GTC 2012 Part 1: NVIDIA Announces GK104 Based Tesla K10, GK110 Based Tesla K20
by Ryan Smith on May 17, 2012 3:15 AM ESTThe other Tesla announced this week is Tesla K20, which is the first and so far only product announced that will be using GK110. Tesla K20 is not expected to ship until October-November of this year due to the fact that GK110 is still a work in progress, but since NVIDIA is once again briefing developers of the new capabilities of their leading compute GPU well ahead of time there’s little reason not to announce the card, particularly since they haven’t attached any solid specifications to it beyond the fact that it will be composed of a single GK110 GPU.

GK110 itself is a bit of a complex beast that we’ll get into more detail about later this week, but for now we’ll quickly touch upon some of the features that make GK110 the true successor to GF110. First and foremost of course, GK110 has all the missing features that GK104 lacked – ECC cache protection, high double precision performance, a wide memory bus, and of course a whole lot of CUDA Cores. Because GK110 is still in the lab NVIDIA doesn’t know what will be viable to ship later this year, but as it stands they’re expecting triple the double precision performance of Tesla M2090, with this varying some based on viable clockspeeds and how many functional units they can ship enabled. Single precision performance should also be very good, but depending on the application there’s a decent chance that K10 could beat K20, at least in the type of applications that are well suited for GK104’s limitations.
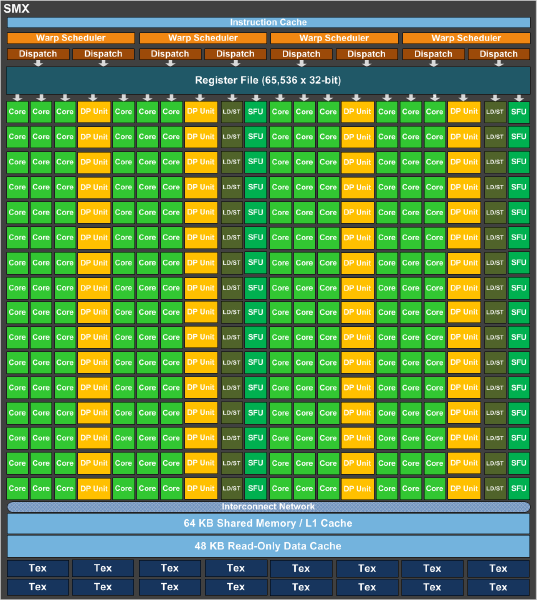
As it stands a complete GK110 is composed of 15 SMXes – note that these are similar but not identical to GK104 SMXes – bound to 1.5MB of L2 cache and a 384bit memory bus. GK110 SMXes will contain 192 CUDA cores (just like GK104), but deviating from GK104 they will contain 64 CUDA FP64 cores (up from 8, which combined with the much larger SMX count is what will make K20 so much more powerful at double precision math than K10. Of interesting note, NVIDIA is keeping the superscalar dispatch method that we first saw in GF104 and carried over to GK104, so unlike Fermi Tesla products, compute performance on K20 is going to be a little more erratic as a result of the fact that maximizing SMX utilization will require a high degree of both TLP and ILP.

Along with the slew of new features native to the Kepler family and some new Kepler family compute instructions being unlocked with CUDA 5, GK110/K20 will be bringing with it two major new features that are unique to just GK110: Hyper-Q and Dynamic Parallelism. We’ll go over both of these in depth in the near future with our look at GK110, but for the time being we’ll quickly touch on what each of them does.
Hyper-Q is NVIDIA’s name for the expansion of the number of work queues in the GPU. With Fermi NVIDIA’s hardware only supported 1 hardware work queue, whereas GK110 will support 32 work queues. The important fact to take away from this is that 1 work queue meant that Fermi could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.


The other major new feature here was Dynamic Parallelism, which is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.
Wrapping things up, there are a few other features new to GK110 such as a new grid management unit, RDMA, and a new ISA encoding scheme, all of which are intended to further improve NVIDIA’s compute performance, both over Fermi and even GK104. But we’ll save these for another day when we look at GK110 in depth.








51 Comments
View All Comments
Malphas - Thursday, May 17, 2012 - link
They'll most likely just release them as the 700 series at the tail end of this year.Musafir_86 - Thursday, May 17, 2012 - link
-They directly go with GK110? Where's GK100? Shouldn't it be released first as with Fermi (GF100 -> GF110)?Regards.
gplnpsb - Thursday, May 17, 2012 - link
Presumably there was a GK100 design that was cancelled for whatever reason. If it ever taped out (presumably around late summer of last year, around the same time as the GK104 tape out), nVidia may have realized it would be unmanufacturable on TSMCs 28nm process as it was.Rumor has it that GK110 taped out in January of this year. Perhaps nVidia had to go back and optimize the chip for yields and clock speeds once they got enough experience with the idiosyncrasies of the 28nm process.
tipoo - Thursday, May 17, 2012 - link
From Nvidias own website, it seems like these cards are far weaker than Fermi at DP operations, even with two chips it doesn't match the single chip older Fermi oneshttp://www.nvidia.com/object/tesla-servers.html
190 Gigaflops for the K10 with two GPUs, 665 and 515 for the older Fermi cards. Hmm. I thought only the consumer Geforce versions would have such cut down compute performance, but I guess it's inherent in the architecture.
Ryan Smith - Thursday, May 17, 2012 - link
To be precise, it's GK104 that has weak DP (1/24). GK110 is much better, it's 1/3, which is actually a bit lower than GF110 which was 1/2.tipoo - Thursday, May 17, 2012 - link
So the full (gk110) part would be around 1500Gflops DP if it's 1/3, or is there more to it than that?tipoo - Thursday, May 17, 2012 - link
Wait nevermind, that would be if it performed the same as the dual chip 104 which it probably won't. Do we have any idea what the DP performance of GK110 would be like then?tipoo - Thursday, May 17, 2012 - link
We need an edit button just for me, heh. Nvidias slide says the k10 is 3x the single precision performance as todays cards, the k20 is 3x the DP. So 1500Gflops is pretty close, and the rumours say 1.5Tflops too so that's a good bet I guess.Ryan Smith - Thursday, May 17, 2012 - link
NVIDIA's official guideance is >1TFLOP real performance, which is a combination of the increased number of functional units and increased efficiency on GK110.PsiAmp - Saturday, May 19, 2012 - link
If GK110 has the same clocks as GK104 then it is ~1.43 TFLOPS DP. Nvidia stated that it has ~1 TFLOPS DP performance. They can't know it yet, because chip is too far for mass production state.