AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Image Quality: Anisotropic Filtering Tweaks & Tessellation Speed
Since the launch of Evergreen AMD has continued to tweak their anisotropic filtering quality. Evergreen introduced angle-independent filtering, and with the 6000 series AMD tweaked their AF algorithm to better handle high frequency textures. With Southern Islands that trend continues with another series of tweaks.
For Southern Islands AMD has changed the kernel weights of their anisotropic filtering mechanism in order to further reduce shimmering of high frequency textures. The algorithm itself remains unchanged and as does performance, but image quality is otherwise improved. Admittedly these AF changes seem to be targeting increasingly esoteric scenarios – we haven’t seen any real game where the shimmering matches the tunnel test – but we’ll gladly take any IQ improvements we can get.
Since AMD’s latest changes are focused on reducing shimmering in motion we’ve put together a short video of the 3D Center Filter Tester running the tunnel test with the 7970, the 6970, and GTX 580. The tunnel test makes the differences between the 7970 and 6970 readily apparent, and at this point both the 7970 and GTX 580 have similarly low levels of shimmering.

While we’re on the subject of image quality, had you asked me two weeks ago what I was expecting with Southern Islands I would have put good money on new anti-aliasing modes. AMD and NVIDIA have traditionally kept parity with AA modes, with both implementing DX9 SSAA with the previous generation of GPUs, and AMD catching up to NVIDIA by implementing Enhanced Quality AA (their version of NVIDIA’s CSAA) with Cayman. Between Fermi and Cayman the only stark differences are that AMD offers their global faux-AA MLAA filter, while NVIDIA has support for true transparency and super sample anti-aliasing on DX10+ games.
Thus I had expected AMD to close the gap from their end with Southern Islands by implementing DX10+ versions of Adaptive AA and SSAA, but this has not come to pass. AMD has not implemented any new AA modes compared to Cayman, and as a result AAA and SSAA continue to only available in DX9 titles. And admittedly alpha-to-coverage support does diminish the need for these modes somewhat, but one only needs to fire up our favorite testing game, Crysis, to see the advantages these modes can bring even to DX10+ games. What’s more surprising is that it was AMD that brought AA IQ back to the forefront in the first place by officially adding SSAA, so to see them not continue that trend is surprising.
As a result for the time being there will continue to be an interesting division in image quality between AMD and NVIDIA. AMD still maintains an advantage with anisotropic filtering thanks to their angle-independent algorithm, but NVIDIA will have better anti-aliasing options in DX10+ games (ed: and Minecraft). It’s an unusual status quo that apparently will be maintained for quite some time to come.
Update: AMD has sent us a response in regard to our question about DX10+ SSAA
Basically the fact that most new game engines are moving to deferred rendering schemes (which are not directly compatible with hardware MSAA) has meant that a lot of attention is now being focused on shader-based AA techniques, like MLAA, FXAA, and many others. These techniques still tend to lag MSAA in terms of quality, but they can run very fast on modern hardware, and are improving continuously through rapid iteration. We are continuing work in this area ourselves, and we should have some exciting developments to talk about in the near future. But for now I would just say that there is a lot more we can still do to improve AA quality and performance using the hardware we already have.
Regarding AAA & SSAA, forcing these modes on in a general way for DX10+ games is problematic from a compatibility standpoint due to new API features that were not present in DX9. The preferred solution would be to have games implement these features natively, and we are currently investigating some new ways to encourage this going forward.
Finally, while AMD may be taking a break when it comes to anti-aliasing they’re still hard at work on tessellation. As we noted when discussing the Tahiti/GCN architecture AMD’s primitive pipeline is still part of their traditional fixed function pipeline, and just as with Cayman they have two geometry engines that can process up to two triangles per clock. On paper at least Tahiti doesn’t significantly improve AMD’s geometry performance, but as it turns out there’s a great deal you can do to improve geometry performance without throwing more geometry hardware at the task.
For Southern Islands AMD has implemented several techniques to boost the efficiency of their geometry engines. A larger parameter cache is a big part of this, but AMD has also increased vertex re-use and off-chip buffering. As such while theoretical geometry throughput is unchanged outside of the clockspeed differences between 7970 and 6970, AMD will be making better use of the capabilities of their existing geometry pipeline.
By AMD’s numbers these enhancements combined with the higher clockspeed of the 7970 versus the 6970 give it anywhere between a 1.7x and 4x improvement in tessellation performance. In our own tests the improvements aren’t quite as great, but they’re still impressive. Going by the DX11DetailTessellation sample program the 7970 has better performance than the GTX 580 at both normal and high tessellation factors (and particularly at high tessellation factors), while under Unigine Heaven – a tessellation-heavy synthetic benchmark – the 7970 leads the GTX 580 by over 20%. Or compared to the 6970 the difference is even more stark, with the 7970 leading the 6970 by about 55% in both of these benchmarks.
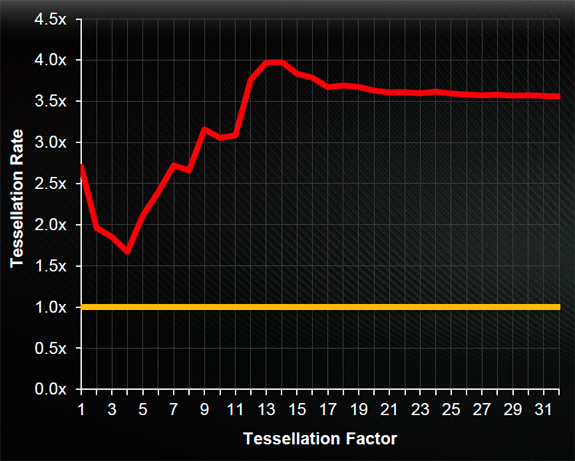
Of course both of these benchmarks are synthetic and real world performance can (and will) differ, but it does prove that AMD’s improvements in tessellation efficiency really do matter. Even though the GTX 580 can push up to 8 triangles/clock, it looks like AMD can achieve similar-to-better tessellation performance in many situations with their Southern Islands geometry pipeline at only 2 triangles/clock.
Though with that said, we’re still waiting to see the “killer app” for tessellation in order to see just how much tessellation is actually necessary. Current games (even BF3) are DX10 games with tessellation added as an extra instead of being a fundamental part of the rendering pipeline. There are a wide range of games from BF3 to HAWX 2 using tessellation to greatly different degrees and none of them really answer the question of how much tessellation is actually necessary. Both AMD and NVIDIA have made tessellation performance a big part of their marketing pushes, so there’s a serious question over whether games will be able to utilize that much geometry performance, or if AMD and NVIDIA are in another synthetic numbers war.








292 Comments
View All Comments
CeriseCogburn - Thursday, March 8, 2012 - link
Interesting, amd finally copied nvidia..." This problem forms the basis of this benchmark, and the NQueen test proves once more that AMD's Radeon HD 7970 tremendously benefits from leaving behind the VLIW architecture in complex workloads. Both the HD 7970 and the GTX 580 are nearly twice as fast as the older Radeons. "
When we show diversity we should also show that amd radeon has been massively crippled for a long time except when "simpleton" was the key to speed. "Superior architecture" actually means "simple and stupid" - hence "fast" at repeating simpleton nothings, but unable to handle "complex tasks".
LOL - the dumb gpu by amd has finally "evolved".
chizow - Thursday, December 22, 2011 - link
....unfortunately its going to be pitted against Kepler for the long haul.There's a lot to like about Southern Islands but I think its going to end up a very similar situation as Evergreen vs. Fermi, where Evergreen released sooner and took the early lead, but Fermi ultimately won the generation. I expect similar with Tahiti holding the lead for the next 3-6 months until Kepler arrives, but Kepler and its refresh parts winning this 28nm generation once they hit the streets.
Overall the performance and changes AMD made with Tahiti look great compared to Northern Islands, but compared to Fermi parts, its just far less impressive. If you already owned an AMD NI or Evergreen part, there'd be a lot of reason to upgrade, but if you own a Fermi generation Nvidia card there's just far less reason to, especially at the asking price.
I do like how AMD opened up the graphics pipeline with Tahiti though, 384-bit bus, 3GB framebuffer, although I wonder if holding steady with ROPs hurts them compared to Kepler. It would've also been interesting to see how the 3GB GTX 580 compared at 2560 since the 1.5GB model tended to struggle even against 2GB NI parts at that resolution.
ravisurdhar - Thursday, December 22, 2011 - link
My thoughts exactly. Can't wait to see what Kepler can do.Also...4+B transistors? mind=blown. I remember when we were ogling over 1B. Moore's law is crazy.... :D
johnpombrio - Wednesday, December 28, 2011 - link
Exactly. If you look at all the changes that AMD did on the card, I would have expected better results: the power consumption decrease with the Radeon 7970 is mainly due to the die shrink to 28nm. NVidia is planning on a die shrink of their existing Fermi architecture before Kepler is released:http://news.softpedia.com/news/Nvidia-Kepler-Is-On...
Another effect of the die shrink is that clock speed usually increases as there is less heat created at the lower voltage needed with a smaller transistor.
The third change that is not revolutionary is the bump of AMD's 7970's memory bus from 384 bits (matching the 580) from the 6970's 256 bits along with 3GB DDR5 memory vs the GTX580's 1.5GB and the 6970's 2GB.
The final non revolutionary change is bumping the number of stream processors by 33% from 1,536 to 2,048.
Again, breaking out my calculator, the 35% bump in the number of stream processors ALONE causes the increase in the change in the benchmark differences between the 7970 and the 6970.
The higher benchmark, however, does not show ANY OTHER large speed bumps that SHOULD HAVE OCCURED due to the increase in the memory bus size, the higher amount of memory, compute performance, texture fill rate, or finally the NEW ARCHITECTURE.
If I add up all the increases in the technology, I would have expected benchmarks in excess of 50-60% over the previous generation. Perhaps I am naive in how much to expect but, hell, a doubling of transistor count should have produced a lot more than a 35% increase. Add the new architecture, smaller die size, and more memory and I am underwhelmed.
CeriseCogburn - Thursday, March 8, 2012 - link
Well, we can wait for their 50%+ driver increase package+ hotfixes - because after reading that it appears they are missing the boat in drivers by a wide margin.Hopefully a few months after Kepler blows them away, and the amd fans finally allow themselves to complain to the proper authorities and not blame it on Nvida, they will finally come through with a "fix" like they did when the amd (lead site review mastas) fans FINALLY complained about crossfire scaling....
KaarlisK - Thursday, December 22, 2011 - link
What is the power consumption with multiple monitors? Previously, you could not downclock GDDR5, so the resulting consumption was horrible.Ryan Smith - Thursday, December 22, 2011 - link
"On that note, for anyone who is curious about idle clockspeeds and power consumption with multiple monitors, it has not changed relative to the 6970. When using a TMDS-type monitor along with any other monitor, AMD has to raise their idle clockspeeds from 350MHz core and 600Mhz memory to 350MHz core and the full 5.5GHz speed for memory, with the power penalty for that being around 30W. Matched timing monitors used exclusively over DisplayPort will continue to be the only way to be able to use multiple monitors without incurring an idle penalty."KaarlisK - Thursday, December 22, 2011 - link
Thank you for actually replying :)I am so sorry for having missed this.
ltcommanderdata - Thursday, December 22, 2011 - link
Great review.Here's hoping that AMD will implement 64-bit FP support across the whole GCN family and not just the top-end model. Seeing AMD's mobile GPUs don't use the highest-end chip, settling for the 2nd highest and lower, there hasn't been 64-bit FP support in AMD mobile GPUs since the Mobility HD4800 series. I'm interested in this because I can then dabble in some 64-bit GPGPU programming on the go. It also has implications for Apple since their iMacs stick to mobile GPUs, so would otherwise be stuck without 64-bit FP support which presumably could be useful for some of their professional apps.
In regards to hardware accelerated Megatexture, is it directly applicable to id Tech 5's OpenGL 3.2 solution? ie. Will id Tech 5 games see an immediate speed-up with no recoding needed? Or does Partially Resident Texture support require a custom AMD specific OpenGL extension? If it's the later, I can't see it going anywhere unless nVidia agrees to make it a multivendor EXT extension.
Ryan Smith - Thursday, December 22, 2011 - link
Games will need to be specifically coded for PRT; it won't benefit any current games. And you are correct in that it will require and AMD OpenGL extension to use (it won't be accessible from D3D at this time).