A Look at Enterprise Performance of Intel SSDs
by Anand Lal Shimpi on February 8, 2012 6:36 PM EST- Posted in
- Storage
- IT Computing
- SSDs
- Intel
Enterprise Storage Bench - Oracle Swingbench
We begin with a popular benchmark from our server reviews: the Oracle Swingbench. This is a pretty typical OLTP workload that focuses on servers with a light to medium workload of 100 - 150 concurrent users. The database size is fairly small at 10GB, however the workload is absolutely brutal.
Swingbench consists of over 1.28 million read IOs and 3.55 million writes. The read/write GB ratio is nearly 1:1 (bigger reads than writes). Parallelism in this workload comes through aggregating IOs as 88% of the operations in this benchmark are 8KB or smaller. This test is actually something we use in our CPU reviews so its queue depth averages only 1.33. We will be following up with a version that features a much higher queue depth in the future.
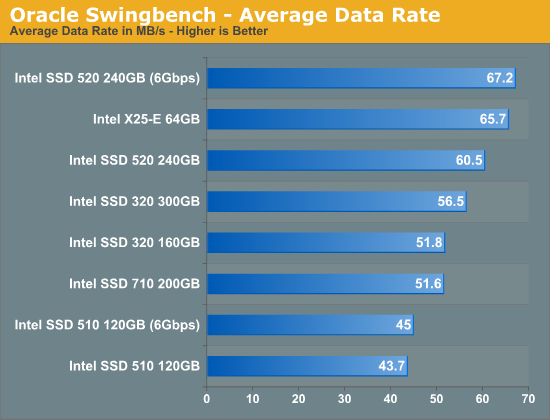
SLC NAND offers great write latency and we see a definite advantage to the older drive here in our Swingbench test. Only a 6Gbps SSD 520 is able to deliver better performance, everything else trails the 3+ year old drive. Note that the Marvell based Intel SSD 510, even on a 6Gbps controller, is the slowest drive in Intel's lineup. From a write amplification perspective, Marvell's controller has always been significantly behind Intel's own creations so the drop in performance isn't surprising. The 710 actually delivers performance that's lower than the 320, but you do get much better endurance out of the 710.


While throughput isn't much better on the 6Gbps Intel SSD 520, average service time is tangibly lower. There's clearly a benefit to higher bandwidth IO interfaces in the enterprise space, which is a big reason we're seeing a tremendous push for PCIe based SSDs. The 710 does well here but not nearly as well as the X25-E which continues to behave like a modern SSD thanks to its SLC NAND.








55 Comments
View All Comments
ckryan - Thursday, February 9, 2012 - link
Very true. And again, many 60/64GB could do 1PB with an entirely sequential workload. Under such conditions, most non-SF drives typically experience a WA of 1.10 to 1.20.Reality has a way of biting you in the ass, so in reality, be conservative and reasonable about how long a drive will last.
No one will throw a parade if a drive lasts 5 years, but if it only lasts 3 you're gonna hear about it.
ckryan - Thursday, February 9, 2012 - link
The 40GB 320 failed with almost 700TB, not 400. Remember though, the workload is mostly sequential. That particular 320 40GB also suffered a failure of what may have been an entire die last year, and just recently passed on to the SSD afterlife.So that's pretty reassuring. The X25-V is right around 700TB now, and it's still chugging along.
eva2000 - Thursday, February 9, 2012 - link
Would be interesting to see how consumer drives in the tests and life expectancy if they are configured with >40% over provisioning.vectorm12 - Thursday, February 9, 2012 - link
Thanks for the insight into this subject Anand.However I am curios as to why controller manufacturers haven't come up with a controller to manage cell-wear across multiple drives without raid.
Basically throw more drives at a problem. As you would be to some extent be mirroring most of your P/E cycles in a traditional raid I feel there should be room for an extra layer of management. For instance having a traditional raid 1 between two drive and keeping another one or two as "hot spare" for when cells start to go bad.
After all if you deploy SSD in raid you're likely to be subjecting them to a similar if not identical number of P/E cycles. This would force you to proactively switch out drives(naturally most would anyway) in order to guarantee you won't be subjected to a massive, collective failure of drives risking loss of data.
Proactive measures are the correct way of dealing with this issue but in all honesty I love "set and forget" systems more than anything else. If a drive has exhausted it's NAND I'd much rather get an email from a controller telling me to replace the drive and that it's already handled the emergency by allocating data to a spare drive.
Also I'm still seeing 320 8MB-bugg despite running the latest firmware in a couple of servers hosting low access-rate files for some strange reason. It seems as though they behave fine as long as the are constantly stressed but leave them idle for too long and things start to go wrong. Have you guys observed anything like this behavior?
Kristian Vättö - Thursday, February 9, 2012 - link
I've read some reports of the 8MB bug persisting even after the FW update. Your experience sounds similar - problems start to occur when you power off the SSD (i.e. power cycling). A guy I know actually bought the 80GB model just to try this out but unfortunately he couldn't make it repeatable.vectorm12 - Monday, February 13, 2012 - link
Unfortunately I'm in the same boat. 320s keep failing left and right(up to three now) all running latest firmware. However the issues aren't directly related to powercycles as these drives run 24/7 without any offtime.I've made sure drive-spinndown is deactivated as well as all other powermanagement features I could think of. I've also move the RAIDs from Adaptec controllers to the integrated SAS-controllers and still had a third drive fail.
I've actually switched out the remaining 320s for Samsung 830s now to see how they behave in this configuration.
DukeN - Thursday, February 9, 2012 - link
One with RAID'd drives, whether on a DAS or a high end SAN?Would love to see how 12 SSDs in (for argument's sake) an MSA1000 compare to 12 15K SAS drives.
TIA
ggathagan - Thursday, February 9, 2012 - link
Compare in what respect?FunBunny2 - Thursday, February 9, 2012 - link
Anand:I've been thinking about the case where using SSD, which has calculable (sort of, as this piece describes) lifespan, as swap (linux context). Have you done (and I can't find) or considering doing, such an experiment? From a multi-user, server perspective, the bang for the buck might be very high.
varunkrish - Thursday, February 9, 2012 - link
I have recently seen 2 SSDs fail without warning and they are completely not detected currently. While I love the performance gains from an SSD , lower noise and cooler operation, i feel you have to be more careful while storing critical data on a SSD as recovery is next to impossible.I would love to see an article which addresses SSDs from this angle.