Making Sense of the Intel Haswell Transactional Synchronization eXtensions
by Johan De Gelas on September 20, 2012 12:15 AM ESTTSX Performance
Ravi and Marting gave some vague but still rather interesting performance data:
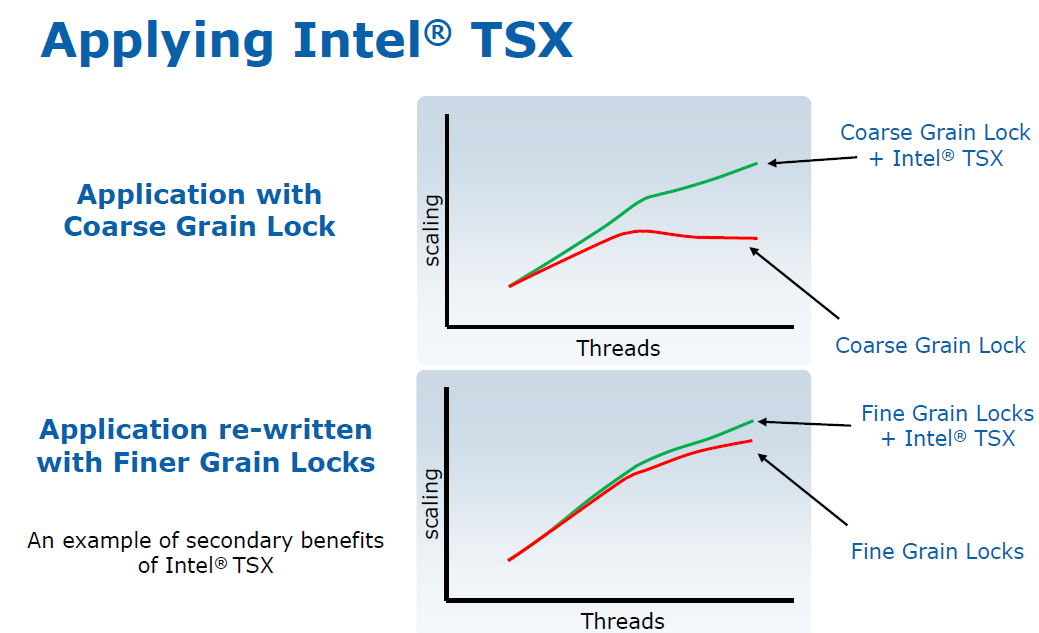
According to Intel, using an application that previously used a coarse grained lock (like the older MyISAM storage engines of MySQL) together with a TSX enabled library should improve scaling spectacularly. What's interesting is that even applications with finely grained locks should benefit from using TSX. As TSX uses the L1-cache to buffer the writes (David Kanter describes this in great detail here) and does not lock (unless re-execute/rollback takes place), there is less memory activity and especially less synchronization traffic. Or in other words, cache lines are less "thrown around".
There are some corner cases for which HLE/RTM will not work of course. The whole "CPU does the fine grained locks" is based upon tagging the L1 (64 B) cachelines and there are 512 of them to be specific (64 x 512 = 32 KB). There is only one "lock tag" per cacheline. More than one lock to the same cacheline will cause HLE/RTM to abort as the CPU cannot track the two locks separately in that case.
Second, all the "to be locked" variables of a TSX enabled piece of code must be placed into the L1-cache. If a piece of critical code needs to lock variables from more than 8 cachelines that all map to the slots of the same set, HLE is not going to work: the L1 is 8-way set-associative. Anything that interrupts the transaction will abort the transaction: non-maskable interrupts (interrupts that cannot be ignored), VM exits, faults...the list goes on. Still, there are many cases where TSX can definitely help, and code can be written to accommodate the requirements and limitations.
Conclusion
TSX will be supported by GCC v4.8, Microsoft's latest Visual Studio 2012, and of course Intel's C compiler v13. GLIBC support (rtm-2.17 branch) is also available. So it looks like the software ecosystem is ready for TSX. The coolest thing about TSX (especially HLE) is that it enables good scaling on our current multi-core CPUs without an enormous investment of time in the fine tuning of locks. In other words, it can give developers "fined grained performance at coarse grained effort" as Intel likes to put it.
In theory, most application developers will not even have to change their code besides linking to a TSX enabled library. Time will tell if unlocking good multi-core scaling will be that easy in most cases. If everything goes according to Intel's plan, TSX could enable a much wider variety of software to take advantage of the steadily increasing core counts inside our servers, desktops, and portables.








29 Comments
View All Comments
1008anan - Thursday, September 20, 2012 - link
Good summary Johan De Gelas. Look forward to future articles that further elaborate on how exactly Transactional Synchronization technology (TSX) achieves hardware accelerated transactional memory in a scalable generalized way.Part of the solution in my opinion is for a core that can have 2 or more simultaneous thread to only execute 1 thread at a time for single threaded computationally heavy work loads. To give an example, a single Haswell Corps can execute 32 single precision (32 bit) operations per clock. At 2 gigahertz SoC speed, a single Corps can execute 64 billion operations per second with single threaded code. Unfortunately this can only help so much. To make major performance gains an efficient generalized scalable way needs to be found to distribute single threaded computational work loads to multiple different cores. Much easier said than done.
extide - Saturday, September 22, 2012 - link
32 single precision ops is wrong. How many ops they can do per clock has to do with the front end and how many ports it has in it, not how many bits a particular instruction is.extide - Saturday, September 22, 2012 - link
to further that, Ivy Bridge has 6 ports and Haswell 8, but each of the ports don't necessarily have the same capabilities.twotwotwo - Thursday, September 20, 2012 - link
Very smart idea, very clever to implement it with backwards compatibility, and it's good that Intel's working out uses for die area that aren't just multiplying cores or cache.But a sad thing is, when this feature really helps your app, like doubles or triples throughput, then it means you must be leaving speed on the table on _other_ platforms--manycore Ivy Bridge or AMD or whatever--because you didn't take fine-grained locks. If the difference matters, then for many years you'll have to go to the effort to do fine-grained locks and make it fast on Ivy Bridge too.
The other thing is, the problem of parallelizing tasks is deeper than just fine-grained locks being tricky. If you want to make, say, a Web browser faster by taking advantage of multiple cores, you still have to do deep thinking and hard work to find tasks that can be split off, deal with dependencies, etc. Smart folks are trying to do that, but they _still_ have hard work when they're on systems with transactional memory.
That may be overly pessimistic. It's likely apps today _are_ leaving performance on the table by taking coarse locks for simplicity's sake, and they'll get zippier when TSX is dropped in. Or maybe transactional memory will be everywhere, or on all the massively multicore devices anyway, faster than I think. Or, finally, maybe Intel knows TSX won't have its greatest effects for a long time but is making a plan for the very long term like only Intel can.
Paul Tarnowski - Thursday, September 20, 2012 - link
I think it's the last one more than anything else. It really seems to be about setting up architecture for the future. Right now with four and eight cores the losses aren't that high, and effects won't be seen on anything but servers. While it is a big deal, it will be even less important to the consumer market than most other architecture extensions.USER8000 - Thursday, September 20, 2012 - link
This an article from them nearly three years ago:http://blogs.amd.com/developer/2009/11/17/the-velo...
NeBlackCat - Thursday, September 20, 2012 - link
I stopped reading at the end of the 2nd para after the bar chart on the first page:"The root of the locking problems is that locking is a trade-off. Suppose you have a shared data structure such as a small table or list. If the developer is time constrained, which is often the case, the easiest way to guarantee consistency is to let a certain thread lock the entire data structure (e.g. the table lock of MySQL MyISAM). The thread acquires the lock and then executes its code (the critical section). Meanwhile all other threads are blocked until the thread releases the lock on the structure (*). However, locking a piece of data is only necessary if two threads want to write to it. (**)"
(*) all other threads arent locked, only those that also need access to the same data.
(**) locking a piece of data is only *one* thread wants to write it (else you risk a reader reading it before the writer has finished writing it)
And if the first locker is doing something that may take (in CPU terms) considerable time, likely in the database scenario, then the OS will probably schedule something else (there are always other processes and threads wanting to run) on a core/hyperthread running a blocked thread, so it wont sit idle anyway.
Unless things have changed since I was a real time software engineer, anyway
Wardrop - Thursday, September 20, 2012 - link
I think your nitpicking. We all understand the locking problem (those of us that it's relevant to anyway). There's no point in the author going into more detail to clarify what we all should already know - he gives us enough information for us to at least know what he's talking about, and that was the point of that paragraph.JohanAnandtech - Thursday, September 20, 2012 - link
"all other threads arent locked, only those that also need access to the same data."With a bit of goodwill, you would accept that this is implied.
" then the OS will probably schedule something else "
Right. But it is no free lunch. In the case of a spinlock, there will several attempts to lock and then a context switch. That is thousands of cycles lost without doing any useful work. BTW if you really want to see some in depth cases, we linked to
http://www.anandtech.com/show/5279/the-opteron-627...
http://www.anandtech.com/show/5279/the-opteron-627...
which goes in a lot more detail.
gchernis - Thursday, September 20, 2012 - link
OP did not explain why software-transactional memory (STM) is good, before diving into Intel's hardware solution. Current breed of databases use STM, but so can other applications. The prerequisite is the assumption that there's much more reading than there's writing going on.