NVIDIA GeForce GTX 680 Review: Retaking The Performance Crown
by Ryan Smith on March 22, 2012 9:00 AM ESTThe Kepler Architecture: Efficiency & Scheduling
So far we’ve covered how NVIDIA has improved upon Fermi for; now let’s talk about why.
Mentioned quickly in our introduction, NVIDIA’s big push with Kepler is efficiency. Of course Kepler needs to be faster (it always needs to be faster), but at the same time the market is making a gradual shift towards higher efficiency products. On the desktop side of matters GPUs have more or less reached their limits as far as total power consumption goes, while in the mobile space products such as Ultrabooks demand GPUs that can match the low power consumption and heat dissipation levels these devices were built around. And while strictly speaking NVIDIA’s GPUs haven’t been inefficient, AMD has held an edge on performance per mm2 for quite some time, so there’s clear room for improvement.
In keeping with that ideal, for Kepler NVIDIA has chosen to focus on ways they can improve Fermi’s efficiency. As NVIDIA's VP of GPU Engineering, Jonah Alben puts it, “[we’ve] already built it, now let's build it better.”
There are numerous small changes in Kepler that reflect that goal, but of course the biggest change there was the removal of the shader clock in favor of wider functional units in order to execute a whole warp over a single clock cycle. The rationale for which is actually rather straightforward: a shader clock made sense when clockspeeds were low and die space was at a premium, but now with increasingly small fabrication processes this has flipped. As we have become familiar with in the CPU space over the last decade, higher clockspeeds become increasingly expensive until you reach a point where they’re too expensive – a point where just distributing that clock takes a fair bit of power on its own, not to mention the difficulty and expense of building functional units that will operate at those speeds.
With Kepler the cost of having a shader clock has finally become too much, leading NVIDIA to make the shift to a single clock. By NVIDIA’s own numbers, Kepler’s design shift saves power even if NVIDIA has to operate functional units that are twice as large. 2 Kepler CUDA cores consume 90% of the power of a single Fermi CUDA core, while the reduction in power consumption for the clock itself is far more dramatic, with clock power consumption having been reduced by 50%.

Of course as NVIDIA’s own slide clearly points out, this is a true tradeoff. NVIDIA gains on power efficiency, but they lose on area efficiency as 2 Kepler CUDA cores take up more space than a single Fermi CUDA core even though the individual Kepler CUDA cores are smaller. So how did NVIDIA pay for their new die size penalty?
Obviously 28nm plays a significant part of that, but even then the reduction in feature size from moving to TSMC’s 28nm process is less than 50%; this isn’t enough to pack 1536 CUDA cores into less space than what previously held 384. As it turns out not only did NVIDIA need to work on power efficiency to make Kepler work, but they needed to work on area efficiency. There are a few small design choices that save space, such as using 8 SMXes instead of 16 smaller SMXes, but along with dropping the shader clock NVIDIA made one other change to improve both power and area efficiency: scheduling.
GF114, owing to its heritage as a compute GPU, had a rather complex scheduler. Fermi GPUs not only did basic scheduling in hardware such as register scoreboarding (keeping track of warps waiting on memory accesses and other long latency operations) and choosing the next warp from the pool to execute, but Fermi was also responsible for scheduling instructions within the warps themselves. While hardware scheduling of this nature is not difficult, it is relatively expensive on both a power and area efficiency basis as it requires implementing a complex hardware block to do dependency checking and prevent other types of data hazards. And since GK104 was to have 32 of these complex hardware schedulers, the scheduling system was reevaluated based on area and power efficiency, and eventually stripped down.
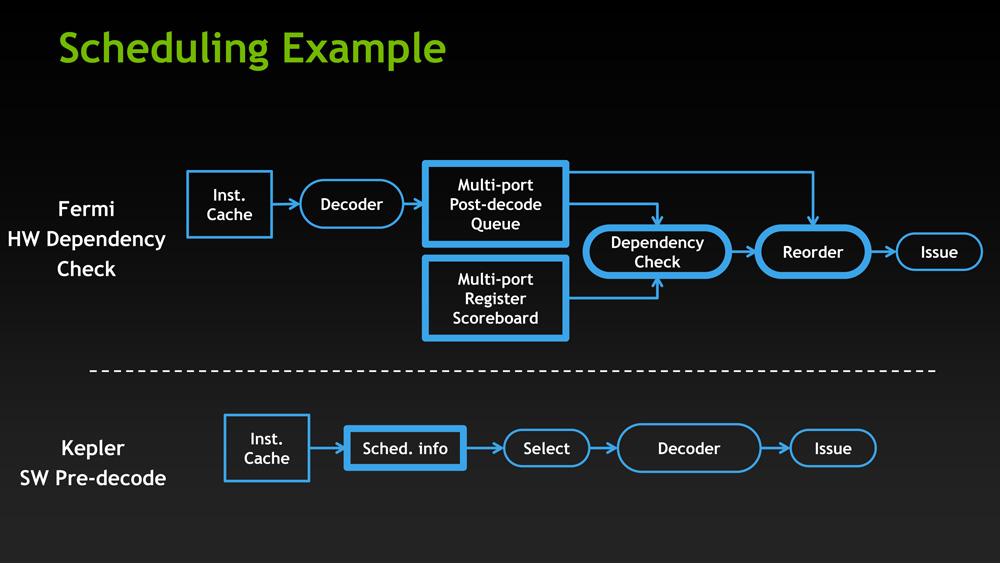
The end result is an interesting one, if only because by conventional standards it’s going in reverse. With GK104 NVIDIA is going back to static scheduling. Traditionally, processors have started with static scheduling and then moved to hardware scheduling as both software and hardware complexity has increased. Hardware instruction scheduling allows the processor to schedule instructions in the most efficient manner in real time as conditions permit, as opposed to strictly following the order of the code itself regardless of the code’s efficiency. This in turn improves the performance of the processor.
However based on their own internal research and simulations, in their search for efficiency NVIDIA found that hardware scheduling was consuming a fair bit of power and area for few benefits. In particular, since Kepler’s math pipeline has a fixed latency, hardware scheduling of the instruction inside of a warp was redundant since the compiler already knew the latency of each math instruction it issued. So NVIDIA has replaced Fermi’s complex scheduler with a far simpler scheduler that still uses scoreboarding and other methods for inter-warp scheduling, but moves the scheduling of instructions in a warp into NVIDIA’s compiler. In essence it’s a return to static scheduling.
Ultimately it remains to be seen just what the impact of this move will be. Hardware scheduling makes all the sense in the world for complex compute applications, which is a big reason why Fermi had hardware scheduling in the first place, and for that matter why AMD moved to hardware scheduling with GCN. At the same time however when it comes to graphics workloads even complex shader programs are simple relative to complex compute applications, so it’s not at all clear that this will have a significant impact on graphics performance, and indeed if it did have a significant impact on graphics performance we can’t imagine NVIDIA would go this way.
What is clear at this time though is that NVIDIA is pitching GTX 680 specifically for consumer graphics while downplaying compute, which says a lot right there. Given their call for efficiency and how some of Fermi’s compute capabilities were already stripped for GF114, this does read like an attempt to further strip compute capabilities from their consumer GPUs in order to boost efficiency. Amusingly, whereas AMD seems to have moved closer to Fermi with GCN by adding compute performance, NVIDIA seems to have moved closer to Cayman with Kepler by taking it away.
With that said, in discussing Kepler with NVIDIA’s Jonah Alben, one thing that was made clear is that NVIDIA does consider this the better way to go. They’re pleased with the performance and efficiency they’re getting out of software scheduling, going so far to say that had they known what they know now about software versus hardware scheduling, they would have done Fermi differently. But whether this only applies to consumer GPUs or if it will apply to Big Kepler too remains to be seen.








404 Comments
View All Comments
sngbrdb - Friday, March 30, 2012 - link
*from : PMombasa69 - Wednesday, April 4, 2012 - link
This is just a rebadged mid-range card, the 680 has less memory bandwidth than GPU's brought out 4 years ago lol, what a ripp, I can see the big fat directors at Nvidia laughing at all the mugs that have gone out and bought one, thinking this is the real big boy to replace the 580... muppets. lol.N4v1N - Wednesday, April 4, 2012 - link
Nvidia is the bestest! No AMD is the betterest!lol...
CeriseCogburn - Friday, April 6, 2012 - link
Yes Nvidia clocked the ram over 6Ghz because their ram controller is so rockin'.In any case, the 7970 is now being overclocked, both are to 7000Ghz ram.
Unfortunately the 7970 still winds up behind most of the time, even in 2650X1200 screen triple gaming.
raghu78 - Saturday, April 7, 2012 - link
In the Reference Radeon HD 7970 AND XFX RADEON HD 7970 review the DirectX 11 compute shader Fluid simulation perfomance is far more than in this review.http://www.anandtech.com/show/5261/amd-radeon-hd-7...
http://www.anandtech.com/show/5314/xfxs-radeon-hd-...
http://images.anandtech.com/graphs/graph5314/43383...
Reference HD 7970 -133 and XFX HD 7970 -145 . In this review Reference HD 7970 -115.5
What has changed in between these reviews. Is it that performance has actually decreased with the latest drivers
oddnutz - Thursday, April 12, 2012 - link
well i have been an ATI fanboi forever. So I am due a gfx upgrade which would of already happened if ATI priced their latest cards similar to previous generations. I will watch ATI prices over the next few weeks but it looks like i might be turning green soon.blanarahul - Friday, April 13, 2012 - link
Actually the GTX 680 REFERENCE BOARD was designed for 375 Watts of power.It has a total of 2 6-pin and one 8-pin connector on the board! I realized this after seeing the back of the board.
Commander Bubble - Thursday, April 19, 2012 - link
I agree with some of the sensible posts littered in here that Witcher 2 should be included as a comparison point, and most notably the ubersampling setup.i run 2x 580GTX SLI @1920 and i can't manage a minimum 60fps with that turned on. That would be a good test for current cards as it absoultely hammers them.
also, i don't know whether CeriseCogburn is right or wrong, and i don't care, but i'm just sick of seeing his name in the comment list. go outside and meet people, do something else. you are clearly spending way too much time on here...
beiker44 - Tuesday, April 24, 2012 - link
I can't wait to get one...or wait for the bad ace Dual 690!!! decisions decisionsOxford Guy - Thursday, July 5, 2012 - link
"At the end of the day NVIDIA already had a strong architecture in Fermi, so with Kepler they’ve gone and done the most logical thing to improve their performance: they’ve simply doubled Fermi."Fermi Lite, you mean.
"Now how does the GTX 680 fare in load noise? The answer depends on what you want to compare it to. Compared to the GTX 580, the GTX 680 is practically tied – no better and no worse – which reflects NVIDIA’s continued use of a conservative cooling strategy that favors noise over temperatures."
No, the 680's cooling performance is inferior because it doesn't use a vapor chamber. Nvidia skimped on the cooling to save money, it seems.