The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Custom Code to Understand a Custom Core
Section by Anand Shimpi
All Computer Engineers at NCSU had to take mandatory programming courses. Given that my dad is a Computer Science professor, I always had exposure to programming, but I never considered it my strong suit - perhaps me gravitating towards hardware was some passive rebellious thing. Either way I knew that in order to really understand Swift, I'd have to do some coding on my own. The only problem? I have zero experience writing Objective-C code for iOS, and not enough time to go through a crash course.
I had code that I wanted to time/execute in C, but I needed it ported to a format that I could easily run/monitor on an iPhone. I enlisted the help of a talented developer friend who graduated around the same time I did from NCSU, Nirdhar Khazanie. Nirdhar has been working on mobile development for years now, and he quickly made the garbled C code I wanted to run into something that executed beautifully on the iPhone. He gave me a framework where I could vary instructions as well as data set sizes, which made this next set of experiments possible. It's always helpful to know a good programmer.
So what did Nirdhar's app let me do? Let's start at the beginning. ARM's Cortex A9 has two independent integer ALUs, does Swift have more? To test this theory I created a loop of independent integer adds. The variables are all independent of one another, which should allow for some great instruction level parallelism. The code loops many times, which should make for some easily predictable branches. My code is hardly optimal but I did keep track of how many millions of adds were executed per second. I also reported how long each iteration of the loop took, on average.
| Integer Add Code | ||||||
| Apple A5 (2 x Cortex A9 @ 800MHz | Apple A5 Scaled (2 x Cortex A9 @ 1300MHz | Apple A6 (2 x Swift @ 1300MHz | Swift / A9 Perf Advantage @ 1300MHz | |||
| Integer Add Test | 207 MIPS | 336 MIPS | 369 MIPS | 9.8% | ||
| Integer Add Latency in Clocks | 23 clocks | 21 clocks | ||||
The code here should be fairly bound by the integer execution path. We're showing a 9.8% increase in performance. Average latency is improved slightly by 2 clocks, but we're not seeing the sort of ILP increase that would come from having a third ALU that can easily be populated. The slight improvement in performance here could be due to a number of things. A quick look at some of Apple's own documentation confirms what we've seen here: Swift has two integer ALUs and can issue 3 operations per cycle (implying a 3-wide decoder as well). I don't know if the third decoder is responsible for the slight gains in performance here or not.

What about floating point performance? ARM's Cortex A9 only has a single issue port for FP operations which seriously hampers FP performance. Here I modified the code from earlier to do a bunch of single and double precision FP multiplies:
| FP Add Code | ||||||
| Apple A5 (2 x Cortex A9 @ 800MHz | Apple A5 Scaled (2 x Cortex A9 @ 1300MHz | Apple A6 (2 x Swift @ 1300MHz | Swift / A9 Perf Advantage @ 1300MHz | |||
| FP Mul Test (single precision) | 94 MFLOPS | 153 MFLOPS | 143 MFLOPS | -7% | ||
| FP Mul Test (double precision) | 87 MFLOPS | 141 MFLOPS | 315 MFLOPS | 123% | ||
There's actually a slight regression in performance if we look at single precision FP multiply performance, likely due to the fact that performance wouldn't scale perfectly linearly from 800MHz to 1.3GHz. Notice what happens when we double up the size of our FP multiplies though, performance goes up on Swift but remains unchanged on the Cortex A9. Given the support for ARM's VFPv4 extensions, Apple likely has a second FP unit in Swift that can help with FMAs or to improve double precision FP performance. It's also possible that Swift is a 128-bit wide NEON machine and my DP test compiles down to NEON code which enjoys the benefits of a wider engine. I ran the same test with FP adds and didn't notice any changes to the data above.
Sanity Check with Linpack & Passmark
Section by Anand Shimpi
Not completely trusting my own code, I wanted some additional data points to help understand the Swift architecture. I first turned to the iOS port of Linpack and graphed FP performance vs. problem size:
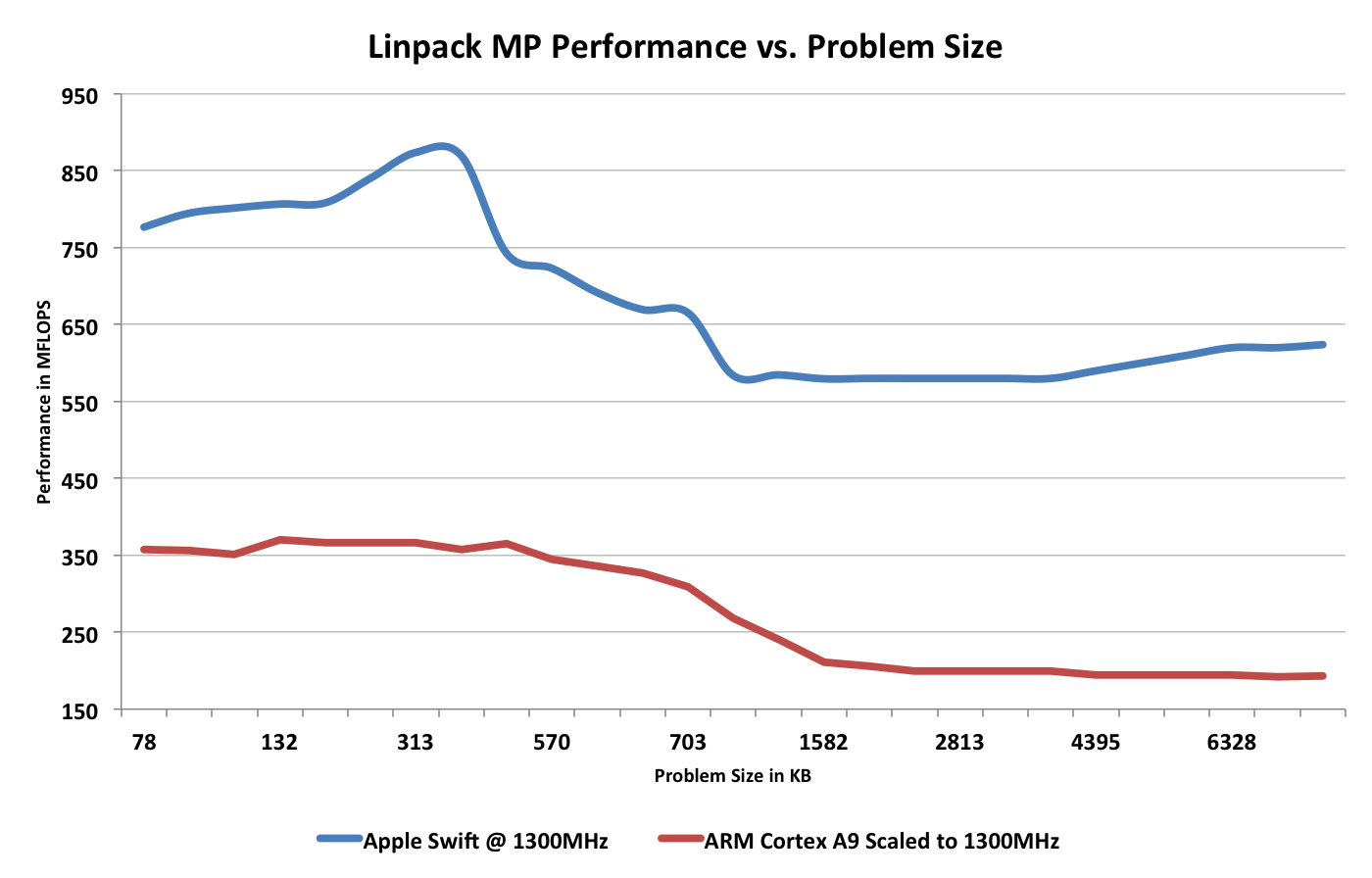
Even though I ran the benchmark for hundreds of iterations at each data point, the curves didn't come out as smooth as I would've liked them to. Regardless there's a clear trend. Swift maintains a huge performance advantage, even at small problem sizes which supports the theory of having two ports to dedicated FP hardware. There's also a much smaller relative drop in performance when going out to main memory. If you do the math on the original unscaled 4S scores you get the following data:
| Linpack Throughput: Cycles per Operation | ||||
| Apple Swift @ 1300MHz (iPhone 5) | ARM Cortex A9 @ 800MHz (iPhone 4S) | |||
| ~300KB Problem Size | 1.45 cycles | 3.55 cycles | ||
| ~8MB Problem Size | 2.08 cycles | 6.75 cycles | ||
| Increase | 43% | 90% | ||
Swift is simply able to hide memory latency better than the Cortex A9. Concurrent FP/memory operations seem to do very well on Swift...
As the last sanity check I used Passmark, another general purpose iOS microbenchmark.
| Passmark CPU Performance | ||||||
| Apple A5 (2 x Cortex A9 @ 800MHz | Apple A5 Scaled (2 x Cortex A9 @ 1300MHz | Apple A6 (2 x Swift @ 1300MHz | Swift / A9 Perf Advantage @ 1300MHz | |||
| Integer | 257 | 418 | 614 | 47.0% | ||
| FP | 230 | 374 | 813 | 118% | ||
| Primality | 54 | 87 | 183 | 109% | ||
| String qsort | 1065 | 1730 | 2126 | 22.8% | ||
| Encryption | 38.1 | 61.9 | 93.5 | 51.0% | ||
| Compression | 1.18 | 1.92 | 2.26 | 17.9% | ||
The integer math test uses a large dataset and performs a number of add, subtract, multiply and divide operations on the values. The dataset measures 240KB per core, which is enough to stress the L2 cache of these processors. Note the 47% increase in performance over a scaled Cortex A9.
The FP test is identical to the integer test (including size) but it works on 32 and 64-bit floating point values. The performance increase here despite facing the same workload lends credibility to the theory that there are multiple FP pipelines in Swift.
The Primality benchmark is branch heavy and features a lot of FP math and compares. Once again we see huge scaling compared to the Cortex A9.
The qsort test features integer math and is very branch heavy. The memory footprint of the test is around 5MB, but the gains here aren't as large as we've seen elsewhere. It's possible that Swift features a much larger branch mispredict penalty than the A9.
The Encryption test works on a very small dataset that can easily fit in the L1 cache but is very heavy on the math. Performance scales very well here, almost mirroring the integer benchmark results.
Finally the compression test shows us the smallest gains once you take into account Swift's higher operating frequency. There's not much more to conclude here other than we won't always see greater than generational scaling from Swift over the previous Cortex A9.








276 Comments
View All Comments
A5 - Tuesday, October 16, 2012 - link
Double the browsing time while moving to LTE and roughly the same in everything else despite double the performance is pretty impressive.rarson - Thursday, October 18, 2012 - link
I'm pretty sure they mentioned about a million times that "this is the new paradigm blah blah blah, where if you use heavy processing power more often, the battery life will diminish faster" (I'm paraphrasing here). I'm fine with that. The iPhone 5 shows some pretty impressive battery life in light workloads and doesn't actually do all that bad in heavy workloads despite how much number crunching it's doing, even though it might actually tank the battery life down to less-than-4S levels.It's a tradeoff: you get more power or longer battery life, depending on how you use it. The article paints this as a bad thing, but I disagree; it's obviously making much more efficient use of the hardware. Because of that, I definitely think the battery life overall is better, even though sometimes it might be worse. And you're still getting a lot more number crunching for the watts used.
Center - Tuesday, October 16, 2012 - link
In the intro, the screen specs on the iphone 5 is listed as 1136x960.. should be 1136x640.But great article as always, Anandtech!
Krysto - Tuesday, October 16, 2012 - link
I hope we'll see the same kind of thorough review of Samsung's Exynos 5 Dual chip, Anand.ltcommanderdata - Tuesday, October 16, 2012 - link
Isn't TI supposed to become the first shipping Cortex A15 SoC? I expect Anandtech to thoroughly review the first Cortex A15 SoC. There shouldn't be a need to go into the same detail (on the CPU side) for every subsequent one unless preliminary tests show something significantly different.Kidster3001 - Monday, October 22, 2012 - link
Samsung and Qualcomm do not ship generic ARM chips. They purchase licenses to use the ARM instruction set, not the chip design. Their chips are highly customized and perform differently.Using your logic to just review the first A15 class chip and consider the rest to be comparable is similar to just reviewing the first new car to be released every year and assume the rest will be comparable.
btw, TI is getting out of the business. I doubt they will ship first, or ever.
A5 - Tuesday, October 16, 2012 - link
Considering the fact that Krait got several articles here, I'd imagine that whatever the first shipping A15 chip is will get significant coverage.Wurzelsepp - Tuesday, October 16, 2012 - link
Great review, you really have to give Apple credit for building an amazing SoC.It's interesting to see how well the Adreno competes with SGX-543MP3, the new Nexus 4 with this GPU is going to be amazing.
Krysto - Tuesday, October 16, 2012 - link
One thing both the iPhone and the Intel Atom processors will keep lacking for a year from now, will be OpenGL ES 3.0 support. Apple might bring it to the new iPad 4 this spring, but the iPhone won't have it until the next iPhone, in the fall of 2013, obviously. Same with Intel, they won't be supporting it at least until end of 2013.In the meantime both Adreno 320 and Mali T604 are supporting it, and will come out this fall.
darwinosx - Tuesday, October 16, 2012 - link
A year from now and something 'coming out this fall". Right.