AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher: Graphics Core Next
One of the things we’ve seen as a result of the shift from pure graphics GPUs to mixed graphics and compute GPUs is how NVIDIA and AMD go about making their announcements and courting developers. With graphics GPUs there was no great need to discuss products or architectures ahead of time; a few choice developers would get engineering sample hardware a few months early, and everyone else would wait for the actual product launch. With the inclusion of compute capabilities however comes the need to approach launches in a different manner, a more CPU-like manner.
As a result both NVIDIA and AMD have begun revealing their architectures to developers roughly six months before the first products launch. This is very similar to how CPU launches are handled, where the basic principles of an architecture are publically disclosed months in advance. All of this is necessary as the compute (and specifically, HPC) development pipeline is far more focused on optimizing code around a specific architecture in order to maximize performance; whereas graphics development is still fairly abstracted by APIs, compute developers want to get down and dirty, and to do that they need to know as much about new architectures as possible as soon as possible.
It’s for these reasons that AMD announced Graphics Core Next, the fundamental architecture behind AMD’s new GPUs, back in June of this year at the AMD Fusion Developers Summit. There are some implementation and product specific details that we haven’t known until now, and of course very little was revealed about GCN’s graphics capabilities, but otherwise on the compute side AMD is delivering on exactly what they promised 6 months ago.
Since we’ve already covered the fundamentals of GCN in our GCN preview and the Radeon HD 7970 is primarily a gaming product we’re not going to go over GCN in depth here, but I’d encourage you to read our preview to fully understand the intricacies of GCN. But if you’re not interested in that, here’s a quick refresher on GCN with details pertinent to the 7970.
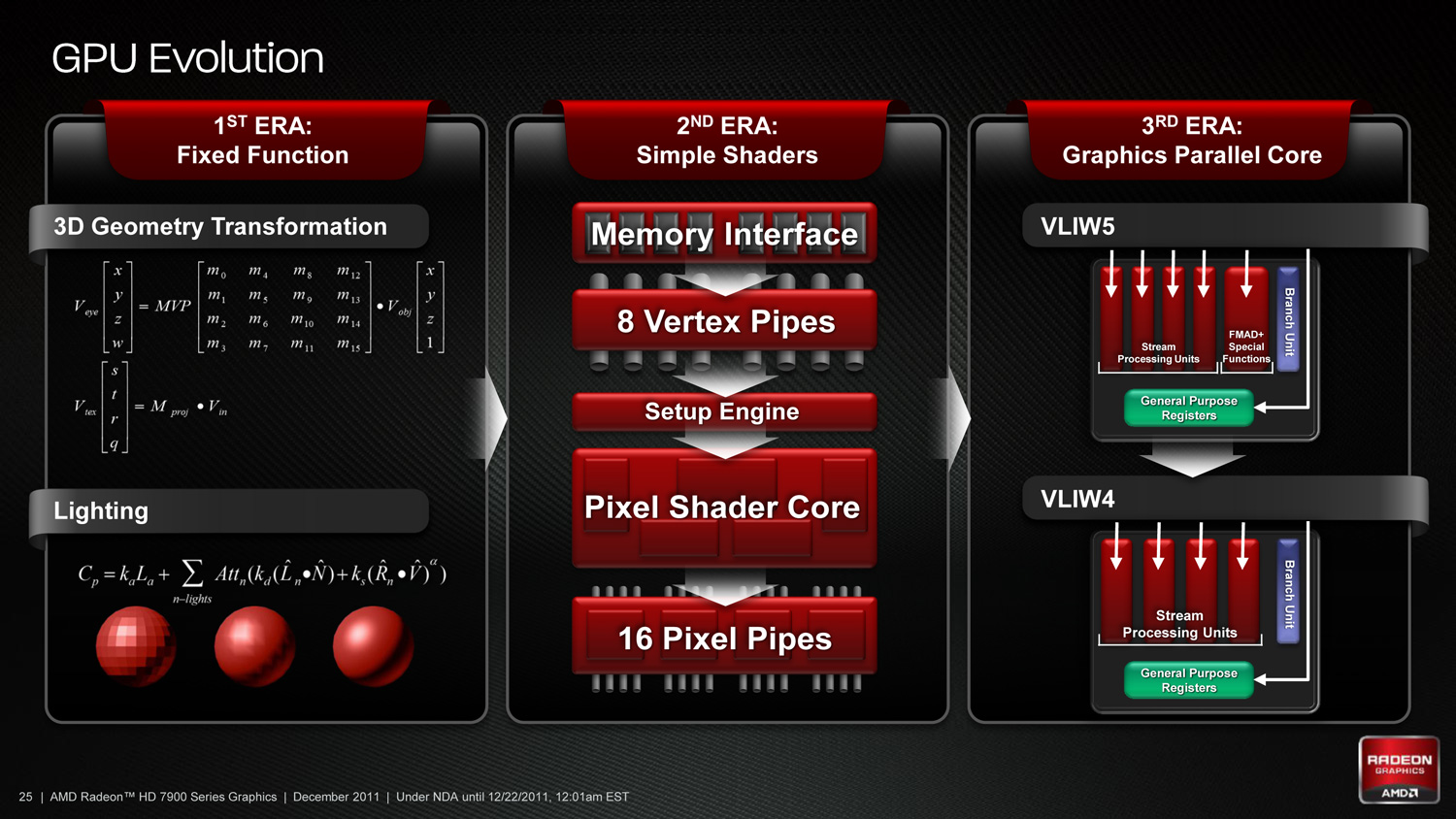
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
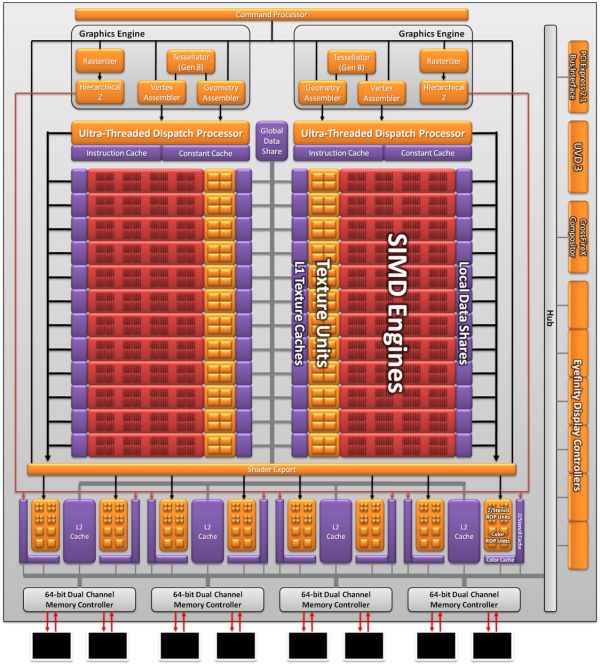
Cayman, A VLIW4 Design
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is the situation AMD faced.
But why does AMD want to chase compute in the first place when they already have a successful graphics GPU business? In the long term GCN plays a big part in AMD’s Fusion plans, but in the short term there’s a much simpler answer: because they have to.
In Q3’2011 NVIDIA’s Professional Solutions Business (Quadro + Tesla) had an operating income of 95M on 230M in revenue. Their (consumer) GPU business had an operating income of 146M, but on a much larger 644M in revenue. Professional products have much higher profit margins and it’s a growing business, particularly the GPU computing side. As it stands NVIDIA and AMD may have relatively equal shares of the discrete GPU market, but it’s NVIDIA that makes all the money. For AMD’s GPU business it’s no longer enough to focus only on graphics, they need a larger piece of the professional product market to survive and thrive in the future. And thus we have GCN.








292 Comments
View All Comments
mczak - Thursday, December 22, 2011 - link
Oh yes _for this test_ certainly 32 ROPs are sufficient (FWIW it uses FP16 render target with alpha blend). But these things have caches (which they'll never hit in the vantage fill test, but certainly not everything will have zero cache hits), and even more important than color output are the z tests ROPs are doing (which also consume bandwidth, but z buffers are highly compressed these days).You can't really say if 32 ROPs are sufficient, nor if they are somehow more efficient judged by this vantage test (as just about ANY card from nvidia or amd hits bandwidth constraints in that particular test long before hitting ROP limits).
Typically it would make sense to scale ROPs along with memory bandwidth, since even while it doesn't need to be as bad as in the color fill test they are indeed a major bandwidth eater. But apparently AMD disagreed and felt 32 ROPs are enough (well for compute that's certainly true...)
cactusdog - Thursday, December 22, 2011 - link
The card looks great, undisputed win for AMD. Fan noise is the only negative, I was hoping for better performance out the new gen cooler but theres always non-reference models for silent gaming.Temps are good too so theres probably room to turn the fan speed down a little.
rimscrimley - Thursday, December 22, 2011 - link
Terrific review. Very excited about the new test. I'm happy this card pushes the envelope, but doesn't make me regret my recent 580 purchase. As long as AMD is producing competitive cards -- and when the price settles on this to parity with the 580, this will be the market winner -- the technology benefits. Cheers!nerfed08 - Thursday, December 22, 2011 - link
Good read. By the way there is a typo in final words.faster and cooler al at once
Anand Lal Shimpi - Thursday, December 22, 2011 - link
Fixed, thank you :)Take care,
Anand
hechacker1 - Thursday, December 22, 2011 - link
I think most telling is the minimum FPS results. The 7970 is 30-45% ahead of the previous generation; in a "worse case" situation were the GPU can't keep up or the program is poorly coded.Of course they are catching up with Nvidia's already pretty good minimum FPS, but I am glad to see the improvement, because nothing is worse than stuttering during a fasted pace FPS. I can live with 60fps, or even 30fps, as long as it's consistent.
So I bet the micro-stutter problem will also be improved in SLI with this architecture.
jgarcows - Thursday, December 22, 2011 - link
While I know the bitcoin craze has died down, I would be interested to see it included in the compute benchmarks. In the past, AMD has consistently outperformed nVidia in bitcoin work, it would also be interesting to see Anandtech's take as to why, and to see if the new architecture changes that.dcollins - Thursday, December 22, 2011 - link
This architecture will most likely be a step backwards in terms of bitcoin mining performance. In the GCN architecture article, Anand mentioned that buteforce hashing was one area where a VLIW style architecture had an advantage over a SIMD based chip. Bitcoin mining is based on algorithms mathematically equivalent to password hashing. With GCN, AMD is changing the very thing that made their card better miners than Nvidia's chips.The old architecture is superior for "pure," mathematically well defined code while GCN is targeted at "messy," more practical and thus widely applicable code.
wifiwolf - Thursday, December 22, 2011 - link
a bit less than expected, but not really an issue:http://www.tomshardware.co.uk/radeon-hd-7970-bench...
dcollins - Thursday, December 22, 2011 - link
You're looking at a 5% increase in performance for a whole new generation with 35% more compute hardware, increased clock speed and increased power consumption: that's not an improvement, it's a regression. I don't fault AMD for this because Bitcoin mining is a very niche use case, but Crossfire 68x0 cards offer much better performance/watt and performance/$.