NVIDIA GeForce GTX 680 Review: Retaking The Performance Crown
by Ryan Smith on March 22, 2012 9:00 AM ESTThe Kepler Architecture: Fermi Distilled
As GPU complexity has increased over the years, so has the amount of time it takes to design a GPU. Specific definitions vary on what constitutes planning, but with modern GPUs such as Fermi, Kepler, and Tahiti planning basically starts 4+ years ahead of time. At this point in time GPUs have a similarly long development period as CPUs, and that alone comes with some ramifications.
The biggest ramification of this style of planning is that because designing a GPU is such a big undertaking, it’s not something you want to do frequently. In the CPU space Intel has their tick-tock strategy, which has Intel making incremental architecture updates every 2 years. While in the GPU space neither NVIDIA or AMD have something quite like that – new architectures and new process nodes still tend to premiere together – there is a similar need to spread out architectures over multiple years.
For NVIDIA, Kepler is the embodiment of that concept. Kepler brings with it some very important architectural changes compared to Fermi, but at the same time it’s still undeniably Fermi. From a high level overview Kepler is identical to Fermi: it’s still organized into CUDA cores, SMs, and GPCs, and how warps are executed has not significantly changed. Nor for that matter has the rendering side significantly changed, with rendering still being handled in a distributed fashion through raster engines, polymorph engines, and of course the ROPs. The fact that NVIDIA has chosen to draw up Kepler like Fermi is no accident or coincidence; at the end of the day Kepler is the next generation of Fermi, tweaked and distilled to improve on Fermi’s strengths while correcting its weaknesses.
For our look at Kepler’s architecture, we’re going to be primarily comparing it to GF114, aka Fermi Lite. As you may recall, with Fermi NVIDIA had two designs: a multipurpose architecture for gaming and graphics (GF100/GF110), and a streamlined architecture built with a stronger emphasis on graphics than compute (GF104, etc) that was best suited for use in consumer graphics. As hinted at by the name alone, GK104 is designed to fill the same consumer graphics role as GF114, and consequently NVIDIA built GK104 off of GF114 rather than GF110.
So what does GK104 bring to the table? Perhaps it’s best to start with the SMs, as that’s where most of the major changes have happened.
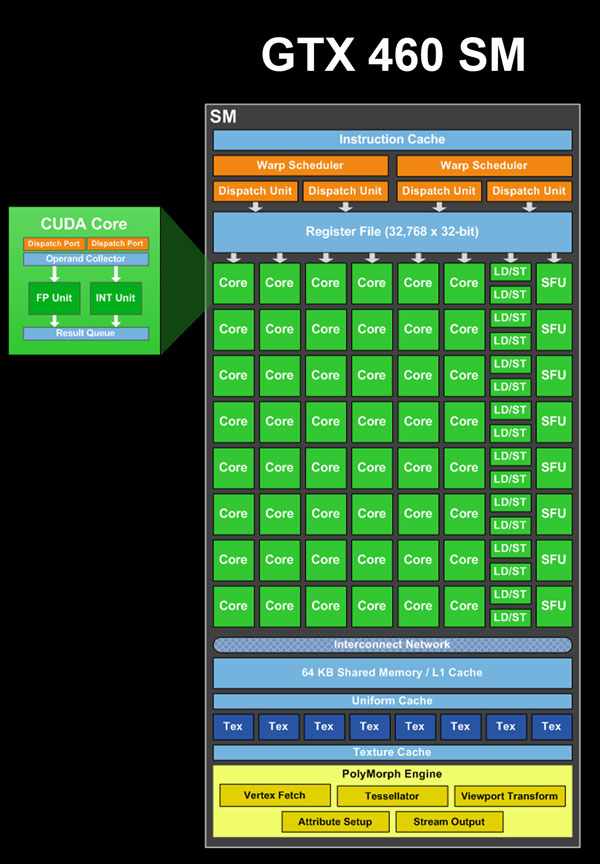
In GF114 each SM contained 48 CUDA cores, with the 48 cores organized into 3 groups of 16. Joining those 3 groups of CUDA cores were 16 load/store units, 16 interpolation SFUs, 8 special function SFUs, and 8 texture units. Feeding all of those blocks was a pair of warp schedulers, each of which could issue up to 2 instructions per core clock cycle, for a total of up to 4 instructions in flight at any given time.
GF104/GF114 SM Functional Units
- 16 CUDA cores (#1)
- 16 CUDA cores (#2)
- 16 CUDA cores, FP64 capable (#3)
- 16 Load/Store Units
- 16 Interpolation SFUs (not on NVIDIA's diagrams)
- 8 Special Function SFUs
- 8 Texture Units
Within the SM itself different units operated on different clocks, with the schedulers and texture units operating on the core clock, while the CUDA cores, load/store units, and SFUs operated on the shader clock, which ran at twice the core clock. As NVIDIA’s warp size is 32 threads, if you do the quick math you realize that warps are twice as large as any block of functional units, which is where the shader clock comes in. With Fermi, a warp would be split up and executed over 2 cycles of the shader clock; 16 threads would go first, and then the other 16 threads over the next clock. The shader clock is what allowed NVIDIA to execute a full warp over a single graphics clock cycle while only using enough hardware for half of a warp.
So how does GK104 change this? The single most important aspect of GK104, the thing that in turn dictates the design of everything else, is that NVIDIA has dropped the shader clock. Now the entire chip, from ROP to CUDA core, runs on the same core clock. As a consequence, rather than executing two half-warps in quick succession GK104 is built to execute a whole warp at once, and GK104’s hardware has changed dramatically as a result.
Because NVIDIA has essentially traded a fewer number of higher clocked units for a larger number of lower clocked units, NVIDIA had to go in and double the size of each functional unit inside their SM. Whereas a block of 16 CUDA cores would do when there was a shader clock, now a full 32 CUDA cores are necessary. The same is true for the load/store units and the special function units, all of which have been doubled in size in order to adjust for the lack of a shader clock. Consequently, this is why we can’t just immediately compare the CUDA core count of GK104 and GF114 and call GK104 4 times as powerful; half of that additional hardware is just to make up for the lack of a shader clock.
But of course NVIDIA didn’t stop there, as swapping out the shader clock for larger functional units only gives us the same throughput in the end. After doubling the size of the functional units in a SM, NVIDIA then doubled the number of functional units in each SM in order to grow the performance of the SM itself. 3 groups of CUDA cores became 6 groups of CUDA cores, 2 groups of load/store units, 16 texture units, etc. At the same time, with twice as many functional units NVIDIA also doubled the other execution resources, with 2 warp schedulers becoming 4 warp schedulers, and the register file being doubled from 32K entries to 64K entries.
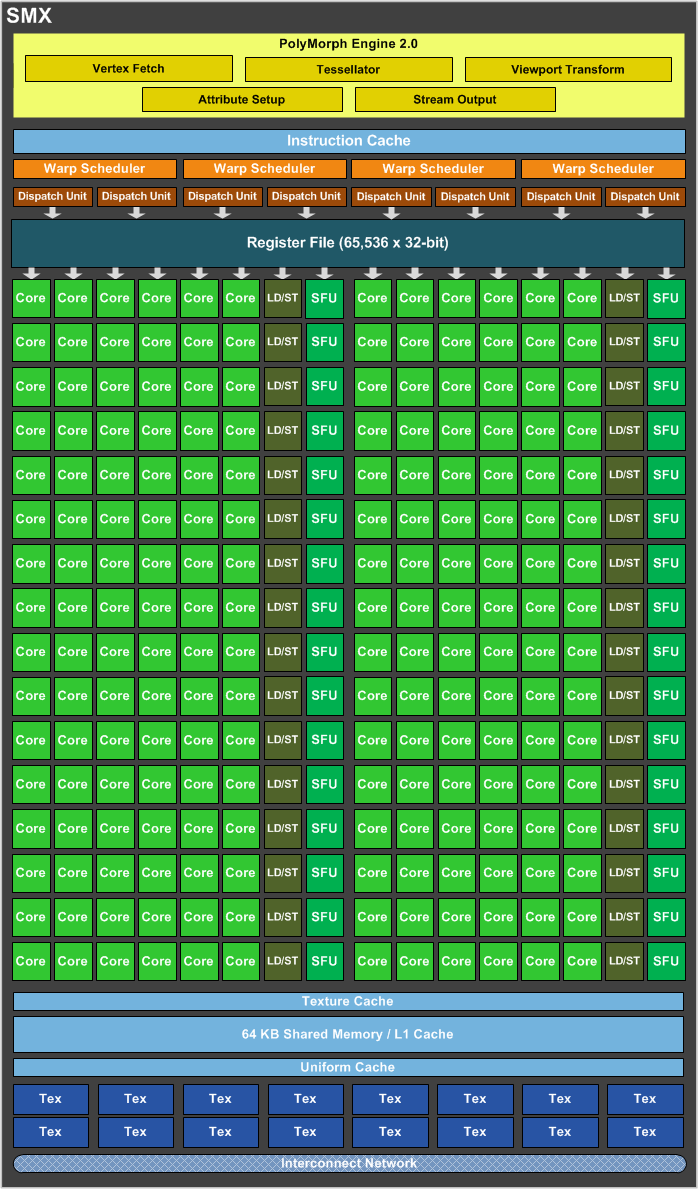
Ultimately where the doubling of the size of the functional units allowed NVIDIA to drop the shader clock, it’s the second doubling of resources that makes GK104 much more powerful than GF114. The SMX is in nearly every significant way twice as powerful as a GF114 SM. At the end of the day NVIDIA already had a strong architecture in Fermi, so with Kepler they’ve gone and done the most logical thing to improve their performance: they’ve simply doubled Fermi.
Altogether the SMX now has 15 functional units that the warp schedulers can call on. Each of the 4 schedulers in turn can issue up to 2 instructions per clock if there’s ILP to be extracted from their respective warps, allowing the schedulers as a whole to issue instructions to up to 8 of the 15 functional units in any clock cycle.
GK104 SMX Functional Units
- 32 CUDA cores (#1)
- 32 CUDA cores (#2)
- 32 CUDA cores (#3)
- 32 CUDA cores (#4)
- 32 CUDA cores (#5)
- 32 CUDA cores (#6)
- 16 Load/Store Units (#1)
- 16 Load/Store Units (#2)
- 16 Interpolation SFUs (#1)
- 16 Interpolation SFUs (#2)
- 16 Special Function SFUs (#1)
- 16 Special Function SFUs (#2)
- 8 Texture Units (#1)
- 8 Texture Units (#2)
- 8 CUDA FP64 cores
While that covers the operation of the SMX in a nutshell, there are a couple of other things relating to the SMX that need to be touched upon. Because NVIDIA still only has a single Polymorph Engine per SMX, the number of Polymorph Engines hasn’t been doubled like most of the other hardware in an SMX. Instead the capabilities of the Polymorph Engine itself have been doubled, making each Polymorph Engine 2.0 twice as powerful as a GF114 Polymorph Engine. In absolute terms, this means each Polymorph Engine can now spit out a polygon in 2 cycles, versus 4 cycles on GF114, for a total of 4 polygons/clock across GK104.
The other change coming from GF114 is the mysterious block #15, the CUDA FP64 block. In order to conserve die space while still offering FP64 capabilities on GF114, NVIDIA only made one of the three CUDA core blocks FP64 capable. In turn that block of CUDA cores could execute FP64 instructions at a rate of ¼ FP32 performance, which gave the SM a total FP64 throughput rate of 1/12th FP32. In GK104 none of the regular CUDA core blocks are FP64 capable; in its place we have what we’re calling the CUDA FP64 block.
The CUDA FP64 block contains 8 special CUDA cores that are not part of the general CUDA core count and are not in any of NVIDIA’s diagrams. These CUDA cores can only do and are only used for FP64 math. What's more, the CUDA FP64 block has a very special execution rate: 1/1 FP32. With only 8 CUDA cores in this block it takes NVIDIA 4 cycles to execute a whole warp, but each quarter of the warp is done at full speed as opposed to ½, ¼, or any other fractional speed that previous architectures have operated at. Altogether GK104’s FP64 performance is very low at only 1/24 FP32 (1/6 * ¼), but the mere existence of the CUDA FP64 block is quite interesting because it’s the very first time we’ve seen 1/1 FP32 execution speed. Big Kepler may not end up resembling GK104, but if it does then it may be an extremely potent FP64 processor if it’s built out of CUDA FP64 blocks.
Moving on, now that we’ve dissected GK104’s SMX, let’s take a look at the bigger picture. Above the SM(X)es we have the GPCs. The GPCs contain multiple SMs and more importantly the Raster Engine responsible for all rasterization. As with the many other things being doubled in GK104, the number of GPCs has been doubled from 2 to 4, thereby doubling the number of Raster Engines present. This in turn changes the GPC-to-SM(X) ratio from 1:4 on GF114 to 1:2 on GK104. The ratio itself is not particularly important, but it’s worth noting that it does take more work for NVIDIA to lay down and connect 4 GPCs than it does 2 GPCs.
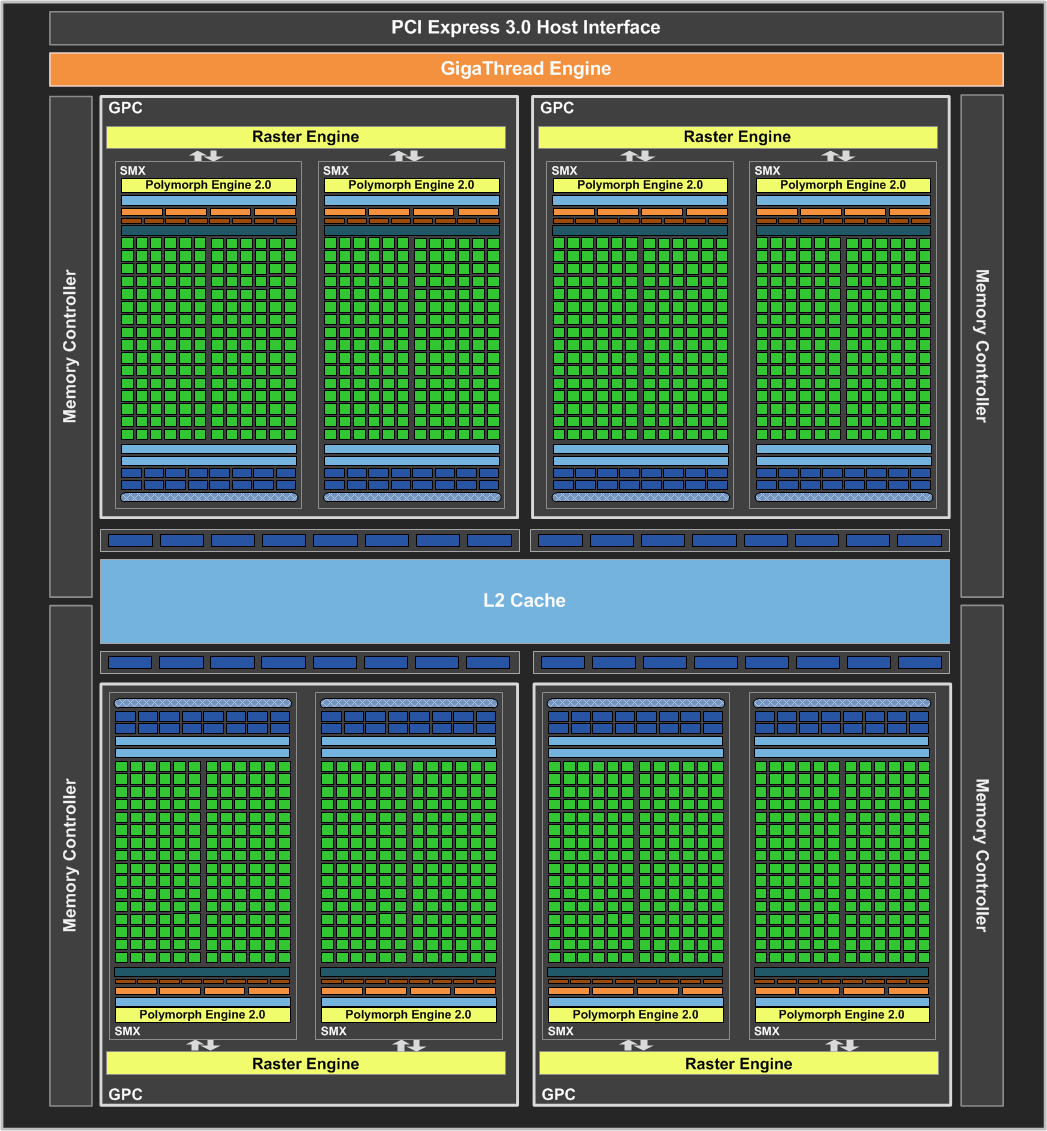
Last, but certainly not least is the complete picture. The 4 GPCs are combined with the rest of the hardware that makes GK104 tick, including the ROPs, the memory interfaces, and the PCIe interface. The ROPs themselves are virtually identical to those found on GF114; theoretical performance is the same, and at a lower level the only notable changes are an incremental increase in compression efficiency, and improved polygon merging. Similarly, the organization of the ROPs has not changed either, as the ROPs are still broken up into 4 blocks of 8, with each ROP block tied to a 64 bit memory controller and 128KB of L2 cache. Altogether there are 32 ROPs, giving us 512KB of L2 cache and a 256bit memory bus.
On a final tangent, the memory controllers ended up being an unexpected achievement for NVIDIA. As you may recall, Fermi’s memory controllers simply never reached their intended targets – NVIDIA hasn’t told us what those targets were, but ultimately Fermi was meant to reach memory clocks higher than 4GHz. With GK104 NVIDIA has improved their memory controllers and then some. GK104’s memory controllers can clock some 50% higher than GF114’s, leading to GTX 680 shipping at 6GHz.
On a technical level, getting to 6GHz is hard, really hard. GDDR5 RAM can reach 7GHz and beyond on the right voltage, but memory controllers and the memory bus are another story. As we have mentioned a couple of times before, the memory bus tends to give out long before anything else does, which is what’s keeping actual shipping memory speeds well below 7GHz. With GK104 NVIDIA’s engineers managed to put together a chip and board that are good enough to run at 6GHz, and this alone is quite remarkable given how long GDDR5 has dogged NVIDIA and AMD.
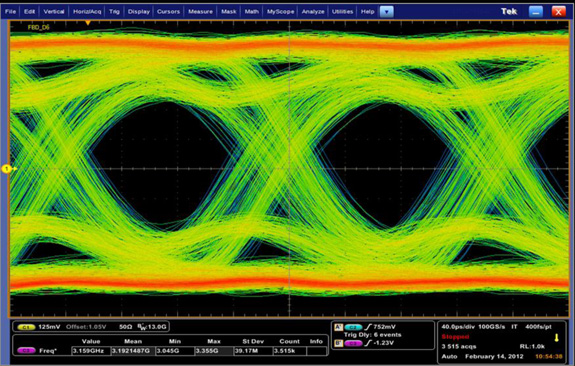
GK104 GDDR5 Signal Analysis
Perhaps the icing on the cake for NVIDIA though is how many revisions it took them to get to 6GHz: one. NVIDIA was able to get 6GHz on the very first revision of GK104, which after Fermi’s lackluster performance is a remarkable turn of events. And ultimately while NVIDIA says that they’re most proud of the end result of GK104, the fact of the matter is that everyone seems just a bit prouder of their memory controller, and for good reason.








404 Comments
View All Comments
SlyNine - Sunday, March 25, 2012 - link
Well, the driver themself can take more CPU power to run. But with a quad core CPU the thought is laughable. Back in the single CPU/core days it was actually an issue. And before DX9 (or 10) Drivers were only capable of accessing single cores I believe.SlyNine - Sunday, March 25, 2012 - link
Then look for an overclocked review. Anandtech is always going to do an out of the box for the first review.This is what they(amd/nvidia) are promising you, nothing more.
papapapapapapapababy - Monday, March 26, 2012 - link
USELESS !YESSS OMFG i cant wait to play the latest crappy kinect port with this!.... at 600.000.000 FPS and in 3-D! GTFO GUYS! REALLY....
just put this ridiculously large, ugly, noisy, silly, and overpriced, toxic waste where it belongs: faaar away from me, ( sensible user) inside one bulky OnLive cloud server. (and pushing avatar 2 graphics, no HDps2 ports)
henrikfm - Monday, March 26, 2012 - link
Most monitors have 60Hz refresh rate, you can't benefit from higher frame rates because only 60 frames are drawn.By looking at the benchmarks and considering a resolution of 1920, the latest cards fail in 3 games to deliver at least 60fps: Crysis, Metro and BF3. In the first two games the HD7970 beats de GTX680, only loses in BF3 where nVidia has a clear advantage (in my opinion AMD has to work in drivers for BF3).
So, the GTX680 is faster when the speed really doesn't matter because you're already around 100fps. The guys who are running multiple monitors and higher resolutions will have also money to buy multiple GPU setups, and that is another story.
Still the GTX680 is a better card, but for $500 I would expect a card to deliver at least 60fps at 1920 for a 2008 released videogame like Crysis. Neither nVidia nor AMD can do that with a single GPU, it's disappointing.
gramboh - Monday, March 26, 2012 - link
I'll agree about Metro because there is a sequel (Last Light) coming out in Q1-2013 which will presumably be similar in the graphics department.Crysis is irrelevant other than for benchmarking, who still plays it? Single player campaign is entertaining for the eye candy once through (in 2008).
BF3 is the game that matters because of the MP component, people will be playing it for years to come. AMD really really has to improve performance on the 7950/7970 in BF3, I won't even consider buying it (vs. the 680) unless they can make up some significant ground.
CeriseCogburn - Tuesday, March 27, 2012 - link
I just have to do it, sorry.You forgot Shogun 2 total war, the hardest game in this bench set, that Nvidia wins in all 3 resolutions.
You also forgot average frames are not low frames, so you need far above 60 fps average before you don't dip below 60 fps.
Furthermore, all the eye candy is not cranked, driving the average and dips even lower when it is.
You got nothing right.
b3nzint - Monday, March 26, 2012 - link
back in 7970 review, its got cool stuffs tech. like PRT, MST hubm, DDMA and bla bla bla. why gtx680 dont have sh** like that. pardon my english. its like this thing is built only for 1 purpose only and thats a success. thanksmpx - Monday, March 26, 2012 - link
This new Nvidia card supposedly has an architecture that burdens CPU with scheduling etc. It may mean that it requires a faster CPU than ATI cards to reach similar performance. And since fast CPUs are expansive it may mean it's actually more expansive.BoFox - Monday, March 26, 2012 - link
The key word in your first sentence is "supposedly".I see no evidence of this. It actually does far better in Starcraft 2, a game that already burdens the CPU. It also excels in Skyrim, while still doing just fine in Civilization V, which are also the most CPU-intensive games out there.
BoFox - Monday, March 26, 2012 - link
In SC2 which is a very CPU-dependent game, the card still does amazingly well against the rest of others. The same also goes for Skyrim, beating the red team by a whopping percentage.