something unusual, or at least your computer is without you knowing it. A good idea would be to open up Task Manager, and select the columns that count the number of bytes written by various programs. Maybe then you can find the source of your problem. Also make sure you have defragmentation off, and sufficient RAM so you're not constantly hitting the pagefile.piiman - Tuesday, February 19, 2013 - link
Better yet put the page file on a different drive and also move your temp folders to a different drive.Notmyusualid - Tuesday, October 9, 2012 - link
Absolutely hilarious ending there pal... I wonder how many people got it!I got burned by them on a couple of drives, and promptly dumped them on some well-known auction site, sold as-is.
creed3020 - Tuesday, October 9, 2012 - link
I see what you did there ;-)Great review Kristian! I'll be looking at this drive as option for a new office PC I am building.
B3an - Monday, October 8, 2012 - link
Did you people even bother to read?? Because you're conveniently missing out the important fact in this article that you'd have to write 36.5TiB (almost 40TB) a year for it to last 3.5 years. I know for a fact that the average consumer does not write anywhere near that much a year, or even in 3 years. If anyone even comes close to 40TB a year they would be using a higher-end MLC SSD anyway as they would surely be using a workstation.Most consumers don't even write 10GB a day, so at that rate the drive would easily last OVER 20 years. But of course it's highly likely something else would fail before that happens.
You're also forgetting out DSP which is explained in this article as well. That can also near double the life.
I think Kristian should have made this all more clear because too many people don't bother to actually read stuff and just look at charts.
futrtrubl - Monday, October 8, 2012 - link
Granted the usual use cases won't have so much data throughput. However those same usual use cases have the user filling 3/4 of the drive with static data (program/OS/photo archive etc) reducing the drive area it's able to wear level over. So that 20 years again becomes 5 years.Also the 1000PE cycle stat means that there is a 50% chance for that sector to have become unusable by that time (ignoring DSP).
I'm not saying that TLC is bad, and I am certainly not saying this drive doesn't have great value. I'm just saying that we shouldn't understate the PE cycle issue.